
Comment scraper une page produit avec Python et ChatGPT?
Le web scraping, c’est vraiment bien, on ne va pas vous dire le contraire. Ça permet de collecter de la donnée accessible publiquement: rapidement, sans (quasiment) aucune erreur, et à un prix ultra-compétitif.
Toutefois, le problème est simple: pour chaque site, il faut développer un robot dédié, qu’on appelle crawler. Un crawler pour Amazon, un crawler pour Etsy, un crawler pour eBay… et ça coûte vite très cher.
A en croire les prix pratiqués par notre entreprise, et sans aucun doute les plus compétitifs du marché! il faut compter entre 500-1000 EUR par site par robot. Si vous avez 5-10 robots, les prix peuvent vite devenir limitants.
Dans ce tutoriel, on va voir comment scraper n’importe quelle page produit avec ChatGPT et Python.
Développeurs, products managers, furieux de la veille de prix: ce tutoriel est fait pour vous!
Code Complet
import os import requests import html2text import re import argparse OPENAI_API_KEY = 'YOUR_OPEN_AI_API_KEY' COMPLETION_URL = 'https://api.openai.com/v1/chat/completions' PROMPT = """Find the main article from this product page, and return from this text content, as JSON format: article_title article_url article_price %s""" MAX_GPT_WORDS = 2000 class pricingPagesGPTScraper: def __init__(self): self.s = requests.Session() def get_html(self, url): assert url and isinstance(url, str) print('[get_html]\n%s' % url) headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'sec-ch-device-memory': '8', 'sec-ch-dpr': '2', 'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-ch-ua-platform-version': '"12.5.0"', 'sec-ch-viewport-width': '1469', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', 'viewport-width': '1469', } self.s.headers = headers r = self.s.get(url) assert r.status_code == 200 html = r.text return html def convert_html_to_text(self, html): assert html h = html2text.HTML2Text() h.ignore_links = True h.ignore_images = True text = h.handle(html) assert text return text def reduce_text_size(self, text): print('Starting text size: %s' % len(text)) assert text words = re.findall(r'\w+', text) if len(words) > MAX_GPT_WORDS: initial_characters = len(text) size_ratio = len(words)/MAX_GPT_WORDS print('/!\\ text too large! size being divided by %s' % size_ratio) max_characters = int(initial_characters//size_ratio) text = text[:max_characters] print('Ending text size: %s' % len(text)) return text def fill_prompt(self, text): assert text prompt = PROMPT % text return prompt # @retry(AssertionError, tries=3, delay=2) def get_gpt(self, prompt): headers = { 'Authorization': 'Bearer %s' % OPENAI_API_KEY, } json_data = { 'model': 'gpt-3.5-turbo', 'messages': [ { "role": "user", "content": prompt } ], 'temperature': 0.7 } response = requests.post(COMPLETION_URL, headers=headers, json=json_data) assert response.status_code == 200 content = response.json()["choices"][0]["message"]["content"] return content def main(self, url): assert url html = self.get_html(url) text = self.convert_html_to_text(html) text = self.reduce_text_size(text) prompt = self.fill_prompt(text) answer = self.get_gpt(prompt) return answer def main(): argparser = argparse.ArgumentParser() argparser.add_argument('--url', '-u', type=str, required=False, help='product page url to be scraped', default='https://www.amazon.com/dp/B09723XSVM') args = argparser.parse_args() url = args.url assert url pp = pricingPagesGPTScraper() answer = pp.main(url) print(answer) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
Pour utiliser ce script, c’est très simple: télécharger le fichier .py, changez la valeur de la clé d’API d’Open AI avec la vôtre, et lancer le script comme suit, en précisant l’URL à scraper:
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.walmart.com/ip/1146797 [get_html] https://www.walmart.com/ip/1146797 Starting text size: 1915 Ending text size: 1915 { "article_title": "Weber 14\" Smokey Joe Charcoal Grill, Black", "article_url": "", "article_price": "USD$45.99" } ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Et voilà!
Tutoriel étape par étape
Avoir une idée qui passe par la tête c’est bien. Mais comment on va la mettre en place?
Dans ce tutoriel, on va voir comment coder un outil complet, qui va chercher le contenu d’une page HTML, le fournit à ChatGPT, et laisse renvoie le prix, le titre, et l’URL d’un article au format JSON.
Pour schématiser, voilà comment va fonctionner notre programme :
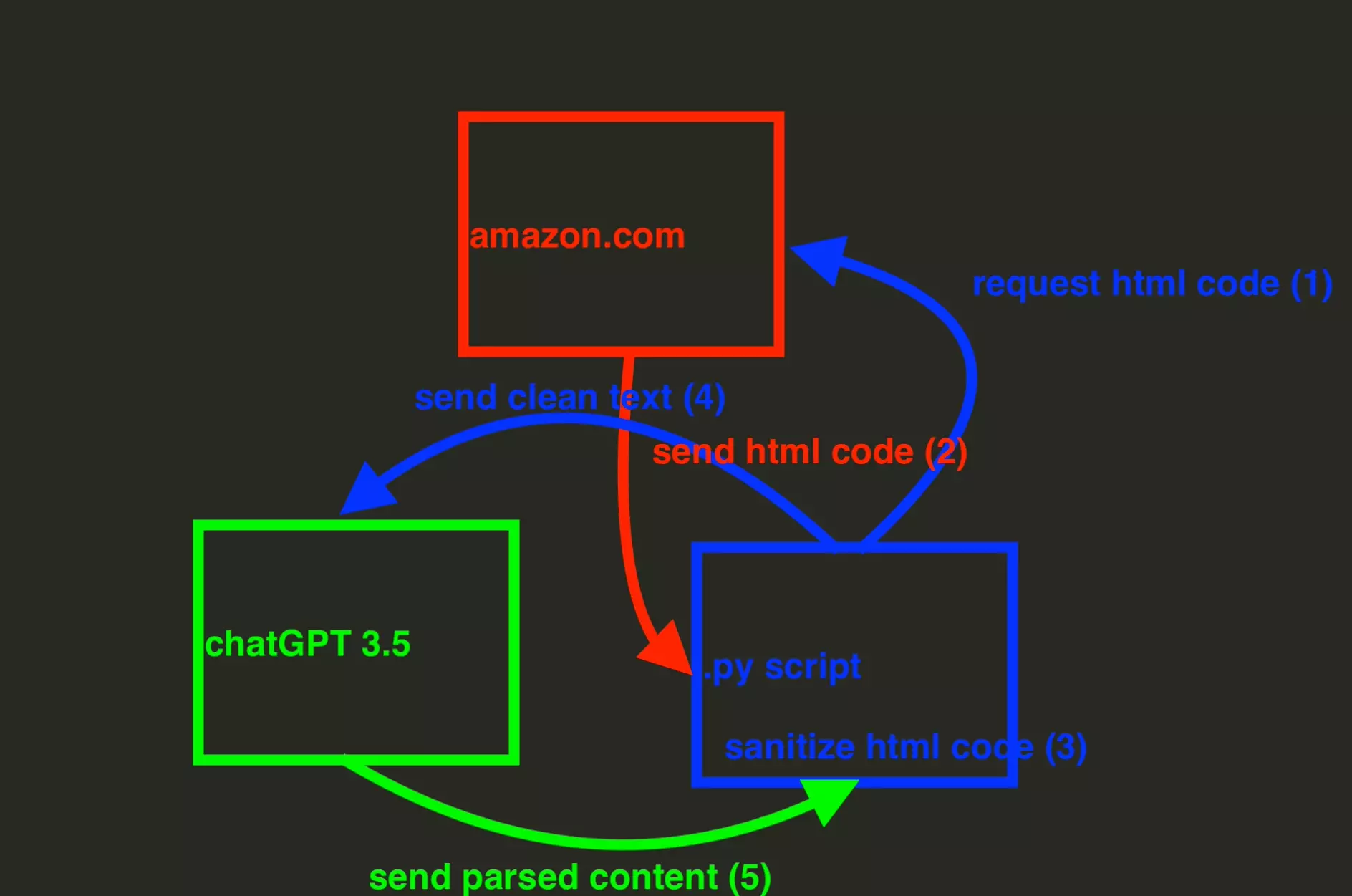
Ce tutoriel sera divisé en 6 étapes:
- Récupérer sa clé d’API OpenAI
- Récupérer le code HTML d’une page produit
- Convertir le HTML en texte
- Réduire la taille du texte
- Récupérer les informations avec ChatGPT
- Ajouter des variables dynamiques
En route!
1. Récupérer sa clé d’API OpenAI
Pour cela, procédez comme suit:
- Rendez-vous sur platform.openai.com
- Renseignez vos identifiants
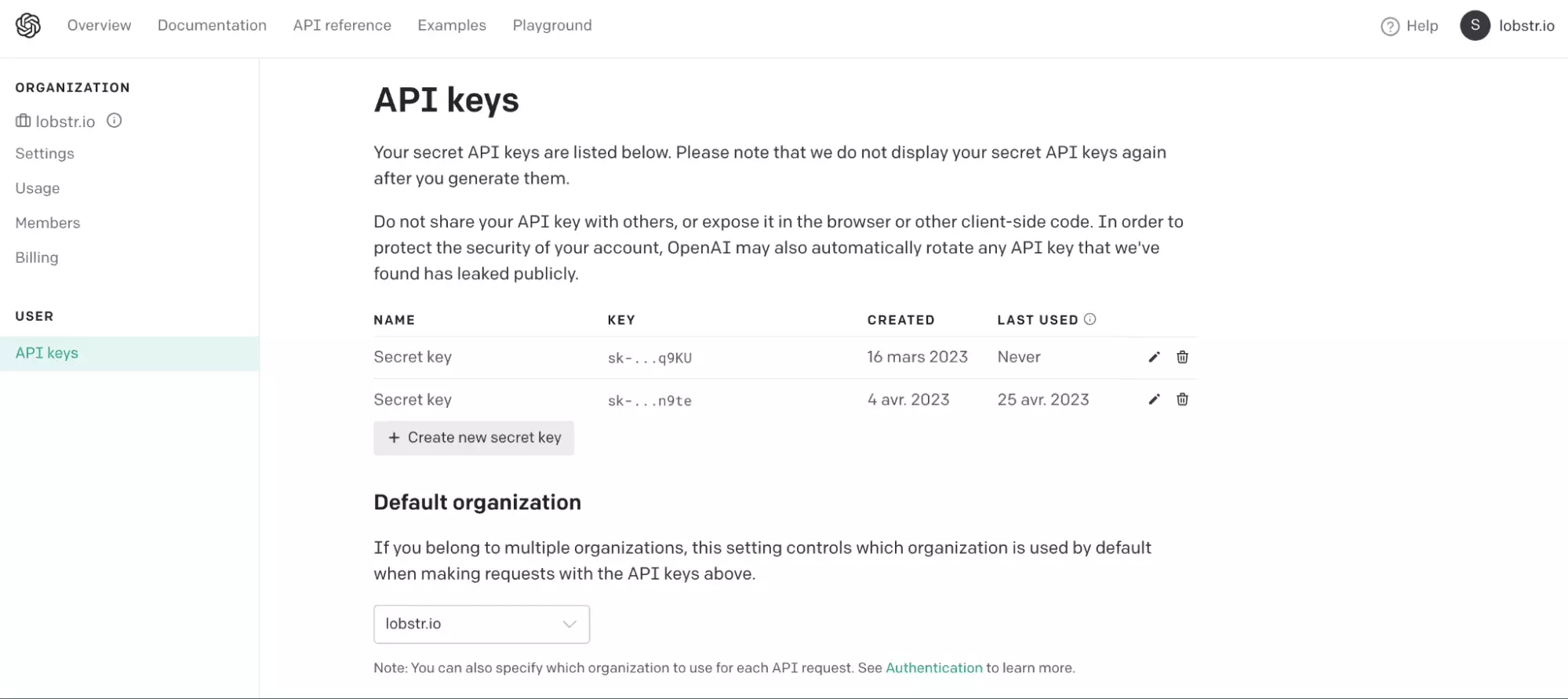
- En haut à droite, cliquez sur View API Keys
- Enfin, cliquez sur Create new secret key et récupérer la valeur de la clé
Comme visible ici:
Et voilà!
Enfin, on va inscrire la valeur de la clé dans notre script:
OPENAI_API_KEY = 'sk-dTRYAg…'f
On va maintenant être capables, avec notre script Python, d'interagir avec l’API d’Open AI de façon programmatique. Et donc d'interagir avec l’exceptionnelle intelligence robotique ChatGPT.
A nous de jouer.
2. Récupérer le code HTML d’une page produit
Comme vu en introduction, le programme fonctionne comme suit: il récupère d’abord le code HTML d’une page, le nettoie, et l’envoie ensuite à l’intelligence artificielle d’Open AI ChatGPT, pour que celle-ci identifie les éléments pertinents, à savoir le prix, le titre, et l’URL du produit.
En d’autres termes, le script Python assure la navigation sur les pages et la récupération du contenu brut, ce qu’on appelle le browsing, tandis que ChatGPT se charge du parsing, la récupération des informations sur une page.
On va donc dans un premier temps récupérer avec notre script le contenu HTML de la page.
Comme suit :
$ pip3 install requestsf
On va ensuite créer notre classe, pricingPagesGPTScraper, avec une première méthode, get_html, qui en entrée prend un URL, et en sortie renvoie le contenu d’une page HTML.
Comme suit :
import requests class pricingPagesGPTScraper: def __init__(self): self.s = requests.Session() def get_html(self, url): assert url and isinstance(url, str) print('[get_html]\n%s' % url) headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'sec-ch-device-memory': '8', 'sec-ch-dpr': '2', 'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-ch-ua-platform-version': '"12.5.0"', 'sec-ch-viewport-width': '1469', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', 'viewport-width': '1469', } self.s.headers = headers r = self.s.get(url) assert r.status_code == 200 html = r.text return htmlf
3. Convertir le HTML en texte
Avant de développer un script, on va d’abord tester notre idée directement depuis l’interface graphique proposée par Open AI. Prenons donc une première page produit exemple, la suivante :
Après tout c’est l’été, BBQ et saucisse à l’honneur.
On va sur la page, clique-droit, Afficher le code source de la page. Un nouvel onglet va s’ouvrir, avec le code HTML de la page, que notre navigateur Python va récupérer.
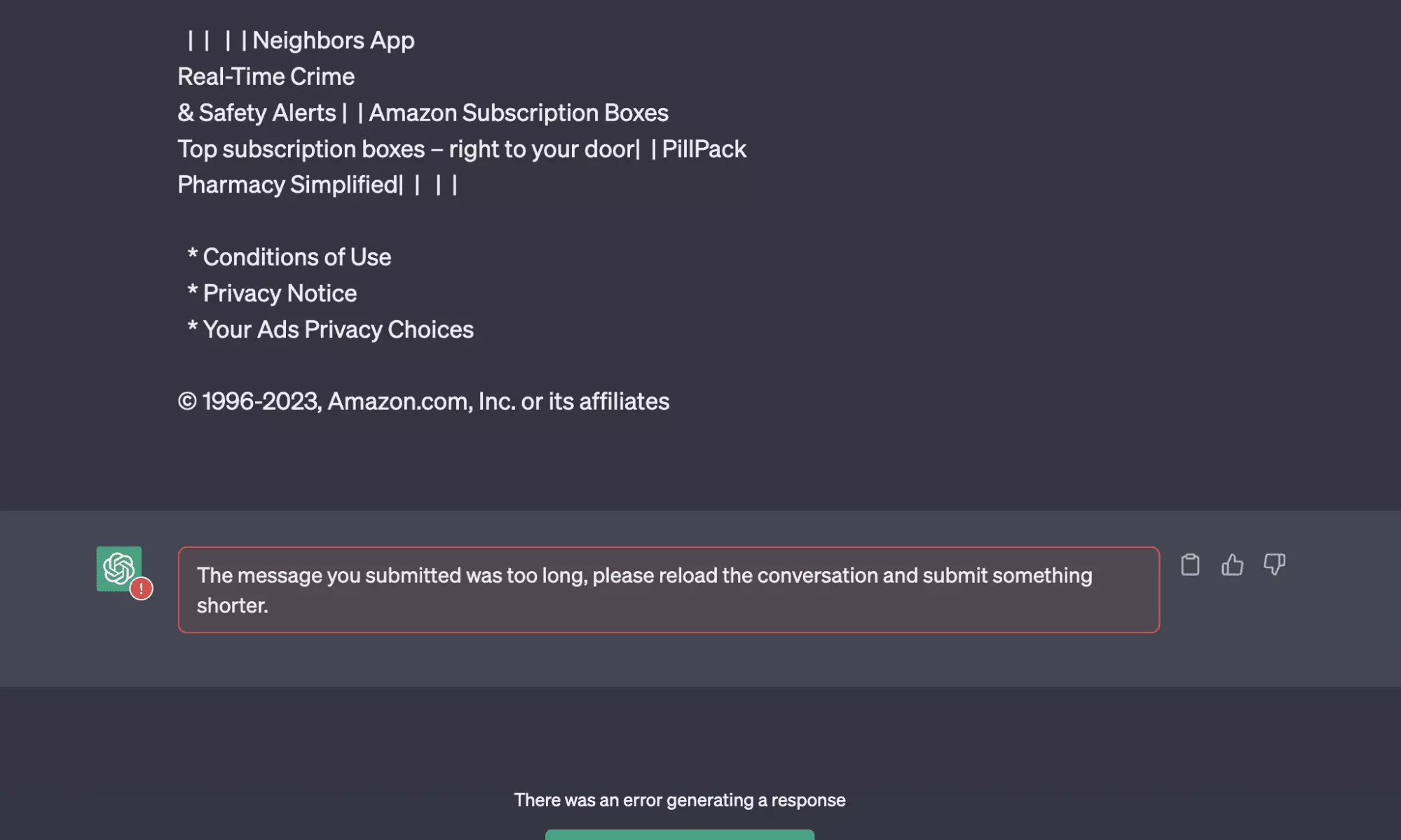
Et là première douche, on reçoit ce message d’erreur assez explicite :
The message you submitted was too long, please reload the conversation and submit something shorter.
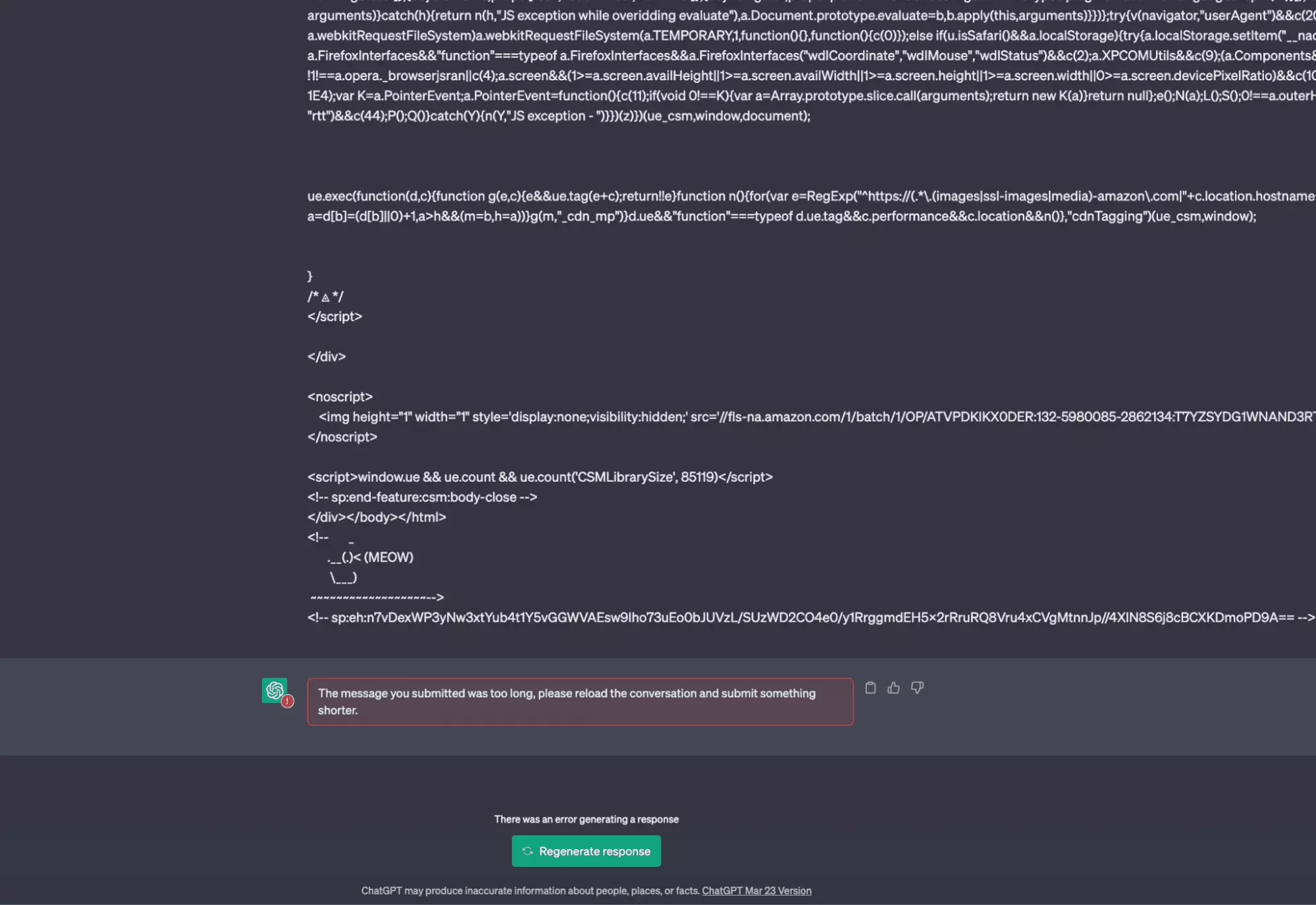
En d’autres termes, le message est trop long. Comment réduire la taille du texte, sans que cela n’affecte la qualité du contenu?
Et bien c’est simple, on va convertir le contenu HTML en contenu texte!
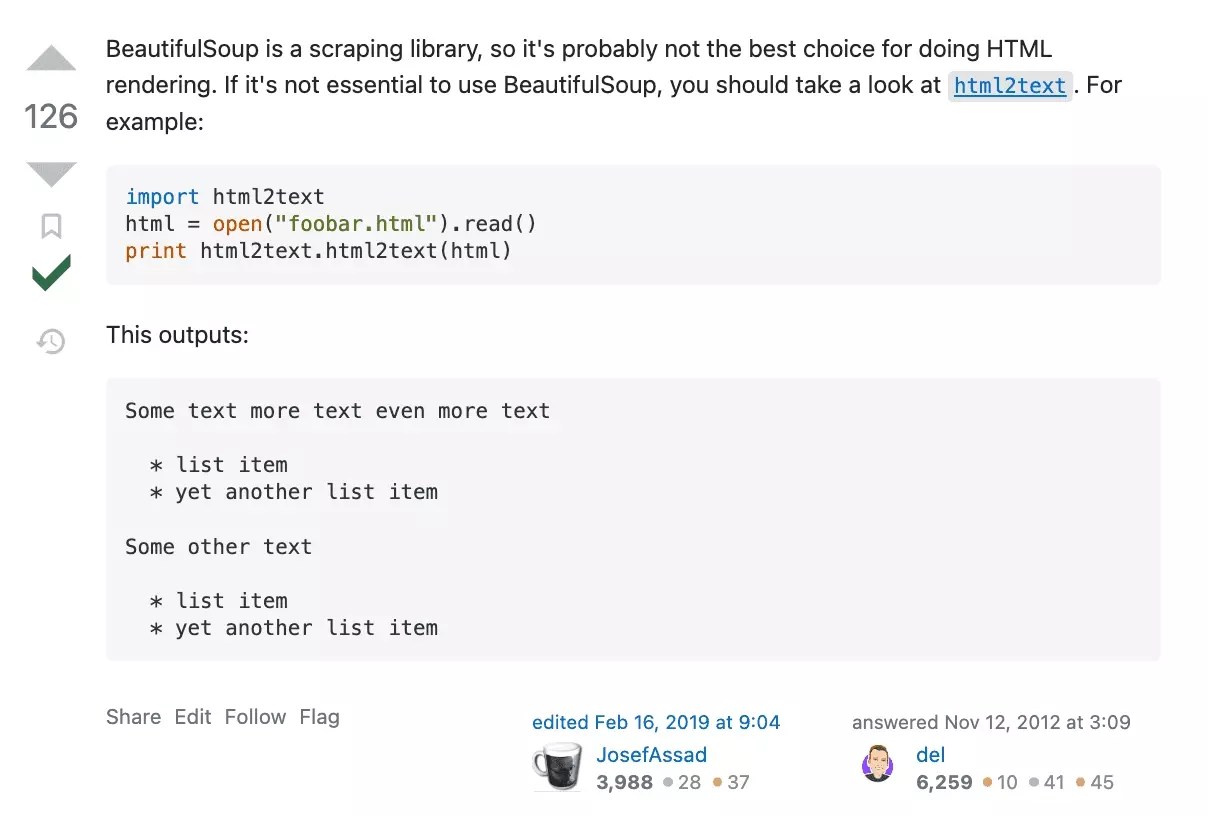
On installe donc la librairie en question :
$ pip3 install html2textf
Puis on importe la librairie dans notre script, et on crée une nouvelle méthode pour convertir le code html en texte, converthtmltotext_ comme suit :
import html2text ... class pricingPagesGPTScraper: ... def convert_html_to_text(self, html): assert text h = html2text.HTML2Text() h.ignore_links = True h.ignore_images = True text = h.handle(html) print('HTML size: %s' % len(html)) print('Text size: %s' % len(text)) return textf
Les deux attributs ignorelinks et ignoreimages nous permettent de ne pas convertir en texte les liens hypertextes associés aux images et aux liens de la page. ChatGPT ne fonctionnant qu’avec du contenu texte, c’est parfait pour nous!
On lance le programme, et… eureka! La taille du texte a été divisée par 100.**
$ python3 chatgpt_powered_product_page_universal_scraper.py HTML size: 2084770 Text size: 22287f
Surtout, la qualité du texte est ultra-qualitative, avec uniquement du texte lisible et compréhensible par un humain (ou doté d’une intelligence artificielle), et plus du contenu à destination de programmes informatiques tierces.
On récupère le contenu texte, on le place à nouveau sur ChatGPT, et.. suspense… on a plus de texte illisible, mais le résultat reste le même: le texte est toujours trop long.
Dans la prochaine partie, on va voir comment réduire la taille du texte.
4. Réduire la taille du texte
On l’a bien compris, le texte que l’on fournit à ChatGPT est trop long. Terriblement long, avec plus de 20000 caractères.
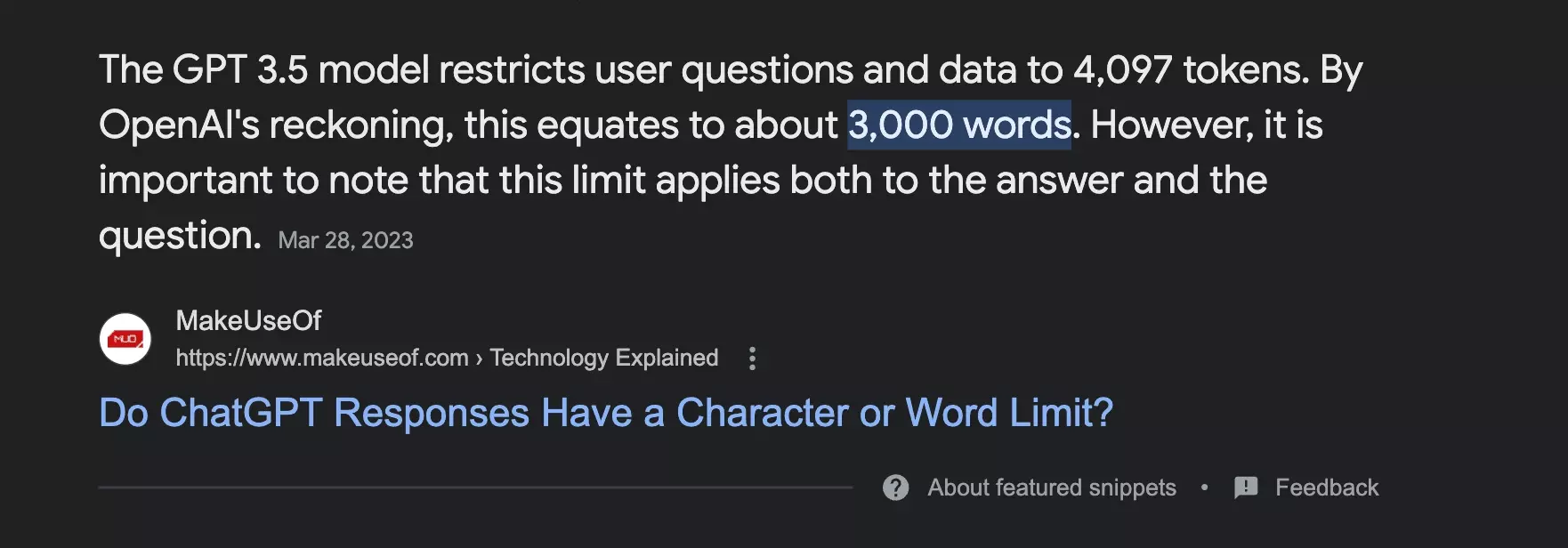
Mais quelle est la taille maximale que ChatGPT peut accueillir?
Après une rapide recherche sur Google, il apparaît que le programme peut recueillir:
- 3000 mots
- 4097 tokens
Compte tenu de l’incertitude concernant le ratio entre le nombre de tokens et de mots, on va choisir une limite basse de 2000 mots, et voilà la partie du code qui va limiter la taille du contenu texte :
MAX_GPT_WORDS = 2000 ... class pricingPagesGPTScraper: ... def reduce_text_size(self, text): assert text words = re.findall(r'\w+', text) if len(words) > MAX_GPT_WORDS: initial_characters = len(text) size_ratio = len(words)/MAX_GPT_WORDS print('/!\\ text too large! size being divided by %s' % size_ratio) max_characters = int(initial_characters//size_ratio) text = text[:max_characters] return textf
Le code fonctionne comme suit :
- On récupère le texte issu du code HTML de la partie précédente
- Avec une regex, on calcule le nombre de mots du texte
- On trouve la limite de caractères nécessaire
- On coupe le texte au niveau de cette limite
Et voilà!
Le texte est maintenant réduit, amputé d’approximativement 30-40% de sa taille.
Court et correct.
$ python3 chatgpt_powered_product_page_universal_scraper.py Starting text size: 22328 /!\ text too large! size being divided by 1.788 Ending text size: 12487f
Notre texte est de bonne taille, on va maintenant le soumettre à ChatGPT, pour qu’il aille chercher les bonnes informations.
Place au prompt!
5. Récupérer les informations avec ChatGPT
Il est temps d’interagir avec ChatGPT!
Dans cette partie, on va générer un premier prompt, qui va nous permettre d’intéragir avec ChatGPT, qui va aller chercher dans le texte fourni, les principales informations de la page produit, à savoir:
- article_title
- article_url
- article_price
Et afin de faciliter le traitement programmatique des données, voilà le premier prompt qu’on va utiliser :
Find the main article from this product page, and return from this text content, as JSON format:
article_title
article_url
article_price
... COMPLETION_URL = 'https://api.openai.com/v1/chat/completions' AMAZON_URL = 'https://www.amazon.com/dp/B0BZVZ6Z8C' PROMPT = """Find the main article from this product page, and return from this text content, as JSON format: article_title article_url article_price %s""" class pricingPagesGPTScraper: ... def fill_prompt(self, text): assert text prompt = PROMPT % text return prompt def get_gpt(self, prompt): headers = { 'Authorization': 'Bearer %s' % OPENAI_API_KEY, } json_data = { 'model': 'gpt-3.5-turbo', 'messages': [ { "role": "user", "content": prompt } ], 'temperature': 0.7 } response = requests.post(COMPLETION_URL, headers=headers, json=json_data) assert response.status_code == 200 content = response.json()["choices"][0]["message"]["content"] return contentf
On lance le programme, et cette fois le résultat est bluffant, voilà ce qu’on obtient :
$ python3 chatgpt_powered_product_page_universal_scraper.py [get_html] https://www.amazon.com/dp/B0BZVZ6Z8C Starting text size: 13730 /!\ text too large! size being divided by 1.056 Ending text size: 13001 { "article_title": "Barbecue Grill, American-Style Braised Oven Courtyard Outdoor Charcoal Grilled Steak Camping Household Charcoal Grill Suitable for Family Gatherings", "article_url": "https://www.amazon.com/dp/B0BZVZ6Z8C", "article_price": "$108.89" }f
Un JSON parfaitement structuré, avec 3 éléments
- article_title
- article_url
- article_price
Et lorsqu’on se rend sur la page, on retrouve bien ces éléments là :
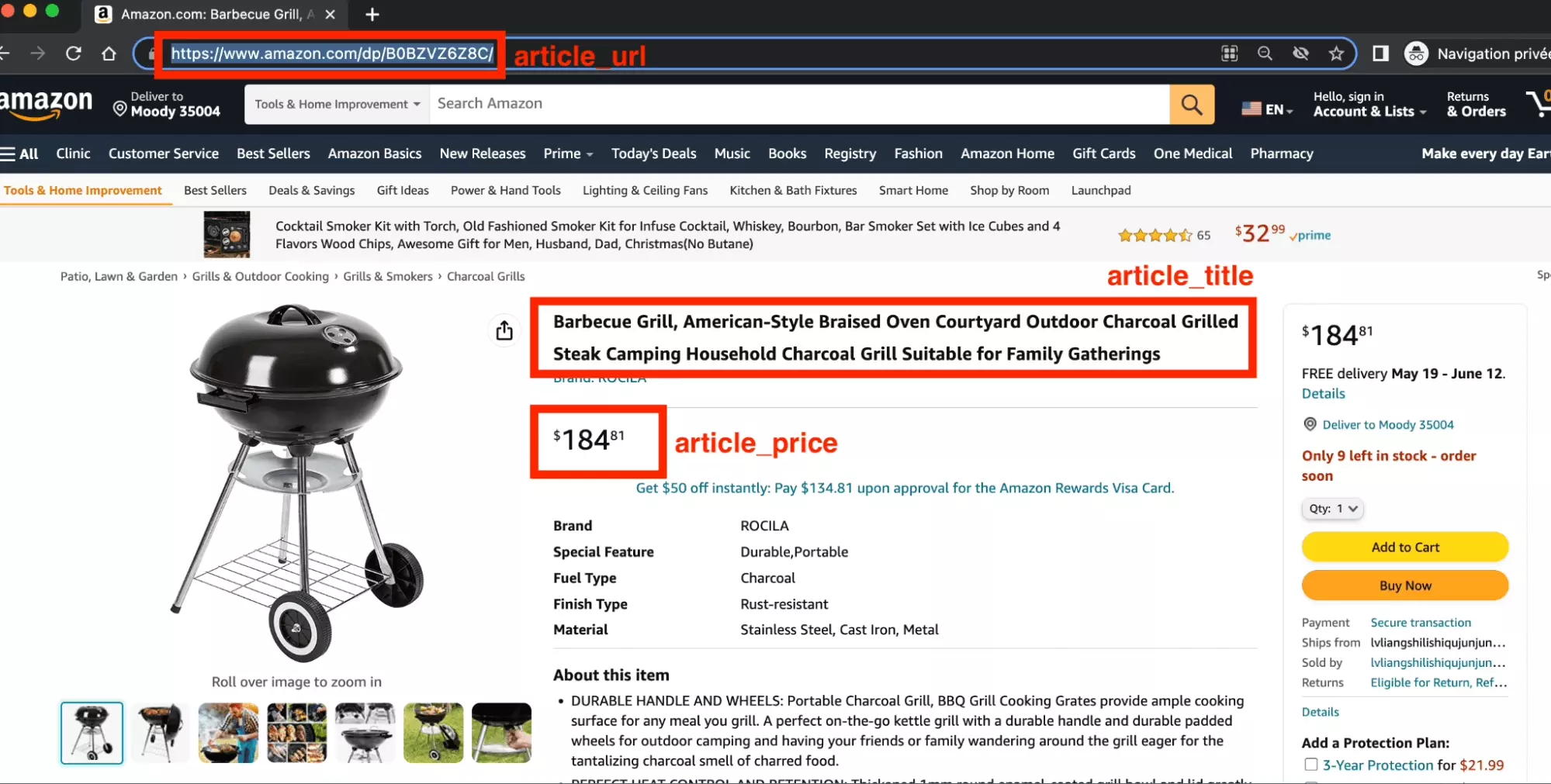
Le compte est bon, magnifique!
6. Ajouter des variables dynamiques
L’article d’Amazon, c’est bien. Mais c’est peut-être un coup de chance.
Comment tester n’importe quelle url?
On va d’abord consolider notre méthode, pour ne conserver qu’une seule méthode finale :
... class pricingPagesGPTScraper: ... def main(self, url): assert url html = self.get_html(url) text = self.convert_html_to_text(html) text = self.reduce_text_size(text) prompt = self.fill_prompt(text) answer = self.get_gpt(prompt) return answerf
Puis au niveau de la fonction principale, on va récupérer l’url mentionné dans la ligne de commande :
import argparse ... def main(): argparser = argparse.ArgumentParser() argparser.add_argument('--url', '-u', type=str, required=False, help='product page url to be scraped', default='https://www.amazon.com/dp/B09723XSVM') args = argparser.parse_args() url = args.url assert url pp = pricingPagesGPTScraper() answer = pp.main(url) print(answer) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
Est-ce que notre programme a fonctionné 1 fois par chance, ou est-ce qu’il est vraiment robuste? On va le découvrir immédiatement.
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.ebay.com/itm/165656992670 [get_html] https://www.ebay.com/itm/165656992670 Starting text size: 11053 Ending text size: 11053 { "article_title": "Portable mangal brazier 10 skewers steel 2.5 mm grill BBQ case for free", "article_url": "", "article_price": "US $209.98" } ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Il nous manque l’URL ici, mais pour le reste ça a parfaitement fonctionné :
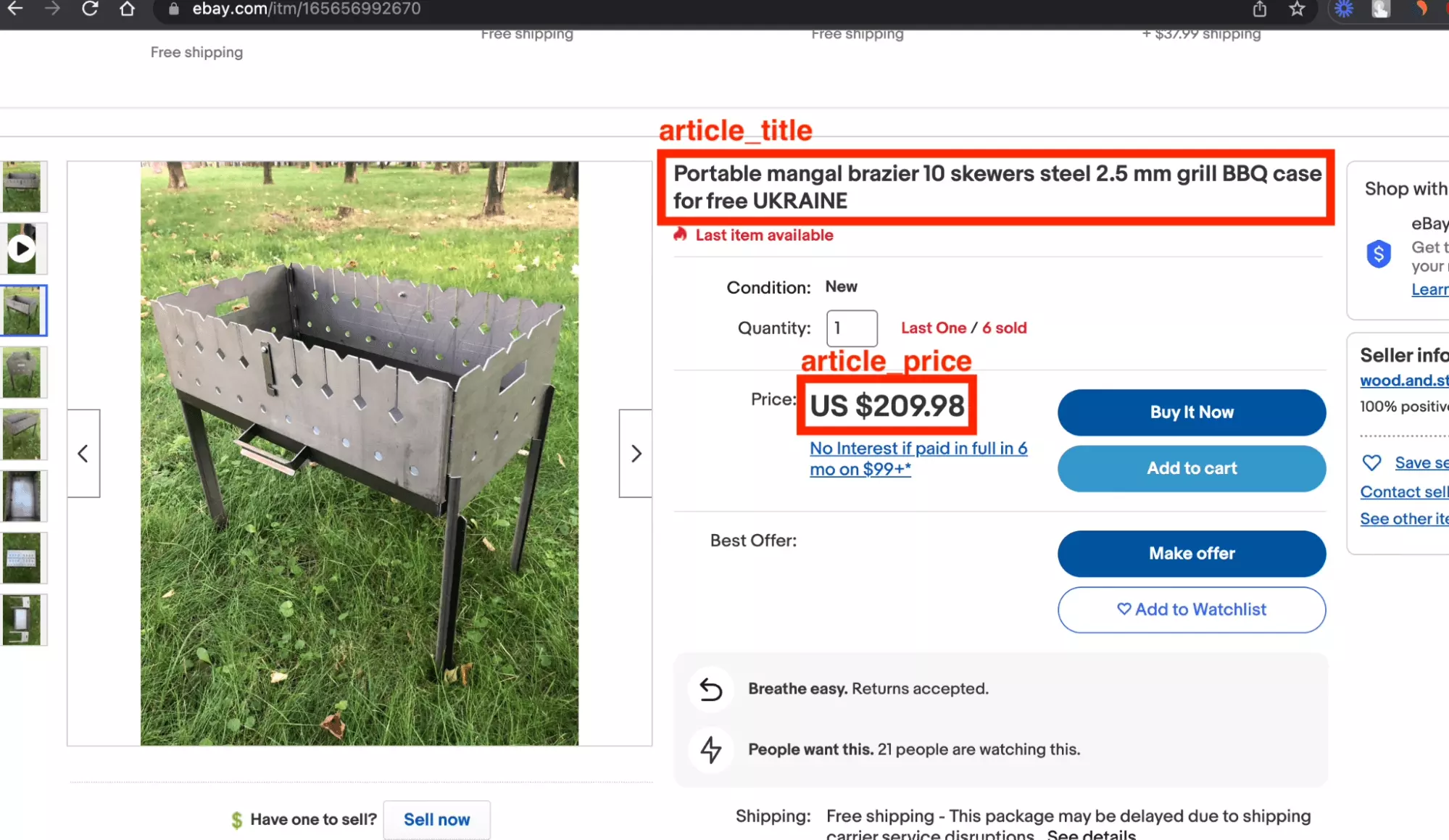
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.walmart.com/ip/1146797 [get_html] https://www.walmart.com/ip/1146797 Starting text size: 1948 Ending text size: 1948 { "article_title": "Weber 14\" Smokey Joe Charcoal Grill, Black", "article_url": null, "article_price": "USD$45.99" } ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Et même chose, un succès, avec le bon prix du produit et le titre, l’URL étant lui non disponible :
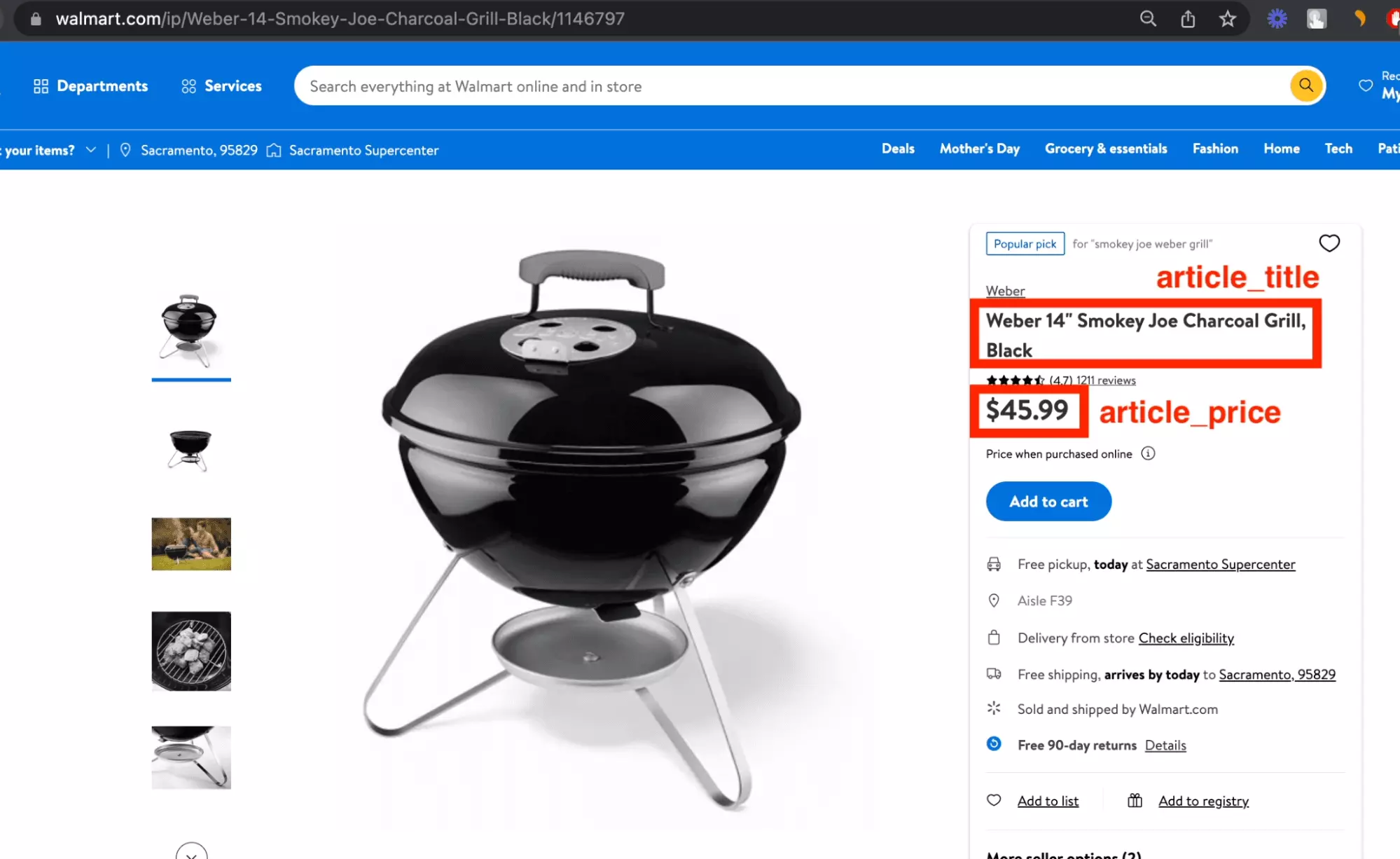
Sur 3 essais, on a donc un retour solide, avec :
✅3 titres ✅3 prix 🔴1 url
Pas parfait, mais plus que satisfaisant. Ça fonctionne!
Bénéfices
Comme vu dans la partie précédente, le scraping automatique de n’importe quelle page produit fonctionne superbement avec ChatGPT et Python!
Quelles sont les bénéfices de cette solution?
D’abord, comme présenté en introduction, cette solution apporte une importante flexibilité. En effet, inutile de développer, pour chaque type de page produit, un robot dédié. Il suffit de fournir le code HTML d’une page et d’en récupérer les bénéfices.
Par conséquent, cela permet de réduire massivement les coûts, et notamment lorsque vous avez beaucoup de types de page différentes. Par exemple, avec 100 pages produits de structure différente, la solution sera particulièrement compétitive en termes de coût.
Limitations
Si les avantages, sont certains, quelles sont les désavantages?
D’abord, et comme on l’a vu dans le tutoriel, le résultat est imprécis. Sur 3 URLs fournies, nous n’avons obtenu qu’1 seule URL, les deux autres URLs étant malheureusement manquantes.
Plus grave, si l’on fait un test avec cet URL là, voilà le résultat que l’on obtient :
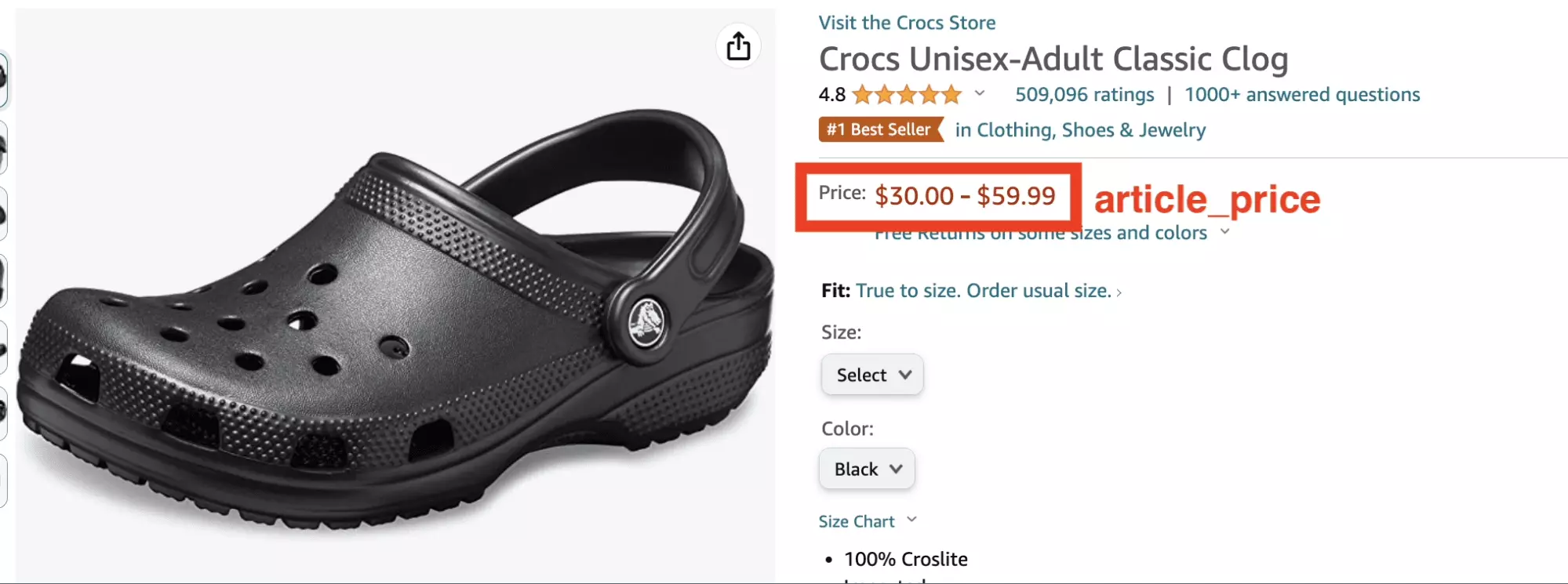
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.amazon.com/dp/B0014C2NBC { "article_title": "Crocs Unisex-Adult Classic Clog", "article_url": "https://www.amazon.com/dp/B07DMMZPW9", "article_price": "$30.00$30.00 - $59.99$59.99" }f
Le format du prix est étrangement collé, ce qui rend l’exploitation difficile :
Et le résultat est d’autant plus imprécis que se sur ajoutent les attributs supplémentaires : ranking, nombre de reviews, score, catégories, produits associés, date de livraison etc.
Par ailleurs, si l’on multiplie les collectes sur plusieurs pages produits, il apparaît rapidement que le résultat est instable.
Ainsi si l’on modifie le prompt pour obtenir l’URL de l’image du produit, on va obtenir, à deux essais d’intervalle, les résultats suivants :
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.amazon.com/dp/B0BQZ9K23L { "article_title": "Stanley Quencher H2.0 FlowState Stainless Steel Vacuum Insulated Tumbler with Lid and Straw for Water, Iced Tea or Coffee, Smoothie and More", "article_image_url": null } $ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.amazon.com/dp/B0BQZ9K23L { "article_title": "Stanley Quencher H2.0 FlowState Stainless Steel Vacuum Insulated Tumbler with Lid and Straw for Water, Iced Tea or Coffee, Smoothie and More", "article_image_url": "https://m.media-amazon.com/images/I/61k8q3y1V7L._AC_SL1500_.jpg" }f
Un coup oui, un coup non.
Ensuite, comme vu lors du tutoriel, la taille du texte fourni en entrée est limitée. Si dans la plupart des cas, c’est OK, il peut arriver que le texte de la page produit soit coupé en 2, et perdre 50% de sa taille initiale.
Starting text size: 26556
/!\ text too large! size being divided by 2.088
Ending text size: 12718
Dans ces situations là, on peut imaginer que cela va avoir un impact négatif sur le rendu.
Enfin, le prix est élevé. Comme vu dans la partie FAQ, il faut compter approx. $4 pour 1000 produits. C’est un prix compétitif quand on pense que l’on peut scraper n’importe quelle page produit.
FAQ
Combien coûte ça coûte?
Cette solution est sympa, mais combien est-ce que ça coûte?
Est-ce que c’est légal?
Oui, c’est entièrement légal!
A quelle vitesse ça fonctionne?
On a fait l’expérience avec 3 URLs de barbecue. Le charme de l’été.
Et on a calculé la vitesse d’exécution pour chaque URL.
Voilà le résultat:
$ python3 test_speed_chatgpt_powered_product_page_universal_scraper.py amazon.com 10.951031041999999 walmart.com 5.695792166000002 ebay.com 7.3706024580000005f
Il faut donc compter en moyenne 7 secondes par requête. A confirmer bien entendu avec un échantillon plus large.
Est-ce qu’il existe une solution no-code?
Non, pas pour le moment. Mais ça ne saurait tarder!
Conclusion
Et voilà, c’est la fin de ce tutoriel!
Dans ce tutoriel, on a vu comment scraper n’importe quelle page produit avec Python, et l’incroyable intelligence artificielle d’OpenAI, ChatGPT. Et récupérer les attributs principaux: le nom du produit, le prix, et l’URL du produit.
Il faut le dire, si vous avez besoin de scraper les attributs principaux de 100 pages produits, qui viennent toutes de sites web différents, il s’agit d’une vraie révolution. C’est solide, (plutôt) fiable, peu coûteux et plutôt rapide.
Attention toutefois, si vous avez besoin de collecter des informations précises, toujours exactes, avec un volume important réparti sur le/les mêmes sites, vous risquez de payer plus cher que prévu, pour des informations peu fiables.
Happy scraping!
🦀