How to scrape live Crypto prices from WebSocket with Python?
But in this ocean of fanciful coins, how to find the meme coin that will propel you to the top?

In this tutorial, we will see how to scrape live prices of meme solana coins from DexScreener, using Python and WebSocket.
And automate this financial data export to a CSV file.
Let's make the dumbest decisions ever... based on data.
What is a WebSocket?
A WebSocket is a communication protocol which allows real-time two-way communication between two entities: a client (you) and a server (the site).
What's the difference with an HTTP connection?
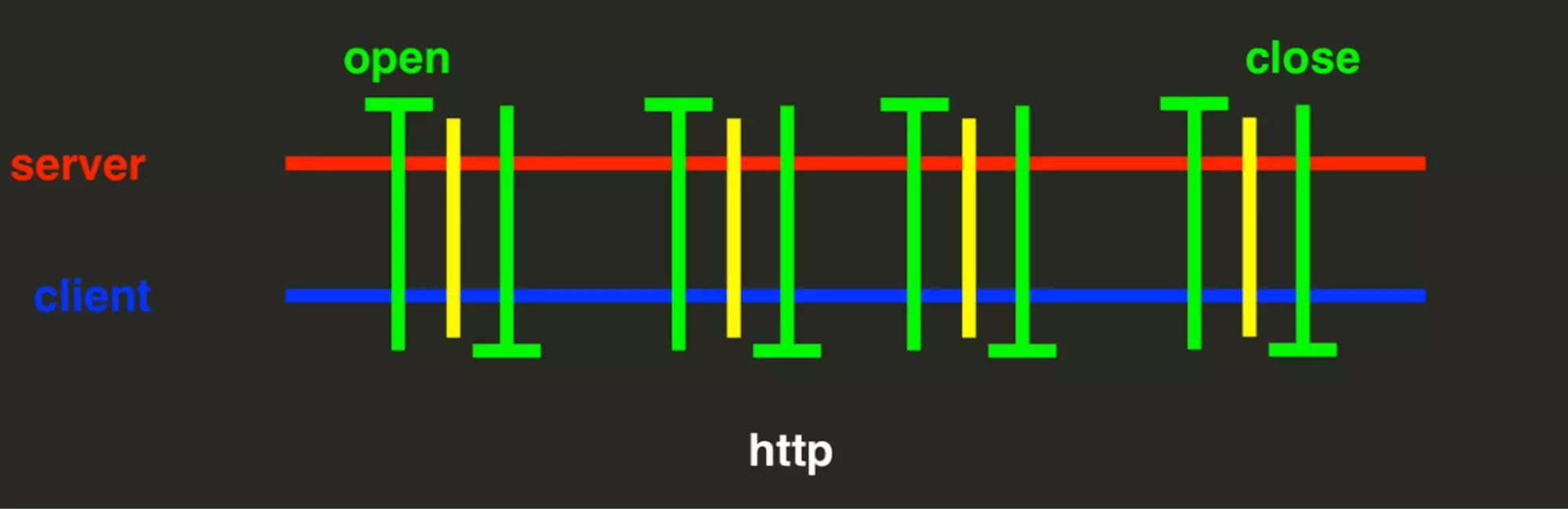
HTTP: request response model with a connection by exchange
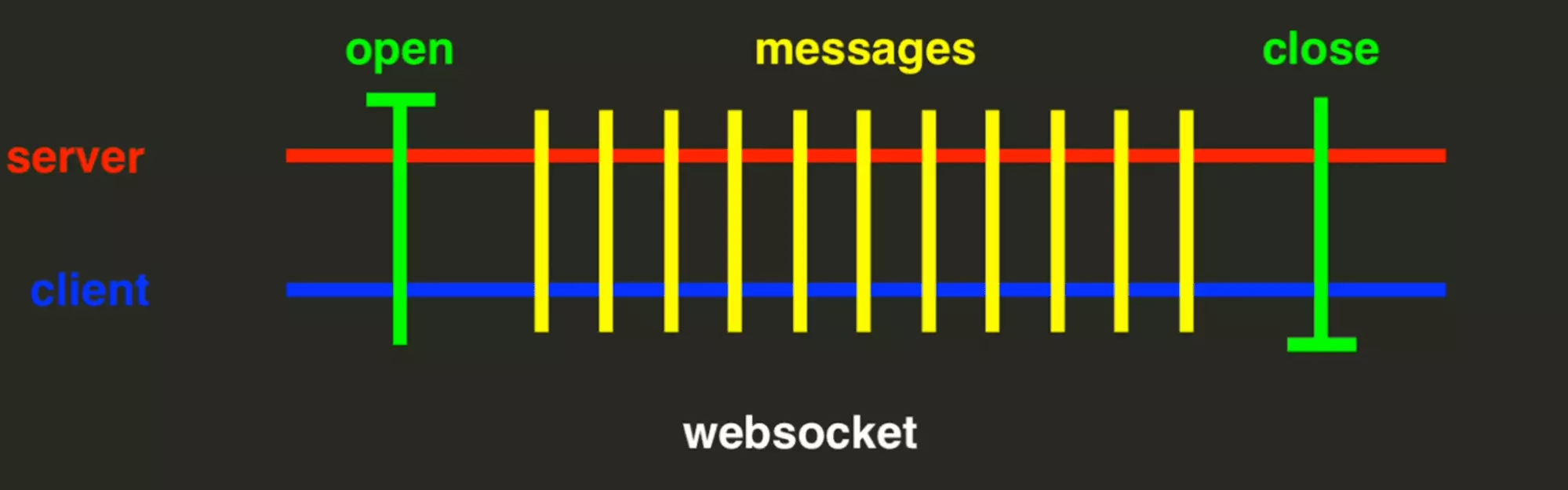
WebSocket: two-way communication persistent on a single connection
With the protocole HTTP, once the exchange is completed the connection is broken. This is a request-response model with a connection by exchange.
On the contrary, with WebSocket, the connection is never broken.
This allows instantaneous data exchange, particularly interesting when real time is required.

Websocket vs. HTTP requests
As said above, the Websocket allows rapid bidirectional exchange. We will therefore use it for everything that needs real-time data.
- Chat applications
- Online (sport) games
- Real-time stock tickers
Chat applications
Go to your Slack channel, and filter the requests by websocket: a single request appears.
With 1 message every 10 seconds.

Online (sport) games
Online betting has been booming for years.

Every second, the odds of all bets are transmitted.

Real-time stock tickers
Finally, we find this rapid bidirectional exchange technology in finance.
Here, in order to create powerful high-frequency trading tools, it is necessary to rely on data that can be manipulated on the scale of seconds.

With messages exchanged between the client and the server every second.
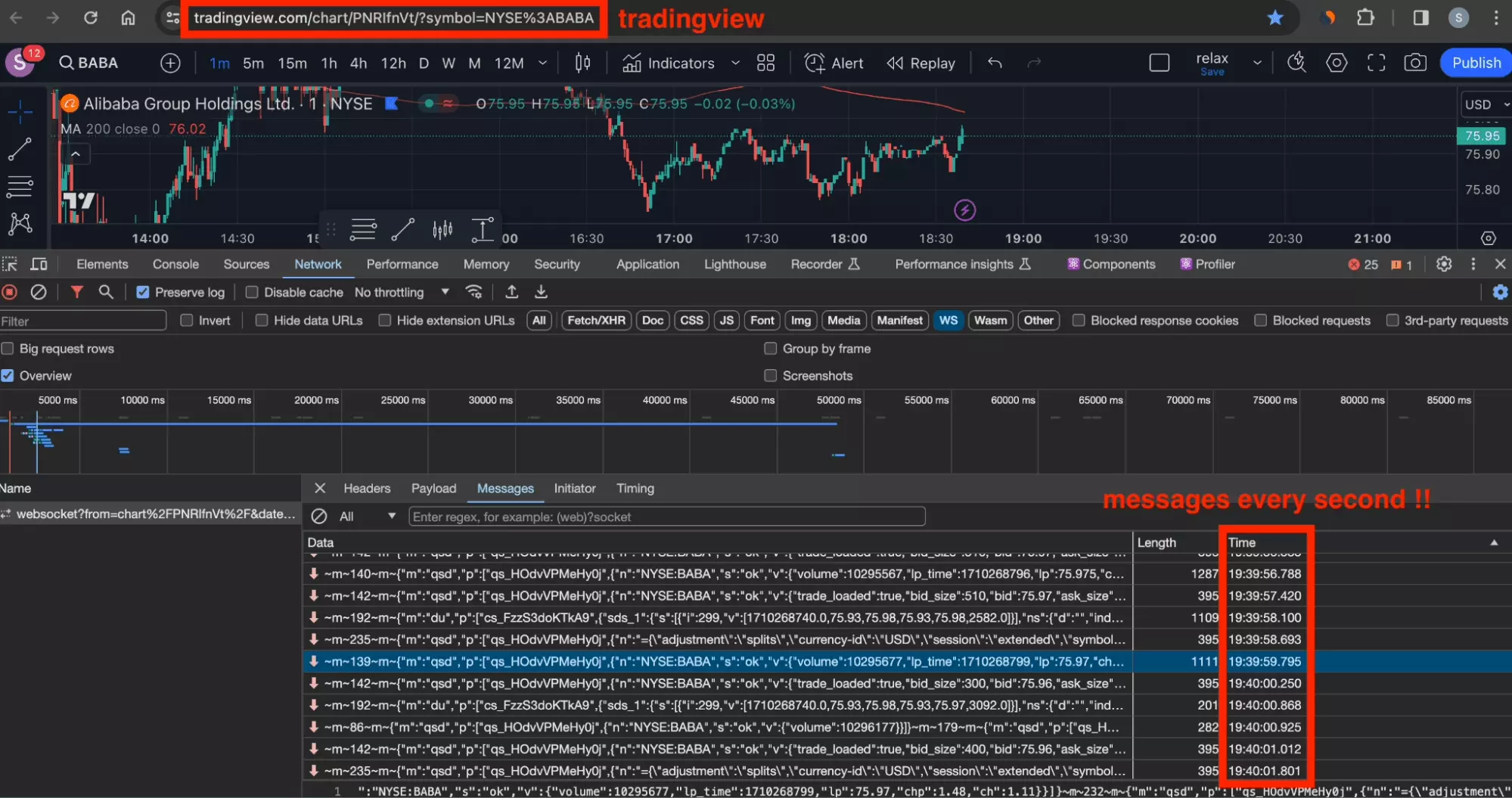
And we find the essential information for trading on the markets:
- ticker
- volume
- timestamp
- price
{ "m":"qsd", "p":[ "qs_HOdvVPMeHy0j", { "n":"NYSE:BABY", "s":"ok", "in":{ "volume":10295677, "lp_time":1710268799, "lp":75.97, "chp":1.48, "ch":1.11 } } ] }f
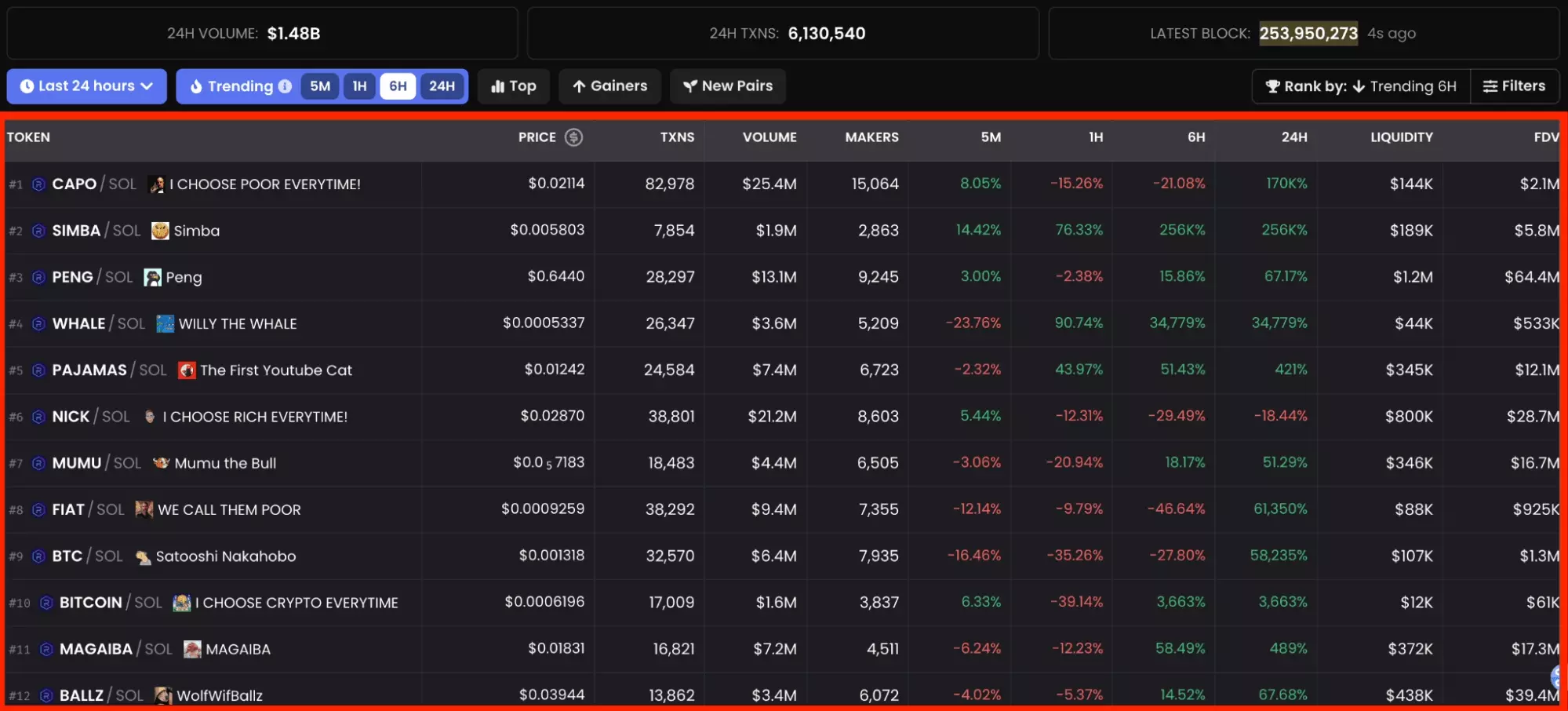
What data will we recover from DexScreener?
DexScreener is full of financial data everywhere: liquidity, website, volume etc…
As part of this tutorial, we will recover all financial data which are available from the h6 trending token list page on Solana:
- Pair name
- Token price
- Number of transactions
- Volume
- Makers
- Growth over 5m
- Growth over 1 hour
- Growth over 6 hours
- Growth over 24 hours
- Total liquidity
- Market Cap
- Token creation date
And accessible from this URL:
In addition, we will retrieve some social information:
- Presence of a Twitter
- Presence of a Telegram
- Presence of a token image
- Presence of a banner
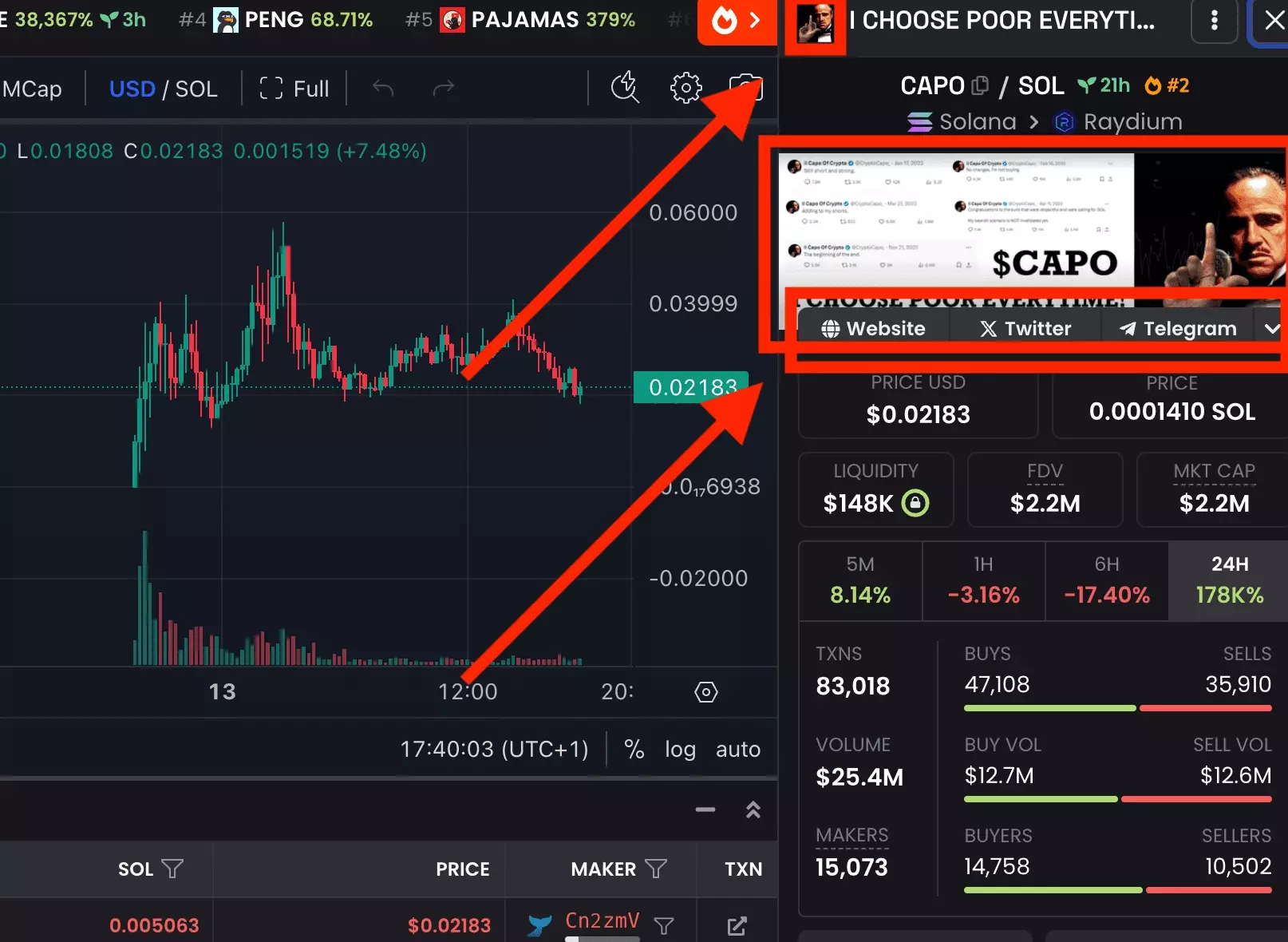
Be careful, we will simply retrieve the fact of knowing whether or not the peer has a social link, not the link itself. To do this you have to visit the token page, not done here.
And here, in JSON format, is what the data retrieved for each token looks like:
{ "chainId":"solana", "dexId":"raydium", "pairAddress":"3LktdenQLDMgUDCCYFa2HthfcfSZkSbH4HuS6GBGsUcy", "baseToken":{ "address":"JBkhsnrng7vSzh7H2LWA7FFEMjsqDNXuFfT3rUhsHgLb", "name":"RACE CAT", "symbol":"RCAT" }, "quoteToken":{ "address":"So11111111111111111111111111111111111111112", "name":"Wrapped SOL", "symbol":"SUN" }, "quoteTokenSymbol":"SUN", "price":"0.0006895", "priceUsd":"0.1082", "txns":{ "m5":{ "buys":69, "sells":30 }, "h1":{ "buys":1362, "sells":880 }, "h6":{ "buys":1362, "sells":880 }, "h24":{ "buys":1362, "sells":880 } }, "buyers":{ "m5":58, "h1":980, "h6":980, "h24":980 }, "sellers":{ "m5":24, "h1":606, "h6":606, "h24":606 }, "makers":{ "m5":82, "h1":1004, "h6":1004, "h24":1004 }, "volume":{ "m5":9872.42, "h1":276737.25, "h6":276737.25, "h24":276737.25 }, "volumeBuy":{ "m5":5170.53, "h1":143102.08, "h6":143102.08, "h24":143102.08 }, "volumeSell":{ "m5":4701.88, "h1":133635.17, "h6":133635.17, "h24":133635.17 }, "priceChange":{ "m5":9.09, "h1":2602, "h6":2602, "h24":2602 }, "liquidity":{ "usd":20808.89, "base":96169, "quote":66.2277 }, "marketCap":108258, "pairCreatedAt":1710345305000, "ear":true, "profile":{ "ear":true, "website":true, "twitter":true, "linkCount":3, "imgKey":"8181ca" }, "c":"a", "a":"solamm" }f
It's well structured, it's complete, and with the WebSocket, we're going to scrape that with pretty high frequency.
Why scrape data from DexScreener with Python?
All this data… what for?
We identified 3 convincing use cases, specific to cryptocurrency and finance market:
- Build sell/buy alert
- Build a predictive tracker
- Build trading bots
Build sell/buy alert
In both situations, DexScreener data will allow you to generate an alert from the token price.

Don't let yourself be surprised anymore.
Build a predictive tracker
If only it were possible, from the quantitative values of the first 3 candles, to predict the growth... the explosion of the token...
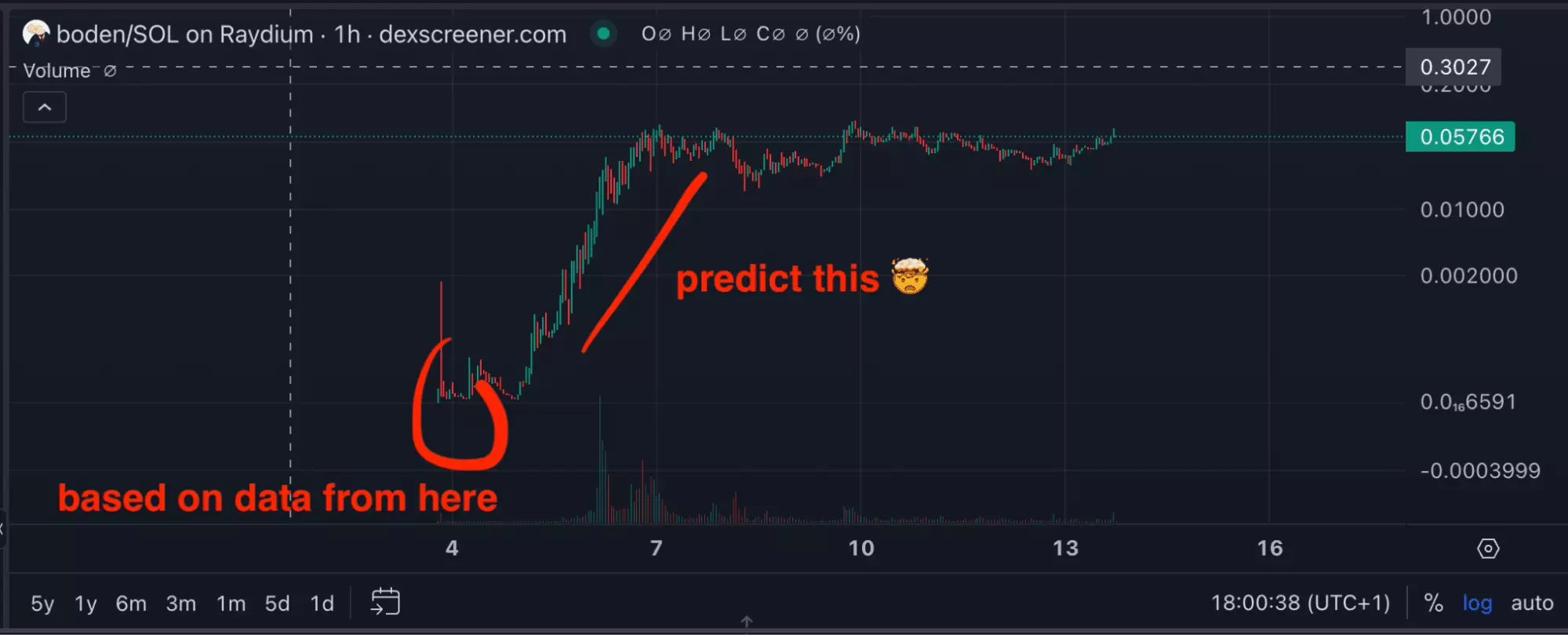
With all this data, you will be able to generate a list of criteria yourself in order to designate the winning pair.
For example:
- Large volume of transactions in 15 minutes
- Number of holders
- Number of transactions

Build trading bots
Buy automatically when it goes up or a certain threshold of transactions has been crossed... and do the same thing on the downside to make profits effortlessly.
Too good to be true?
However, this is what this very recent guide from QuickNode, published on 02/09/2024, offers:
Create a Solana Trading Bot Using Jupiter API.
You will be able to offer your trading robot this precious data, and build a high frequency trading tool… homemade.
If you want to go further without reading tons of docs, we recommend this very good video from MoonDev:
i coded a solana sniper python trading bot for you
Be careful, as they say realistically in the USA, there is no free lunch.
There is little doubt, however, that with the bull run coming, you will be able to make profits. It’s (almost) promised.
Is it legal to scrape data from a Crypto DEX?
And even if he did, all this data is public data, accessible to everyone from the data of the chain.
This is the whole principle of blockchain.
A publicly accessible and shared transactions database.
And in the United States in particular, it is completely legal to scrape public data.

Complete Code
The complete code is accessible right here, and can be downloaded in full directly from the GitHub Gist here:
dexscreenertrendingsolanapairswebsocket_scraper.py.
# ============================================================================= # Title: DexScreener Crypto Live Prices Scraper # Description: This script scrape the first 200 h6 trending Solana pairs from DexScreener -- every 10 seconds # Author: Sasha Bouloudnine # Date: 2024-03-13 # # Usage: # - Install websocket using `pip install websockets`. # - Launch the script. # # ============================================================================= import asyncio import websockets from datetime import datetime import you import base64 import json import csv import time def generate_sec_websocket_key(): random_bytes = os.urandom(16) key = base64.b64encode(random_bytes).decode('utf-8') return key TYPES = ['pairs', 'latestBlock'] DATA = [] FIELDNAMES = [ "chain_id", "dex_id", "pair_address", "token_address", "token_name", "token_symbol", "token_m5_buys", "token_m5_sells", "token_h1_buys", "token_h1_sells", "token_h1_to_m5_buys", "token_liquidity", "token_market_cap", "token_created_at", "token_created_since", "token_eti", "token_header", "token_website", "token_twitter", "token_links", "token_img_key", "token_price_usd", "token_price_change_h24", "token_price_change_h6", "token_price_change_h1", "token_price_change_m5" ] async def dexscreener_scraper(): headers = { "Host": "io.dexscreener.com", "Connection": "Upgrade", "Pragma": "no-cache", "Cache-Control": "no-cache", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36", "Upgrade": "websocket", "Origin": "https://dexscreener.com", "Sec-WebSocket-Version": 13, "Accept-Encoding": "gzip, deflate, br, zstd", "Accept-Language": "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7", "Sec-WebSocket-Key": generate_sec_websocket_key() } type ="wss://io.dexscreener.com/dex/screener/pairs/h24/1?rankBy[key]=trendingScoreH6&rankBy[order]=desc" async with websockets.connect(uri, extra_headers=headers) as websocket: while True: message_raw = await websocket.recv() message = json.loads(message_raw) _type = message["type"] assert _type in TYPES if _type == 'pairs': pairs = message["pairs"] assert pairs for pair in pairs: chain_id = pair["chainId"] dex_id = pair["dexId"] pair_address = pair["pairAddress"] assert pair_address token_address = pair["baseToken"]["address"] token_name = pair["baseToken"]["name"] token_symbol = pair["baseToken"]["symbol"] token_txns = pair["thx"] token_m5_buys = token_txns["m5"]["buys"] token_m5_sells = token_txns["m5"]["sells"] token_h1_buys = token_txns["h1"]["buys"] token_h1_sells = token_txns["h1"]["sells"] token_h1_to_m5_buys = round(token_m5_buys*12/token_h1_buys, 2) if token_m5_buys else None token_liquidity = pair["liquidity"]["usd"] token_market_cap = pair["marketCap"] token_created_at_raw = pair["pairCreatedAt"] token_created_at = token_created_at_raw / 1000 token_created_at = datetime.utcfromtimestamp(token_created_at) now_utc = datetime.utcnow() token_created_since = round((now_utc - token_created_at).total_seconds() / 60, 2) token_eti = pair.get("ear", False) token_header = pair.get("profile", {}).get("header", False) token_website = pair.get("profile", {}).get("website", False) token_twitter = pair.get("profile", {}).get("twitter", False) token_links = pair.get("profile", {}).get("linkCount", False) token_img_key = pair.get("profile", {}).get("imgKey", False) token_price_usd = pair["priceUsd"] token_price_change_h24 = pair["priceChange"]["h24"] token_price_change_h6 = pair["priceChange"]["h6"] token_price_change_h1 = pair["priceChange"]["h1"] token_price_change_m5 = pair["priceChange"]["m5"] VALUES = [ chain_id, dex_id, pair_address, token_address, token_name, token_symbol, token_m5_buys, token_m5_sells, token_h1_buys, token_h1_sells, token_h1_to_m5_buys, token_liquidity, token_market_cap, token_created_at, token_created_since, token_eti, token_header, token_website, token_twitter, token_links, token_img_key, token_price_usd, token_price_change_h24, token_price_change_h6, token_price_change_h1, token_price_change_m5 ] print(token_name, token_price_usd) row = dict(zip(FIELDNAMES, VALUES)) DATA.append(row) file_created_at = int(time.time()) filename = 'dexscreener_%s.csv' % file_created_at with open(filename, 'In') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES, delimiter='\t') writer.writeheader() for row in DATA: writer.writerow(row) print('done %s' % filename) print('pause 10s :°') time.sleep(10) if __name__ == "__main__": asyncio.run(dexscreener_scraper())f
Prerequisites
Before launching it, just install the Python library websockets with the pip library installation tool.
This library allows you to exchange messages via the WebSocket protocol with Python.
$ pip install websocketsf
How it works?
First, go to GitHub and download the script, or copy and paste the contents of the script into a Python file.

Then, open your console, and launch the script with the command below.
$ python3 dexscreener_trending_solana_pairs_websocket_scraper.py PayPaw 0.001496 SolPets 0.02063 Lion 0.003831 ate boden 0.1267 doland tremp 0.4682 Peng 0.7786 I CHOOSE POOR EVERYTIME! 0.01417 I CHOOSE RICH EVERYTIME! 0.03966 ... VANRY 0.3481 ZynCoin 0.1241 SolCard 0.04757 done dexscreener_1710028163000.csv pause 10s :°f
The script will perform the following actions:
- Open connection with DexScreener WebSocket client
- Retrieve data from 200 Solana trending h6 coins
- Save this as a CSV file
Every 10 seconds.
Powerful.
🦅
Step by step tutorial
The code is there but…how does it work?
This is what we will see in this complete tutorial, which we will carry out in 4 distinct stages:
- Identify the websocket endpoint
- Adding the while loop
- Parse the data
- Export to CSV
Identify the websocket endpoint
Internet browsing is based on the concept of query: it materializes an exchange between a client (the browser) and a server (the site).
The exchange can be summarized as follows:
- The browser (client) arrives on the site
- A request is sent
- The site (server) returns a response
- The browser (client) displays web page

In our case, where is the WebSocket request located?
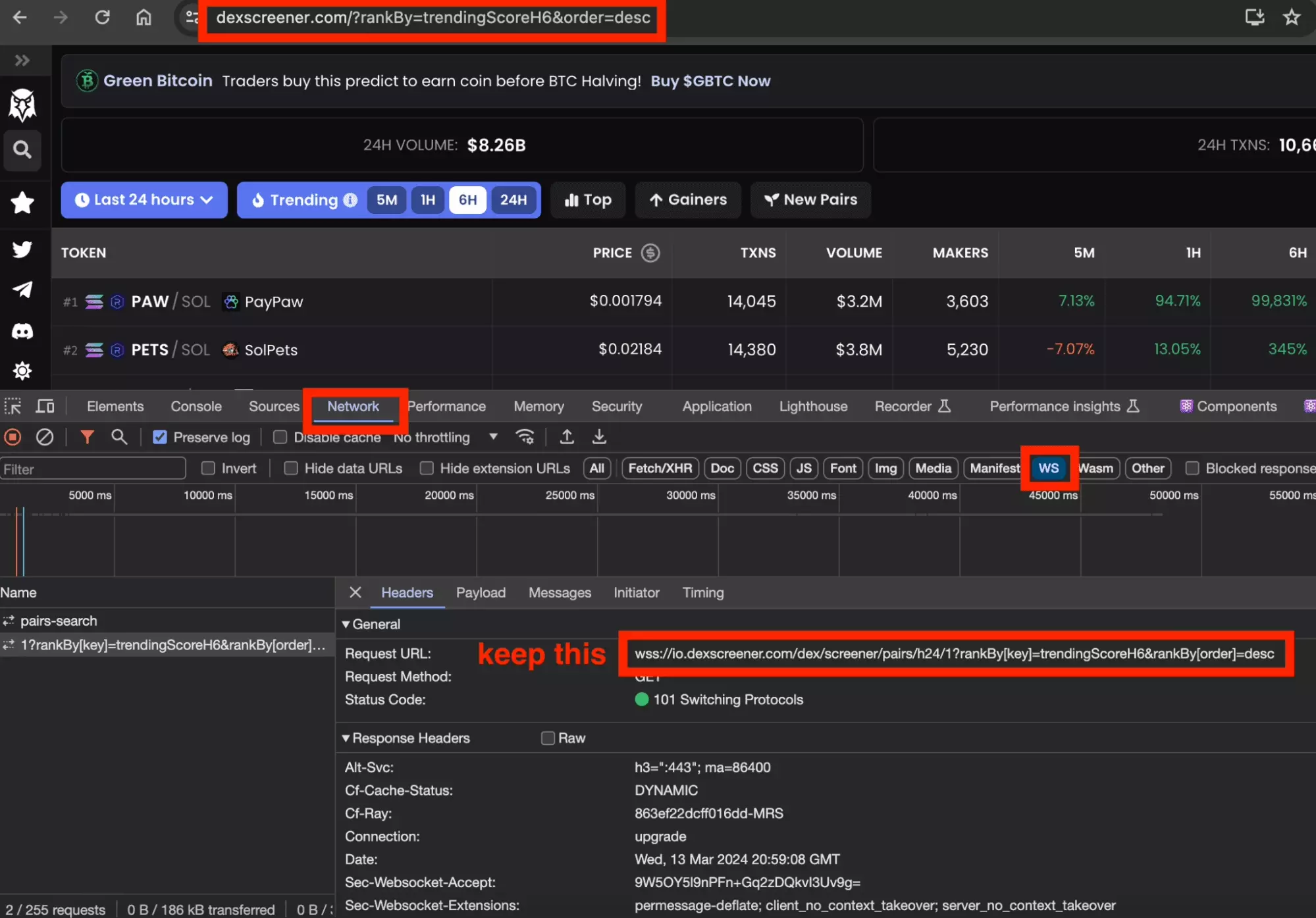
To do this, you must go to DexScreener, then:
- Open Chrome Inspection Tool
- Go to the tab Network
- Filter by WS, short for WebSocket
- Refresh
- Retrieve the valuable query URL
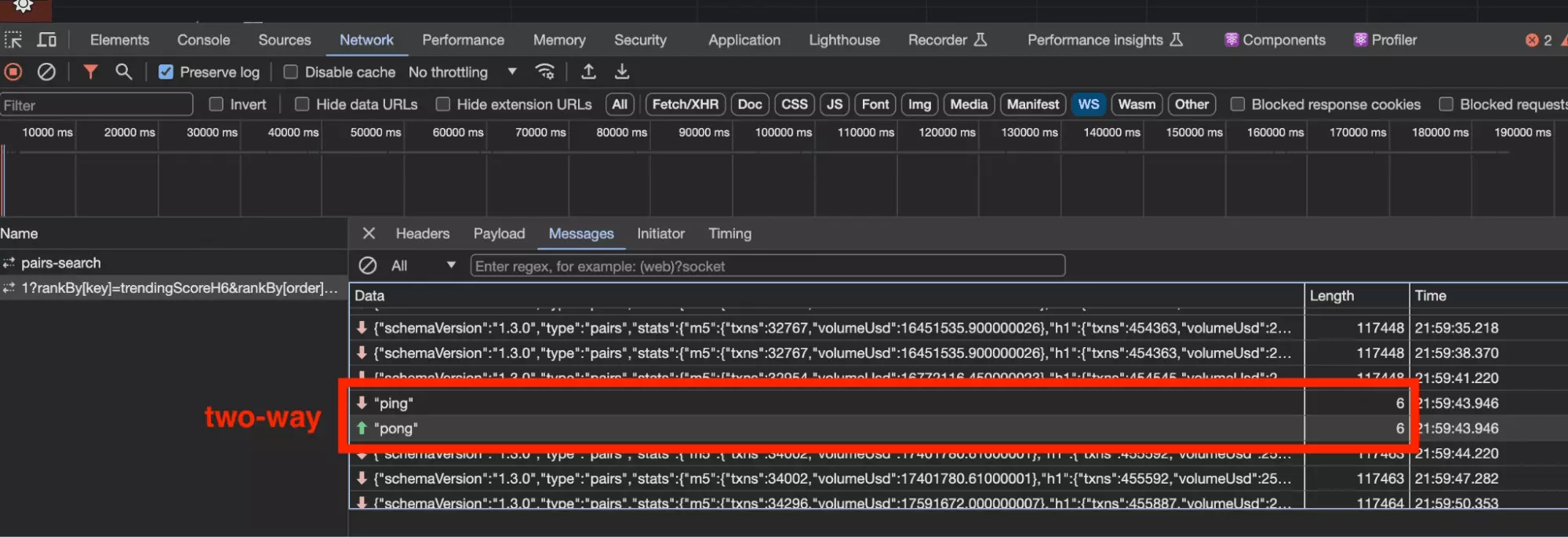
Note that in the part Messages, we find expected bi-directional messages exchanged between the site (server) and the browser (client).
Notably the absolutely intuitive: ping > pong.
But now how to reproduce these exchanges with Python?
We will start with Copy as cURL, to retrieve the value of the URL, as well as the headers of the request.
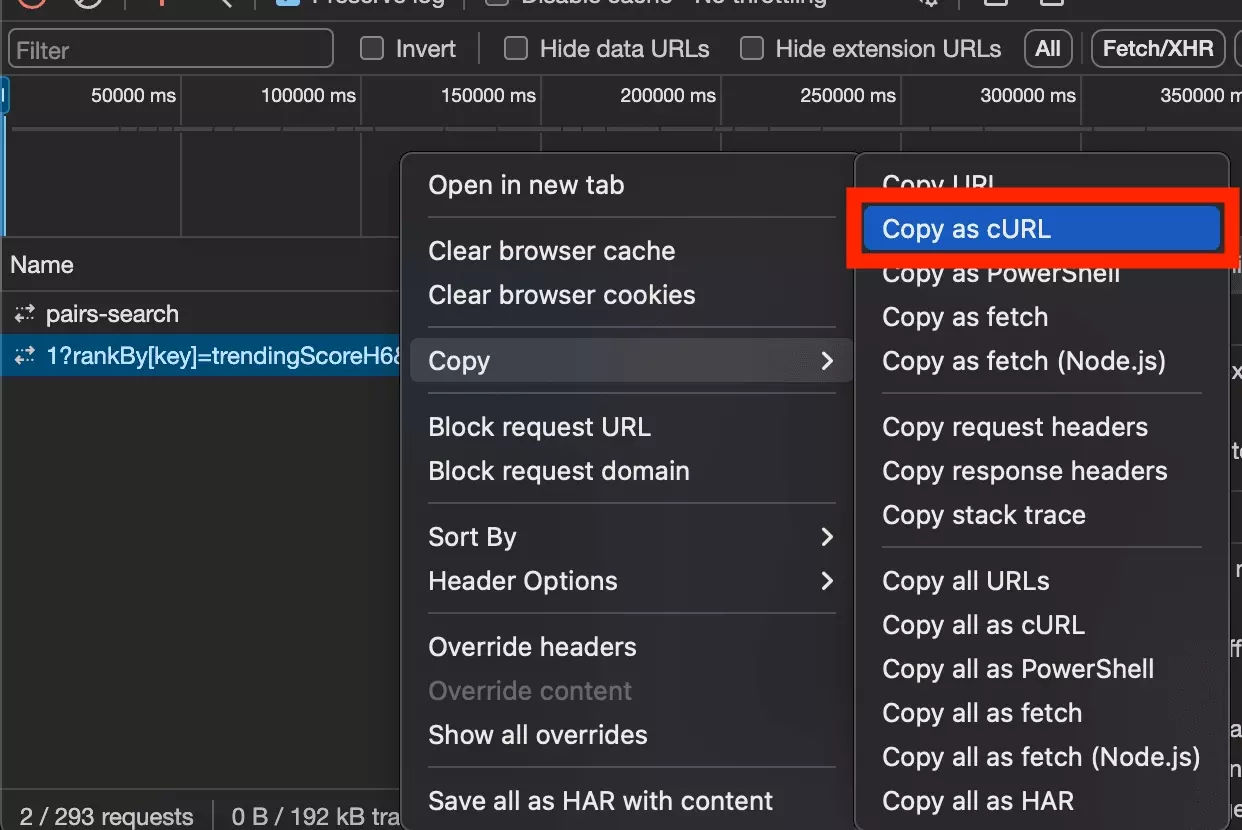
Finally, we will replace the part requests, with the syntax of the library websockets.
import asyncio import websockets import json async def dexscreener_scraper(): headers = { "Host": "io.dexscreener.com", "Connection": "Upgrade", "Pragma": "no-cache", "Cache-Control": "no-cache", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36", "Upgrade": "websocket", "Origin": "https://dexscreener.com", "Sec-WebSocket-Version": 13, "Accept-Encoding": "gzip, deflate, br, zstd", "Accept-Language": "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7" } type ="wss://io.dexscreener.com/dex/screener/pairs/h24/1?rankBy[key]=trendingScoreH6&rankBy[order]=desc" async with websockets.connect(uri, extra_headers=headers) as websocket: message_raw = await websocket.recv() message = json.loads(message_raw) print(message) if __name__ == '__main__': asyncio.run(dexscreener_scraper())f
We start the machine and… eureka!
A long JSON appears, with the list of pairs, and for each pair the following metrics:
{ "schemaVersion":"1.3.0", "type":"pairs", "stats":{ "m5":{ "txn":36900, "volumeUsd":15302890.229999958 }, "h1":{ "txn":469943, "volumeUsd":240360254.3900005 }, "h6":{ "txn":2888366, "volumeUsd":1731720375.3599985 }, "h24":{ "txn":10680606, "volumeUsd":8217607027.990008 } }, "pairs":[ { "chainId":"solana", "dexId":"raydium", "pairAddress":"77JrcxAzPUEvn9o1YXmFm9zQid8etT4SCWVxVqE8VTTG", "baseToken":{ "address":"8wzYfqeqkjBwYBHMacBVen8tSuJqXiDtsCgmjnUJDSKM", "name":"PORTNOY", "symbol":"PORTNOY" }, "quoteToken":{ "address":"So11111111111111111111111111111111111111112", "name":"Wrapped SOL", "symbol":"SUN" }, "quoteTokenSymbol":"SUN", "price":"0.00003781", "priceUsd":"0.006096", "txns":{ "m5":{ "buys":790, "sells":496 }, "h1":{ "buys":5207, "sells":3570 ... }f
But as we saw in the screenshot of the Messages, a WebSocket connection means dozens of messages exchanged, sometimes every second.
Not just a JSON.
How to ensure a continuous flow of messages?
Adding the while loop
To ensure that the connection does not close after the first message received, we will simply add a while loop.
To avoid saturating the target site, we will also add a 10 second pause between each message.
import asyncio import websockets import json import time async def dexscreener_scraper(): ... async with websockets.connect(uri, extra_headers=headers) as websocket: while True: message_raw = await websocket.recv() message = json.loads(message_raw) print(message) print('pause 10s :°') time.sleep(10) if __name__ == '__main__': asyncio.run(dexscreener_scraper())f
So the code will work as follows:
- Open connection with async
- Enter the while loop
- Receive messages
- Take a 10-second break
- Start again
Now, we're going to sort through all this gargantuan flood of information.
Data parsing
We end up with a big JSON, with 4 primary keys:
- schemaVersion the schema type concerned
- type the type of message received
- stats general market statistics
- peers transaction information about our peers
- pairsCount the total number of peers listed on the dex

For each peer, an exhaustive JSON, which looks like this:
{ "chainId":"solana", "dexId":"raydium", "pairAddress":"6UYbX1x8YUcFj8YstPYiZByG7uQzAq2s46ZWphUMkjg5", "baseToken":{ "address":"3psH1Mj1f7yUfaD5gh6Zj7epE8hhrMkMETgv5TshQA4o", "name":"ate boden", "symbol":"floor" }, "quoteToken":{ "address":"So11111111111111111111111111111111111111112", "name":"Wrapped SOL", "symbol":"SUN" }, "quoteTokenSymbol":"SUN", "price":"0.0008552", "priceUsd":"0.1378", "txns":{ "m5":{ "buys":100, "sells":104 }, "h1":{ "buys":1381, "sells":1322 }, "h6":{ "buys":8599, "sells":8314 }, "h24":{ "buys":12408, "sells":12022 } }, "buyers":{ "m5":67, "h1":604, "h6":3190, "h24":4071 }, "sellers":{ "m5":70, "h1":599, "h6":2687, "h24":3525 }, "makers":{ "m5":125, "h1":1085, "h6":5134, "h24":6497 }, "volume":{ "m5":146154.45, "h1":1493348.38, "h6":11015417, "h24":13119735.64 }, "volumeBuy":{ "m5":66601.88, "h1":762583.78, "h6":5633787.49, "h24":6704894.52 }, "volumeSell":{ "m5":79552.56, "h1":730764.59, "h6":5381629.51, "h24":6414841.12 }, "priceChange":{ "m5":-3.45, "h1":10.76, "h6":175, "h24":255 }, "liquidity":{ "usd":1264268.15, "base":4577916, "quote":3926.1037 }, "marketCap":95193189, "pairCreatedAt":1709490601000, "ear":true, "profile":{ "ear":true, "website":true, "twitter":true, "linkCount":3, "imgKey":"d7e9ac" }, "c":"a", "a":"solamm" }f
We will now parse all the following attributes:
FIELDNAMES = [ "chain_id", "dex_id", "pair_address", "token_address", "token_name", "token_symbol", "token_m5_buys", "token_m5_sells", "token_h1_buys", "token_h1_sells", "token_h1_to_m5_buys", "token_liquidity", "token_market_cap", "token_created_at", "token_created_since", "token_eti", "token_header", "token_website", "token_twitter", "token_links", "token_img_key", "token_price_usd", "token_price_change_h24", "token_price_change_h6", "token_price_change_h1", "token_price_change_m5" ]f
With the following code for this second step.
import asyncio import websockets import json import time from datetime import datetime DATA = [] FIELDNAMES = [ "chain_id", "dex_id", "pair_address", "token_address", "token_name", "token_symbol", "token_m5_buys", "token_m5_sells", "token_h1_buys", "token_h1_sells", "token_h1_to_m5_buys", "token_liquidity", "token_market_cap", "token_created_at", "token_created_since", "token_eti", "token_header", "token_website", "token_twitter", "token_links", "token_img_key", "token_price_usd", "token_price_change_h24", "token_price_change_h6", "token_price_change_h1", "token_price_change_m5" ] async def dexscreener_scraper(): headers = { "Host": "io.dexscreener.com", "Connection": "Upgrade", "Pragma": "no-cache", "Cache-Control": "no-cache", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36", "Upgrade": "websocket", "Origin": "https://dexscreener.com", "Sec-WebSocket-Version": 13, "Accept-Encoding": "gzip, deflate, br, zstd", "Accept-Language": "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7" } type ="wss://io.dexscreener.com/dex/screener/pairs/h24/1?rankBy[key]=trendingScoreH6&rankBy[order]=desc" async with websockets.connect(uri, extra_headers=headers) as websocket: while True: message_raw = await websocket.recv() message = json.loads(message_raw) pairs = message["pairs"] assert pairs for pair in pairs: chain_id = pair["chainId"] dex_id = pair["dexId"] pair_address = pair["pairAddress"] assert pair_address token_address = pair["baseToken"]["address"] token_name = pair["baseToken"]["name"] token_symbol = pair["baseToken"]["symbol"] token_txns = pair["thx"] token_m5_buys = token_txns["m5"]["buys"] token_m5_sells = token_txns["m5"]["sells"] token_h1_buys = token_txns["h1"]["buys"] token_h1_sells = token_txns["h1"]["sells"] token_h1_to_m5_buys = round(token_m5_buys*12/token_h1_buys, 2) if token_m5_buys else None token_liquidity = pair["liquidity"]["usd"] token_market_cap = pair["marketCap"] token_created_at_raw = pair["pairCreatedAt"] token_created_at = token_created_at_raw / 1000 token_created_at = datetime.utcfromtimestamp(token_created_at) now_utc = datetime.utcnow() token_created_since = round((now_utc - token_created_at).total_seconds() / 60, 2) token_eti = pair.get("ear", False) token_header = pair.get("profile", {}).get("header", False) token_website = pair.get("profile", {}).get("website", False) token_twitter = pair.get("profile", {}).get("twitter", False) token_links = pair.get("profile", {}).get("linkCount", False) token_img_key = pair.get("profile", {}).get("imgKey", False) token_price_usd = pair["priceUsd"] token_price_change_h24 = pair["priceChange"]["h24"] token_price_change_h6 = pair["priceChange"]["h6"] token_price_change_h1 = pair["priceChange"]["h1"] token_price_change_m5 = pair["priceChange"]["m5"] VALUES = [ chain_id, dex_id, pair_address, token_address, token_name, token_symbol, token_m5_buys, token_m5_sells, token_h1_buys, token_h1_sells, token_h1_to_m5_buys, token_liquidity, token_market_cap, token_created_at, token_created_since, token_eti, token_header, token_website, token_twitter, token_links, token_img_key, token_price_usd, token_price_change_h24, token_price_change_h6, token_price_change_h1, token_price_change_m5 ] print(token_name, token_price_usd) row = dict(zip(FIELDNAMES, VALUES)) DATA.append(row) print('pause 10s :°') time.sleep(10) if __name__ == '__main__': asyncio.run(dexscreener_scraper())f
Everything is in order!
We will finish this tutorial by exporting this data in CSV format.
Export to CSV file
Last step, because it gives greater overall readability, and it is simpler to process, we will export it all to CSV format.
writer = csv.DictWriter(f, fieldnames=FIELDNAMES, delimiter='\t')f
Furthermore, we will save 200 lines every 10 seconds. How do I know when this backup took place?
We will add the collection timestamp to the name of each file.
file_created_at = int(time.time()) filename = 'dexscreener_%s.csv' % file_created_atf
And the complete code… is available on the Gist, right there:
You can now launch the scraper, and… tada, all the data is instantly scraped, every 10 seconds, in an exhaustive, readable and structured file.
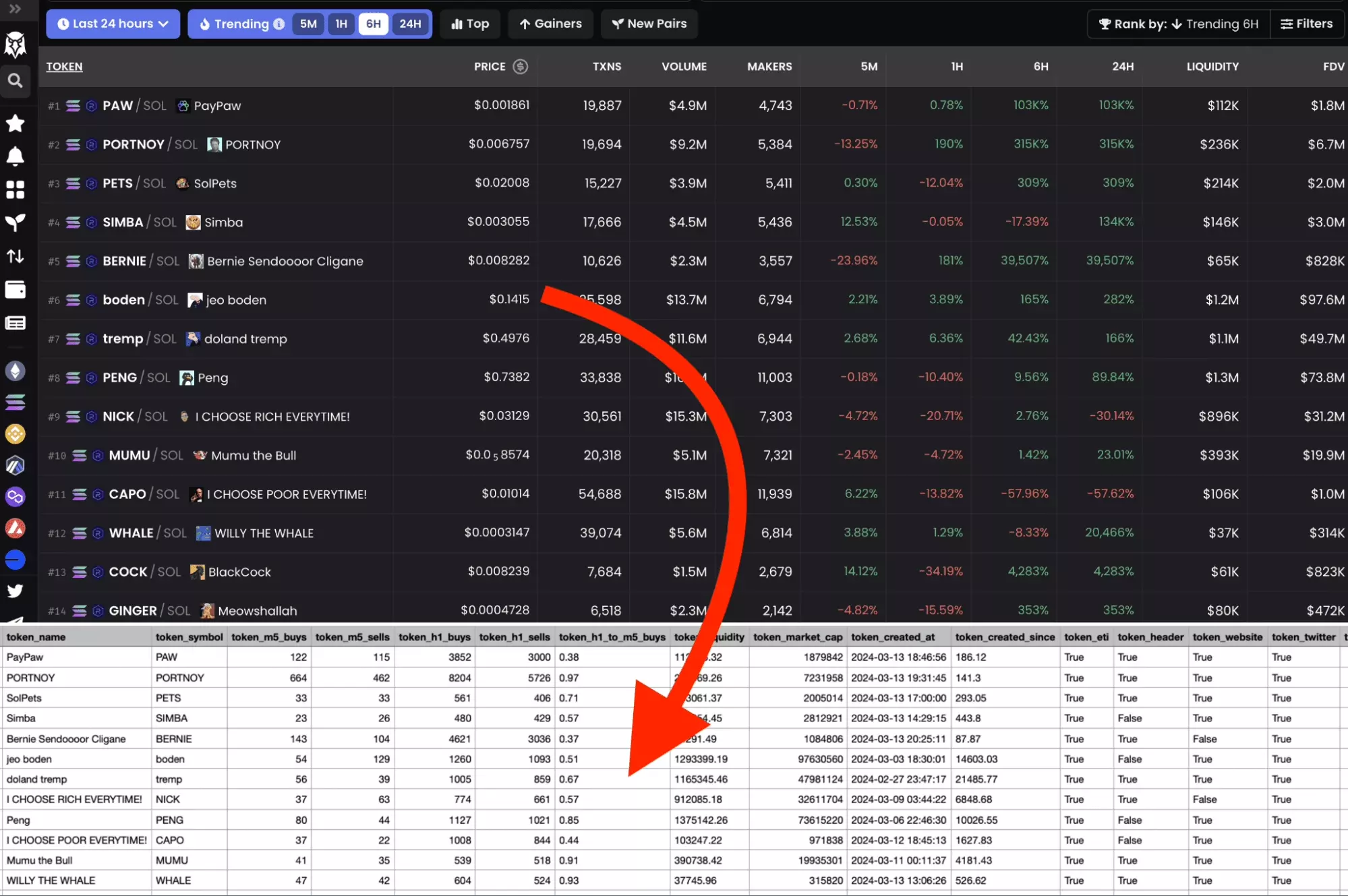
FAQ
Which programming language is most used for WebSocket scraping?
While browsing the web, we saw that 3 options emerged here and there:
- Python
- Go
- JavaScript
However, based on popularity, the answer is obvious.

How to deal with so many DexScreener CSV files?
With 1 CSV file created every 10 seconds, you'll soon find yourself with a mountain of files to process.
How to prevent file inflation?
Export data to a large-scale structured SQL database.
With 3 simple advantages:
- Size under control
- Easy query processing
- Thread-safe
SQL Easy's How to Use SQL in Python: A Comprehensive Guide is the perfect place to start.

Is there a DexScreener no-code web scraper?
No, not for the moment.
But if you are interested in the project, you can give us strength here! and add an upvote to speed up the development of the scraping tool:

Is it possible to scrape meme coin information from Twitter?
A meme coin obviously involves quantitative elements: number of transactions, liquidity, market cap, etc.
But it also relies on a strong community: the hodlers. Whose fidelity and size can also be measured quantitatively.
- Name of tweets
- Name of followers
- Number of views or likes per tweet …
This is what each coin highlights DexScreener, in the info section.
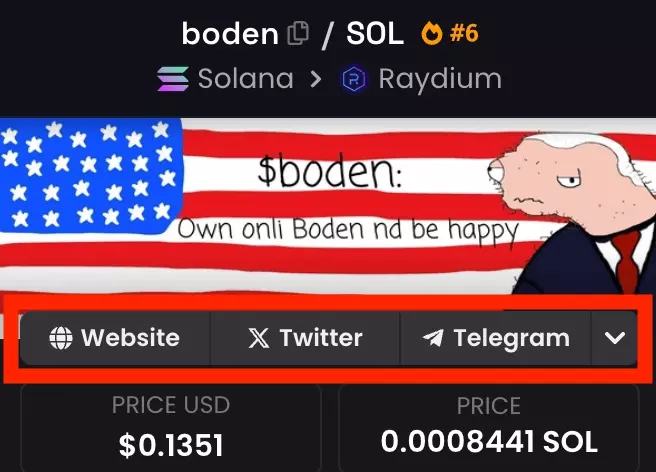
And the right influencer’s tweet can cause a token’s valuation to explode.
Is it possible to also scrape this information?
Yes completely!
If you need to scrape all of a person's tweets at regular intervals, and export it to a GoogleSheet, I recommend this powerful one in particular: