
How to scrape any product page with Python and ChatGPT?
Web scraping is really good, we won't tell you otherwise. It allows to collect publicly accessible data: quickly, with (almost) no errors, and at an ultra-competitive price.
However, the problem is simple: for each site, you have to develop a dedicated robot, called a crawler. A crawler for Amazon, a crawler for Etsy, a crawler for eBay... and it is very expensive.
According to the prices charged by our company, and without a doubt the most competitive on the market! you should count between 500-1000 EUR per site per robot. If you have 5-10 robots, prices can quickly become limiting.
In this tutorial, we'll see how to scrape any product page with ChatGPT and Python.
Developers, product managers, price watchers: this tutorial is for you!
Complete code
import os import requests import html2text import re import argparse OPENAI_API_KEY = 'YOUR_OPEN_AI_API_KEY' COMPLETION_URL = 'https://api.openai.com/v1/chat/completions' PROMPT = """Find the main article from this product page, and return from this text content, as JSON format: article_title article_url article_price %s""" MAX_GPT_WORDS = 2000 class pricingPagesGPTScraper: def __init__(self): self.s = requests.Session() def get_html(self, url): assert url and isinstance(url, str) print('[get_html]\n%s' % url) headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'sec-ch-device-memory': '8', 'sec-ch-dpr': '2', 'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-ch-ua-platform-version': '"12.5.0"', 'sec-ch-viewport-width': '1469', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', 'viewport-width': '1469', } self.s.headers = headers r = self.s.get(url) assert r.status_code == 200 html = r.text return html def convert_html_to_text(self, html): assert html h = html2text.HTML2Text() h.ignore_links = True h.ignore_images = True text = h.handle(html) assert text return text def reduce_text_size(self, text): print('Starting text size: %s' % len(text)) assert text words = re.findall(r'\w+', text) if len(words) > MAX_GPT_WORDS: initial_characters = len(text) size_ratio = len(words)/MAX_GPT_WORDS print('/!\\ text too large! size being divided by %s' % size_ratio) max_characters = int(initial_characters//size_ratio) text = text[:max_characters] print('Ending text size: %s' % len(text)) return text def fill_prompt(self, text): assert text prompt = PROMPT % text return prompt # @retry(AssertionError, tries=3, delay=2) def get_gpt(self, prompt): headers = { 'Authorization': 'Bearer %s' % OPENAI_API_KEY, } json_data = { 'model': 'gpt-3.5-turbo', 'messages': [ { "role": "user", "content": prompt } ], 'temperature': 0.7 } response = requests.post(COMPLETION_URL, headers=headers, json=json_data) assert response.status_code == 200 content = response.json()["choices"][0]["message"]["content"] return content def main(self, url): assert url html = self.get_html(url) text = self.convert_html_to_text(html) text = self.reduce_text_size(text) prompt = self.fill_prompt(text) answer = self.get_gpt(prompt) return answer def main(): argparser = argparse.ArgumentParser() argparser.add_argument('--url', '-u', type=str, required=False, help='product page url to be scraped', default='https://www.amazon.com/dp/B09723XSVM') args = argparser.parse_args() url = args.url assert url pp = pricingPagesGPTScraper() answer = pp.main(url) print(answer) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
To use this script, it's very simple: download the .py file, change the value of the Open AI API key with your own, and run the script as follows, specifying the URL to scrape:
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.walmart.com/ip/1146797 [get_html] https://www.walmart.com/ip/1146797 Starting text size: 1915 Ending text size: 1915 { "article_title": "Weber 14\" Smokey Joe Charcoal Grill, Black", "article_url": "", "article_price": "USD$45.99" } ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
And that's it!
Step by step tutorial
Having an idea in your head is good. But how do you implement it?
In this tutorial, we will see how to code a complete tool, which will fetch the content of an HTML page, provide it to ChatGPT, and let it return the price, the title, and the URL of an item in JSON format.
To put it simply, this is how our program will work:
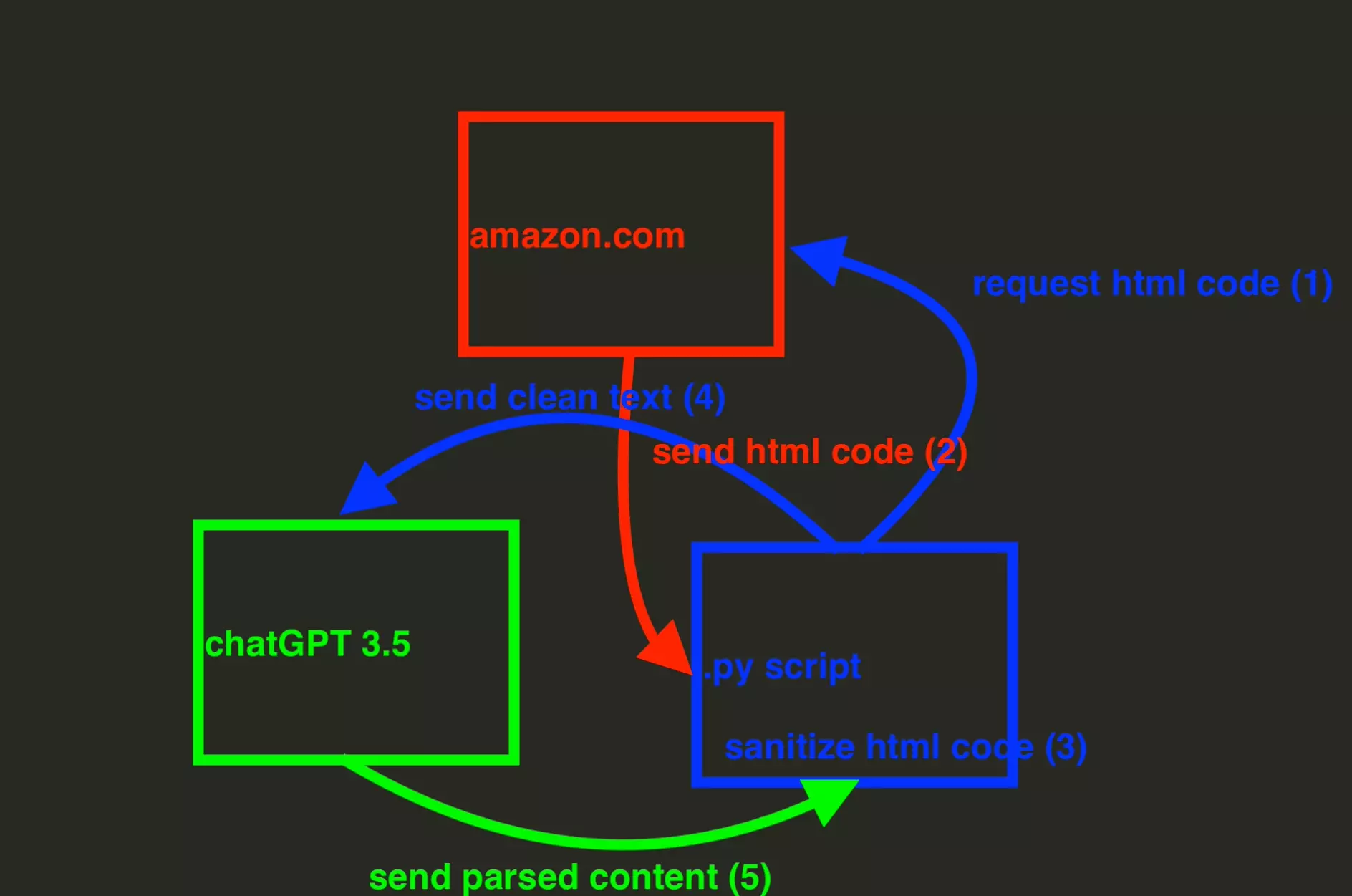
This tutorial will be divided into 6 steps:
- Get your OpenAI API key
- Get the HTML code of a product page
- Convert HTML to text
- Reduce text size
- Retrieve information with ChatGPT
- Adding dynamic variables
Let's go!
1. Get your OpenAI API key
To do this, proceed as follows:
- Go to platform.openai.com
- Fill in your login and password
- In the upper right corner, click on View API Keys
- Finally, click on Create new secret key and retrieve the key value
As seen here:
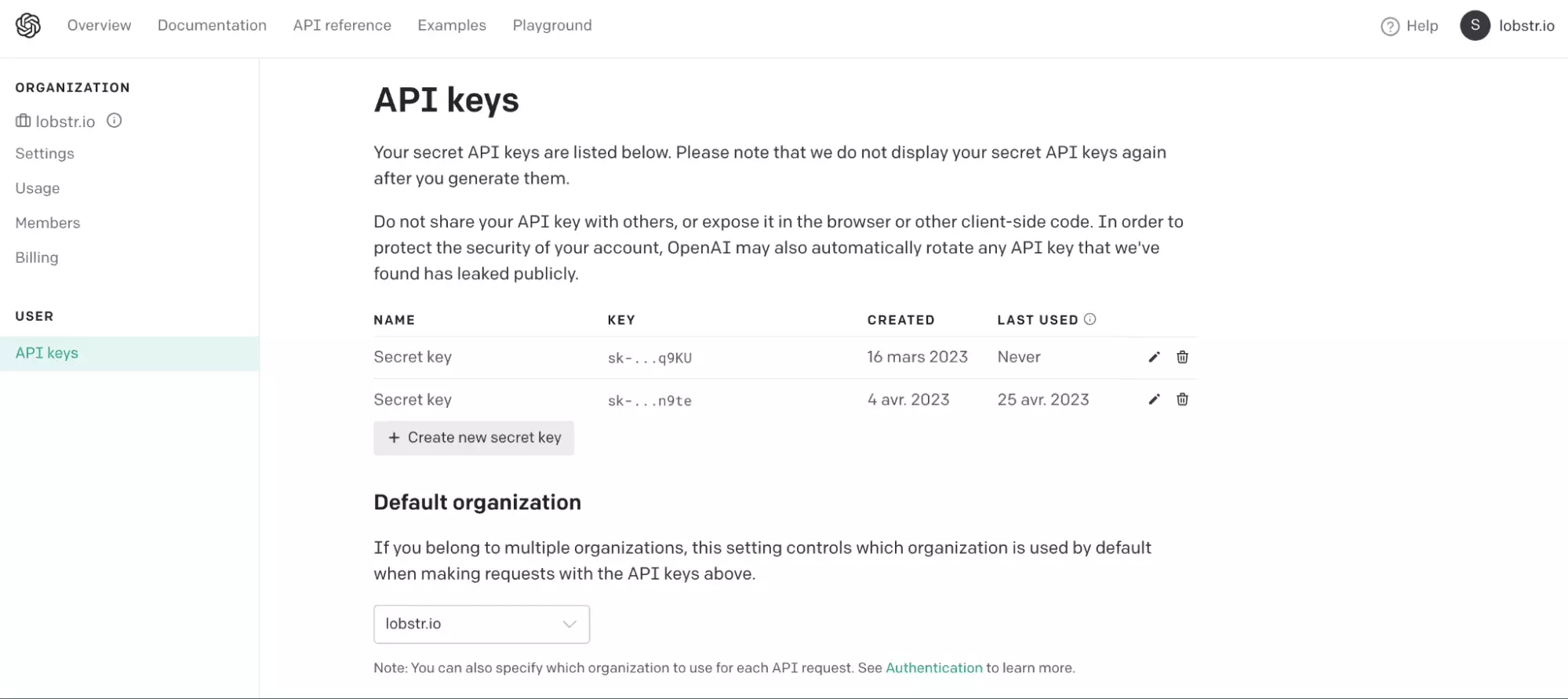
And that's it!
Finally, we will write the value of the key in our script:
OPENAI_API_KEY = 'sk-dTRYAg…'f
We will now be able, with our Python script, to interact with the Open AI API in a programmatic way. And thus interact with the exceptional robotic intelligence ChatGPT.
Let's play.
2. Get the HTML code of a product page
As seen in the introduction, the program works as follows: it first retrieves the HTML code of a page, cleans it up, and then sends it to Open AI's artificial intelligence ChatGPT, so that it identifies the relevant elements, namely the price, the title, and the URL of the product.
In other words, the Python script takes care of the navigation on the pages and the retrieval of the raw content, what we call browsing, while ChatGPT takes care of the parsing, the retrieval of information on a page.
We are going to retrieve with our script the HTML content of the page.
As follows:
$ pip3 install requestsf
We will then create our class, pricingPagesGPTScraper, with a first method, get_html, which in input takes a URL, and in output returns the content of an HTML page.
As follows:
import requests class pricingPagesGPTScraper: def __init__(self): self.s = requests.Session() def get_html(self, url): assert url and isinstance(url, str) print('[get_html]\n%s' % url) headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'sec-ch-device-memory': '8', 'sec-ch-dpr': '2', 'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-ch-ua-platform-version': '"12.5.0"', 'sec-ch-viewport-width': '1469', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', 'viewport-width': '1469', } self.s.headers = headers r = self.s.get(url) assert r.status_code == 200 html = r.text return htmlf
3. Convert HTML to text
Before developing a script, we will first test our idea directly from the graphical interface proposed by Open AI. Let's take a first example product page, the following one:
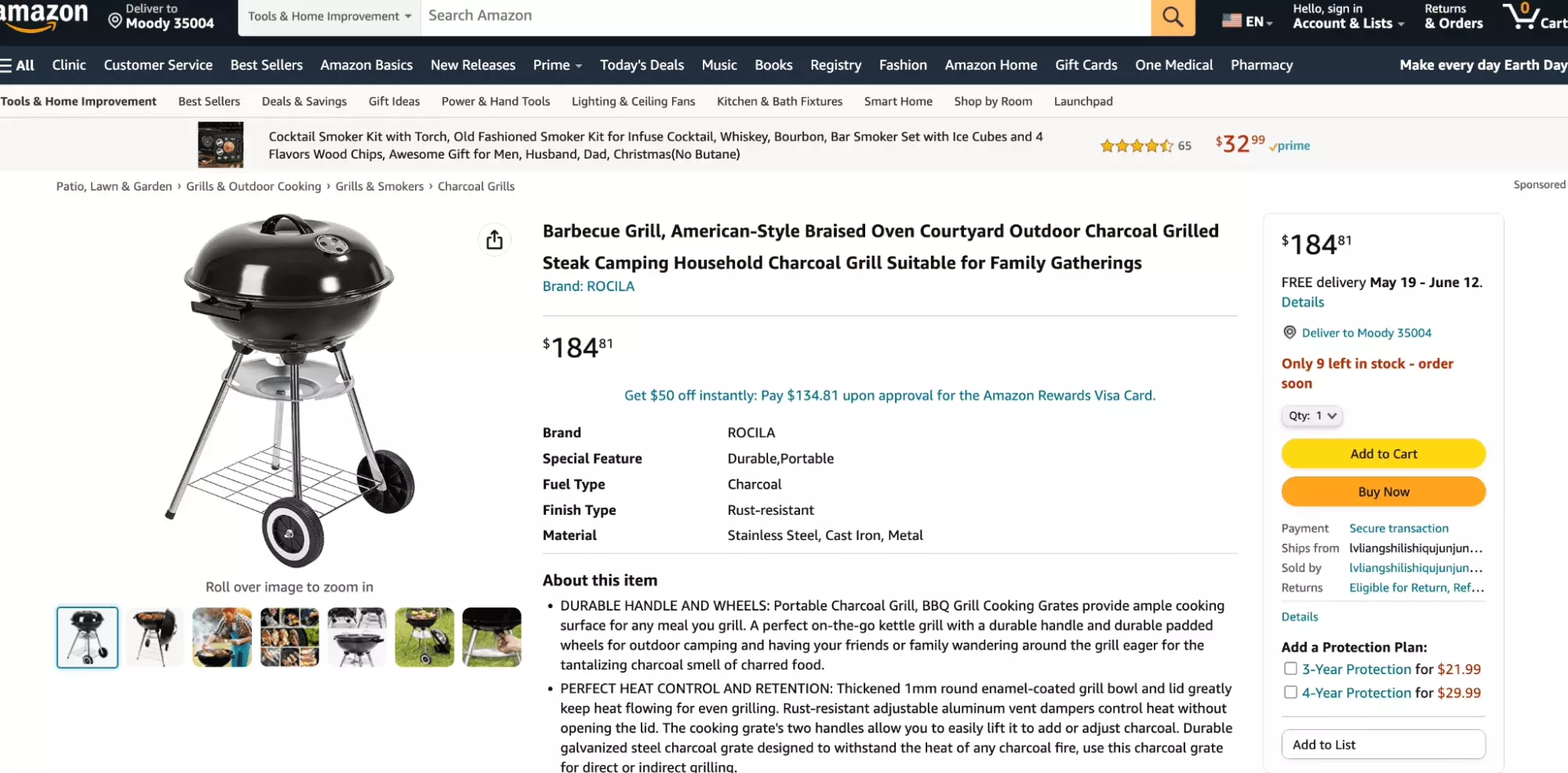
After all it's summer, BBQ and sausage in the spotlight.
We go on the page, right-click, Display the source code of the page. A new tab will open, with the HTML code of the page, that our Python browser will recover.
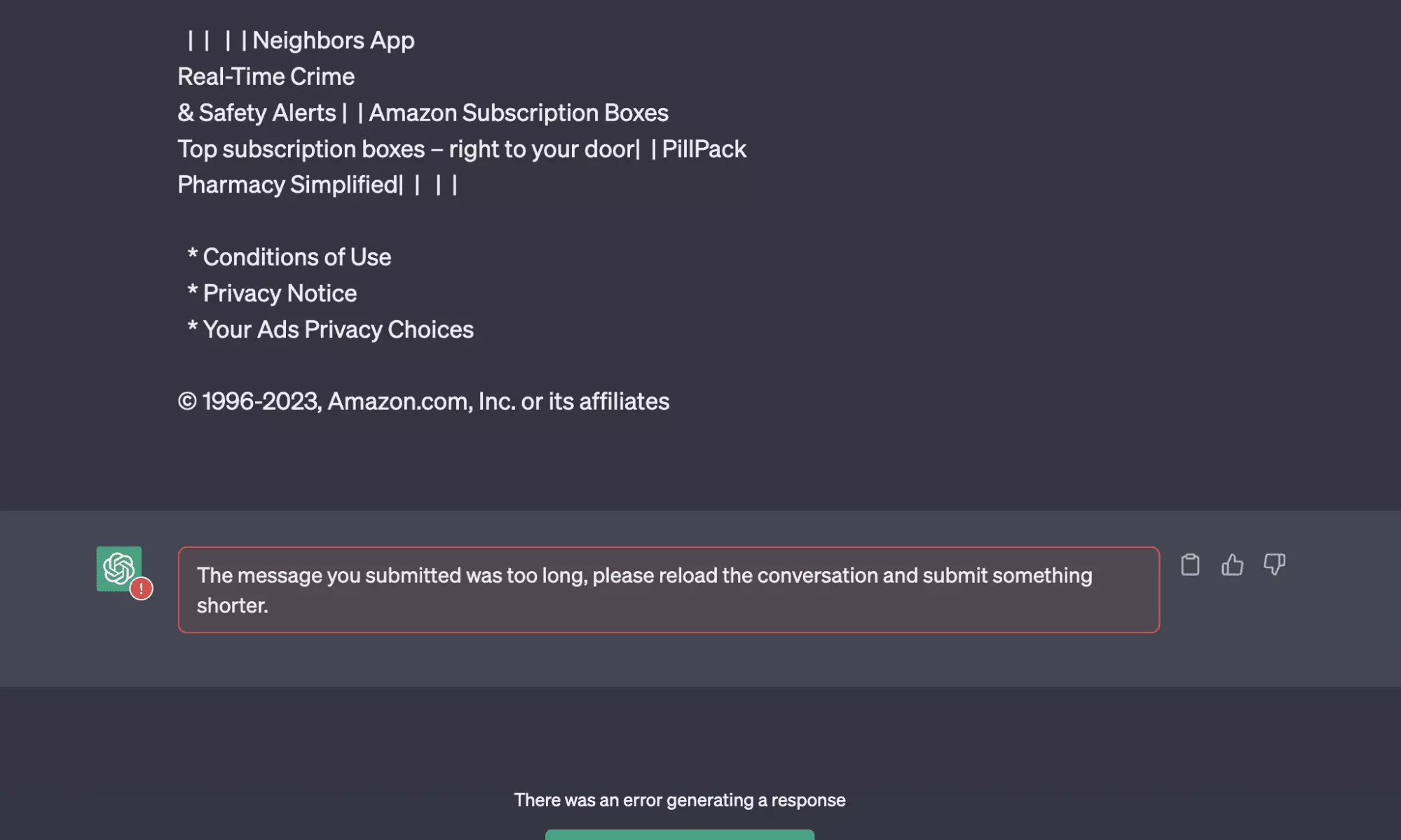
And there first shower, we receive this rather explicit error message:
The message you submitted was too long, please reload the conversation and submit something shorter.
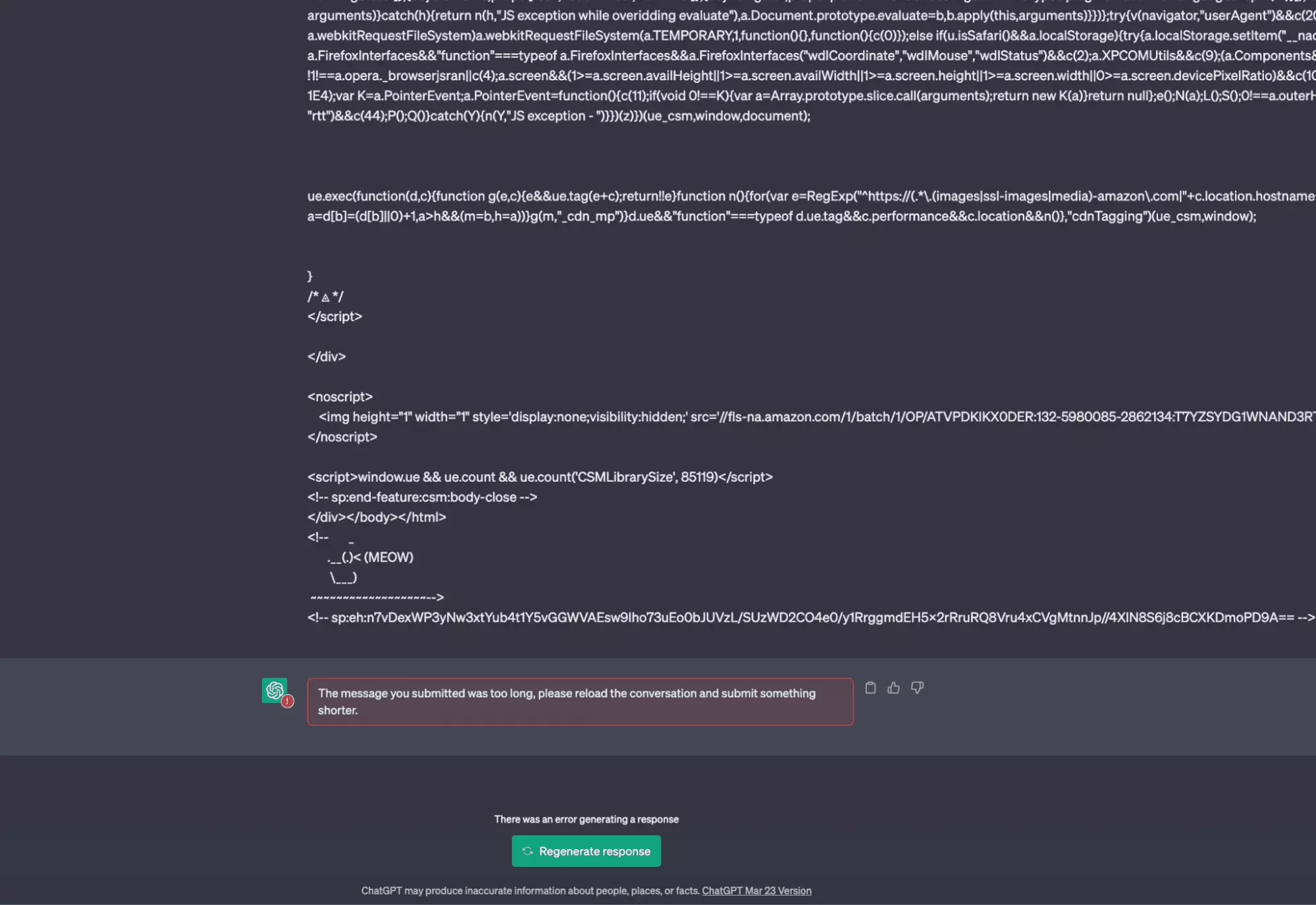
In other words, the message is too long. How to reduce the size of the text, without affecting the quality of the content?
Well, it's simple, we'll convert the HTML content into text content!
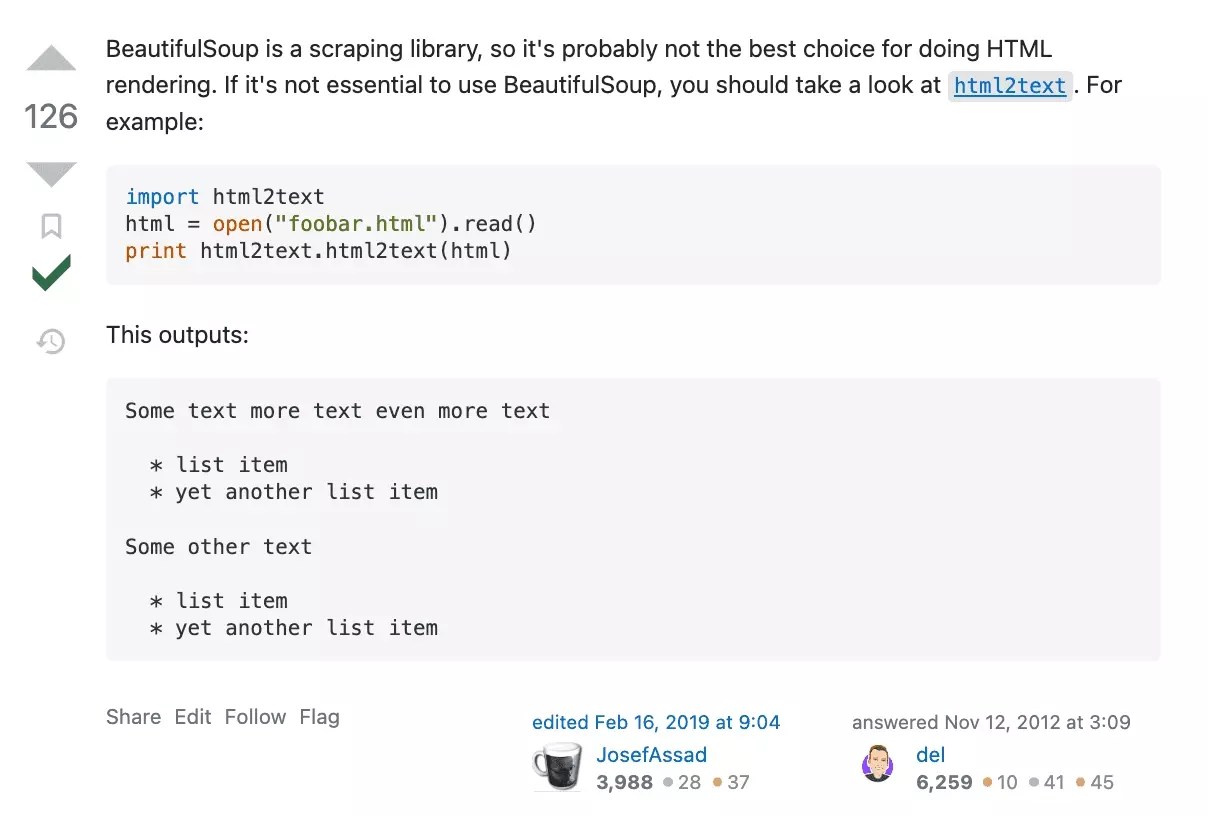
So we install the library in question :
$ pip3 install html2textf
Then we import the library into our script, and create a new method to convert the html code into text, converthtmltotext_ as follows:
import html2text ... class pricingPagesGPTScraper: ... def convert_html_to_text(self, html): assert text h = html2text.HTML2Text() h.ignore_links = True h.ignore_images = True text = h.handle(html) print('HTML size: %s' % len(html)) print('Text size: %s' % len(text)) return textf
The two attributes ignorelinks and ignoreimages allow us to not convert the hyperlinks associated with the images and links on the page to text. Since ChatGPT only works with text content, this is perfect for us!
We launch the program, and... eureka! The size of the text has been divided by 100.
$ python3 chatgpt_powered_product_page_universal_scraper.py HTML size: 2084770 Text size: 22287f
Above all, the quality of the text is ultra-qualitative, with only text readable and understandable by a human (or with artificial intelligence), and no more content for third-party computer programs.
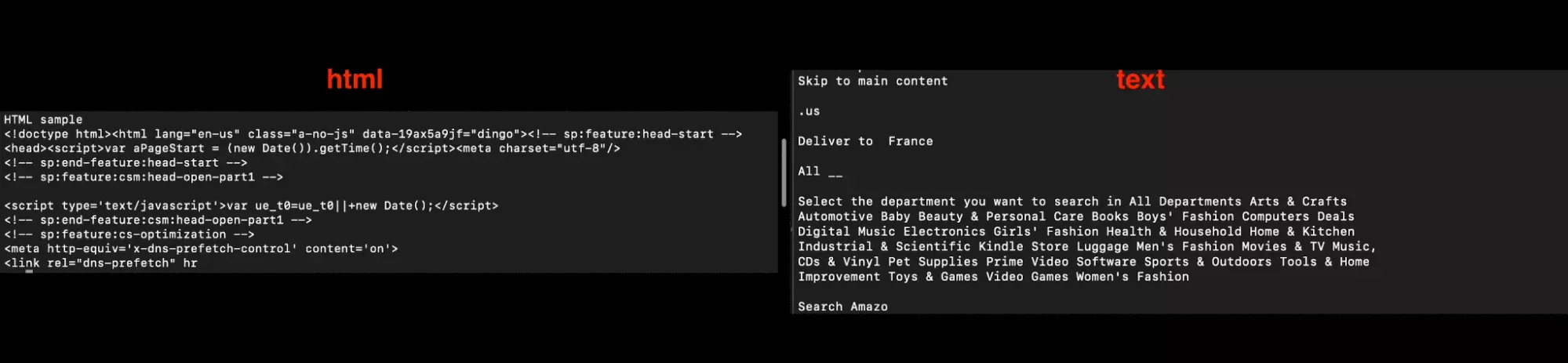
We recover the text content, we put it again on ChatGPT, and... suspense... we have more unreadable text, but the result remains the same: **the text is still too long.
In the next part, we will see how to reduce the text size.
4. Reduce the size of the text
As you can see, the text you provide to ChatGPT is too long. Terribly long, with more than 20000 characters.
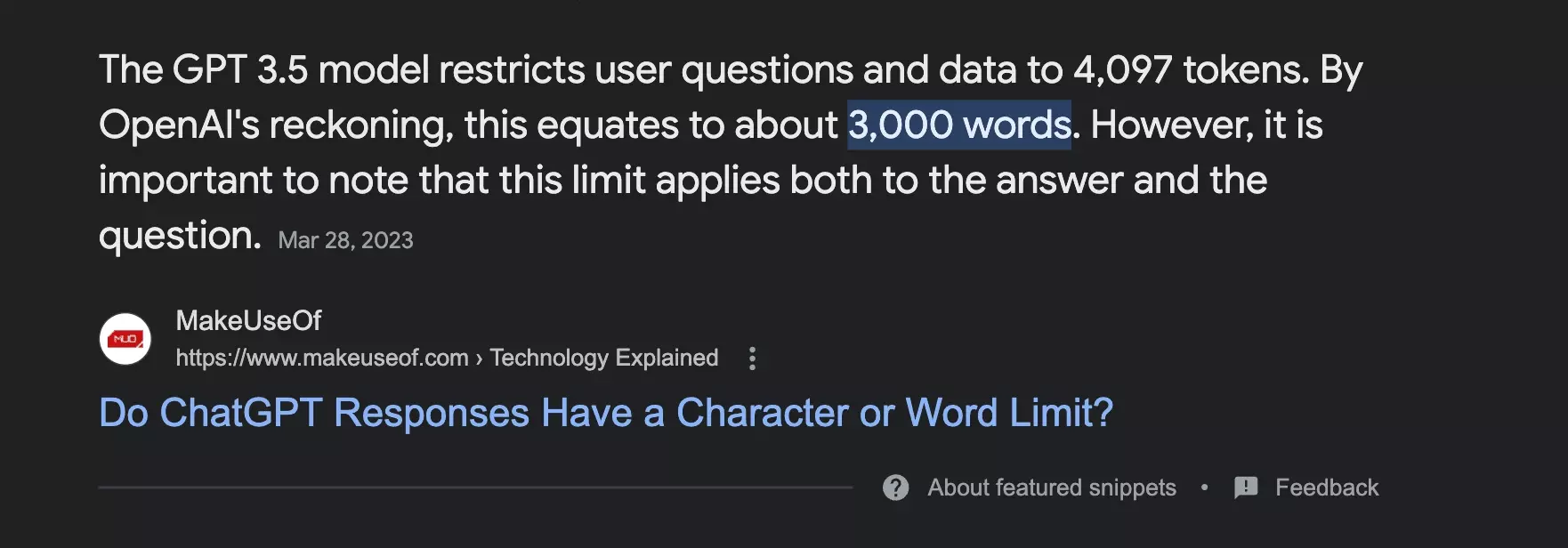
But what is the maximum size that ChatGPT can accommodate?
After a quick Google search, it appears that the program can collect:
- 3000 words
- 4097 tokens
Given the uncertainty about the ratio between the number of tokens and words, we will choose a lower limit of 2000 words, and here is the part of the code that will limit the size of the text content:
MAX_GPT_WORDS = 2000 ... class pricingPagesGPTScraper: ... def reduce_text_size(self, text): assert text words = re.findall(r'\w+', text) if len(words) > MAX_GPT_WORDS: initial_characters = len(text) size_ratio = len(words)/MAX_GPT_WORDS print('/!\\ text too large! size being divided by %s' % size_ratio) max_characters = int(initial_characters//size_ratio) text = text[:max_characters] return textf
The code works as follows:
- We get the text from the HTML code of the previous part
- With a regex, we calculate the number of words in the text
- We find the limit of characters necessary
- We cut the text at this limit
And that's it!
The text is now reduced, cut by approximately 30-40% of its size.
Short and sweet.
$ python3 chatgpt_powered_product_page_universal_scraper.py Starting text size: 22328 /!\ text too large! size being divided by 1.788 Ending text size: 12487f
Our text is of good size, we'll now submit it to ChatGPT, so that it can fetch the right information.
Let's get to the prompt!
5. Fetching information with ChatGPT
It's time to interact with ChatGPT!
In this part, we will generate a first prompt, which will allow us to interact with ChatGPT, which will fetch in the text provided, the main information of the product page, namely
- article_title
- article_url
- article_price
And in order to facilitate the programmatic processing of the data, here is the first prompt we will use:
Find the main article from this product page, and return from this text content, as JSON format:
article_title
article_url
article_price
... COMPLETION_URL = 'https://api.openai.com/v1/chat/completions' AMAZON_URL = 'https://www.amazon.com/dp/B0BZVZ6Z8C' PROMPT = """Find the main article from this product page, and return from this text content, as JSON format: article_title article_url article_price %s""" class pricingPagesGPTScraper: ... def fill_prompt(self, text): assert text prompt = PROMPT % text return prompt def get_gpt(self, prompt): headers = { 'Authorization': 'Bearer %s' % OPENAI_API_KEY, } json_data = { 'model': 'gpt-3.5-turbo', 'messages': [ { "role": "user", "content": prompt } ], 'temperature': 0.7 } response = requests.post(COMPLETION_URL, headers=headers, json=json_data) assert response.status_code == 200 content = response.json()["choices"][0]["message"]["content"] return contentf
We run the program, and this time the result is amazing, here is what we get:
$ python3 chatgpt_powered_product_page_universal_scraper.py [get_html] https://www.amazon.com/dp/B0BZVZ6Z8C Starting text size: 13730 /!\ text too large! size being divided by 1.056 Ending text size: 13001 { "article_title": "Barbecue Grill, American-Style Braised Oven Courtyard Outdoor Charcoal Grilled Steak Camping Household Charcoal Grill Suitable for Family Gatherings", "article_url": "https://www.amazon.com/dp/B0BZVZ6Z8C", "article_price": "$108.89" }f
A perfectly structured JSON, with 3 elements
- article_title
- article_url
- article_price
And when we go to the page, we find these elements there:
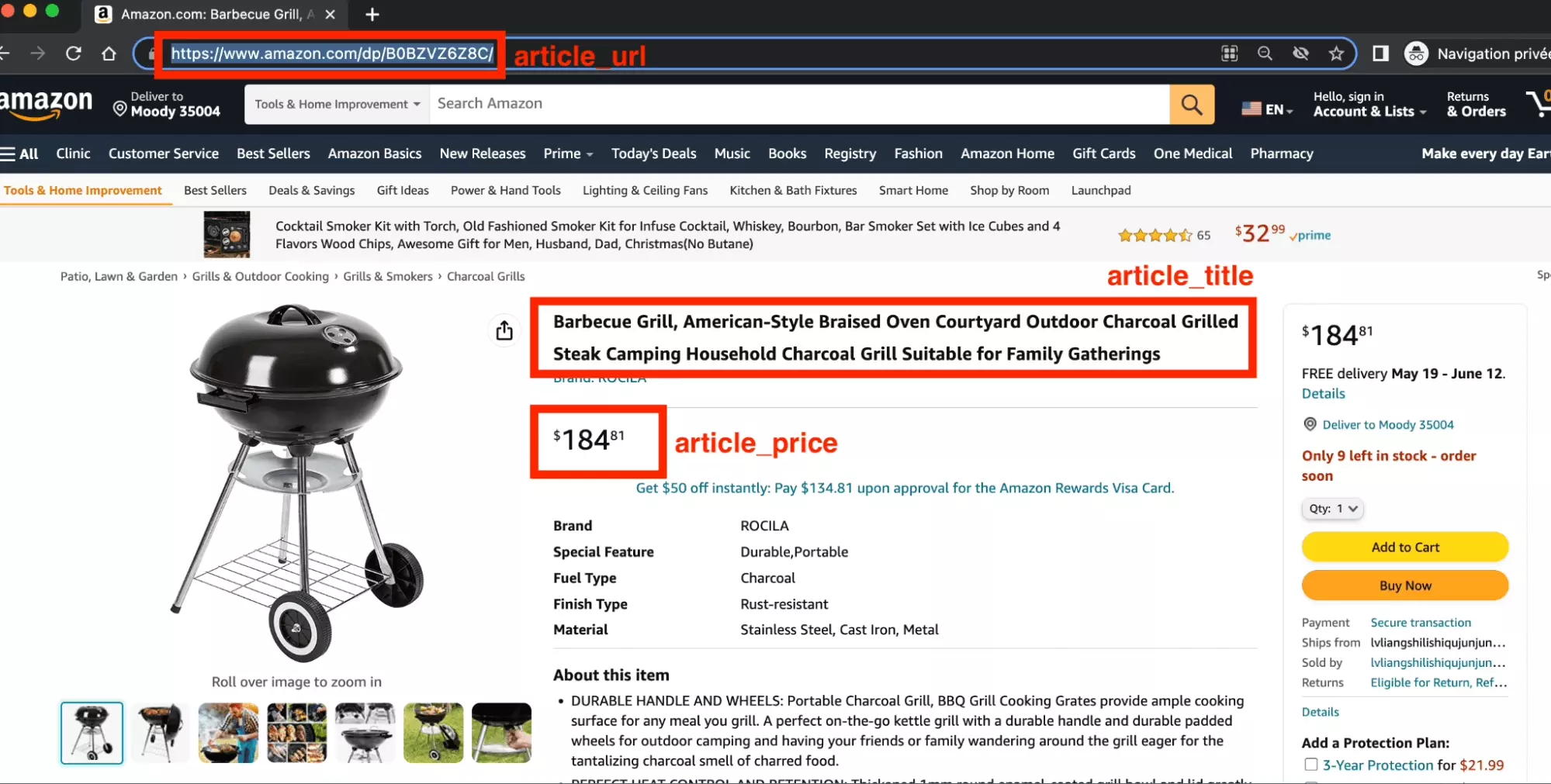
The account is good, beautiful!
6. Add dynamic variables
The Amazon article is good. But maybe it's a fluke.
How to test any url?
We will first consolidate our method, to keep only one final method:
... class pricingPagesGPTScraper: ... def main(self, url): assert url html = self.get_html(url) text = self.convert_html_to_text(html) text = self.reduce_text_size(text) prompt = self.fill_prompt(text) answer = self.get_gpt(prompt) return answerf
Then at the level of the main function, we will get the url mentioned in the command line:
import argparse ... def main(): argparser = argparse.ArgumentParser() argparser.add_argument('--url', '-u', type=str, required=False, help='product page url to be scraped', default='https://www.amazon.com/dp/B09723XSVM') args = argparser.parse_args() url = args.url assert url pp = pricingPagesGPTScraper() answer = pp.main(url) print(answer) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
Did our program work 1 time by chance, or is it really robust? Let's find out immediately.
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.ebay.com/itm/165656992670 [get_html] https://www.ebay.com/itm/165656992670 Starting text size: 11053 Ending text size: 11053 { "article_title": "Portable mangal brazier 10 skewers steel 2.5 mm grill BBQ case for free", "article_url": "", "article_price": "US $209.98" } ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
We are missing the URL here, but for the rest it worked perfectly:
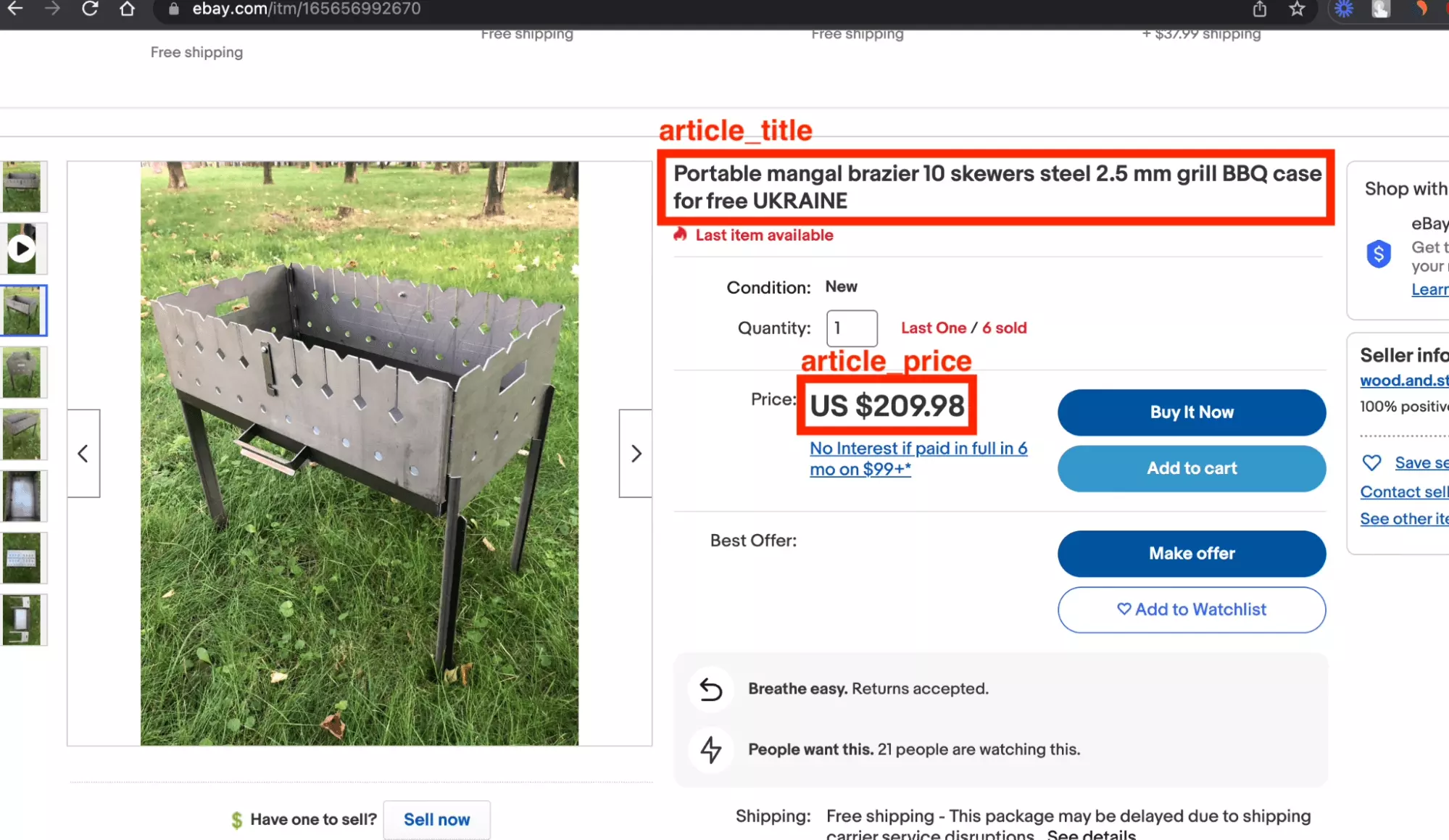
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.walmart.com/ip/1146797 [get_html] https://www.walmart.com/ip/1146797 Starting text size: 1948 Ending text size: 1948 { "article_title": "Weber 14\" Smokey Joe Charcoal Grill, Black", "article_url": null, "article_price": "USD$45.99" } ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
And the same thing, a success, with the good price of the product and the title, the URL being not available :
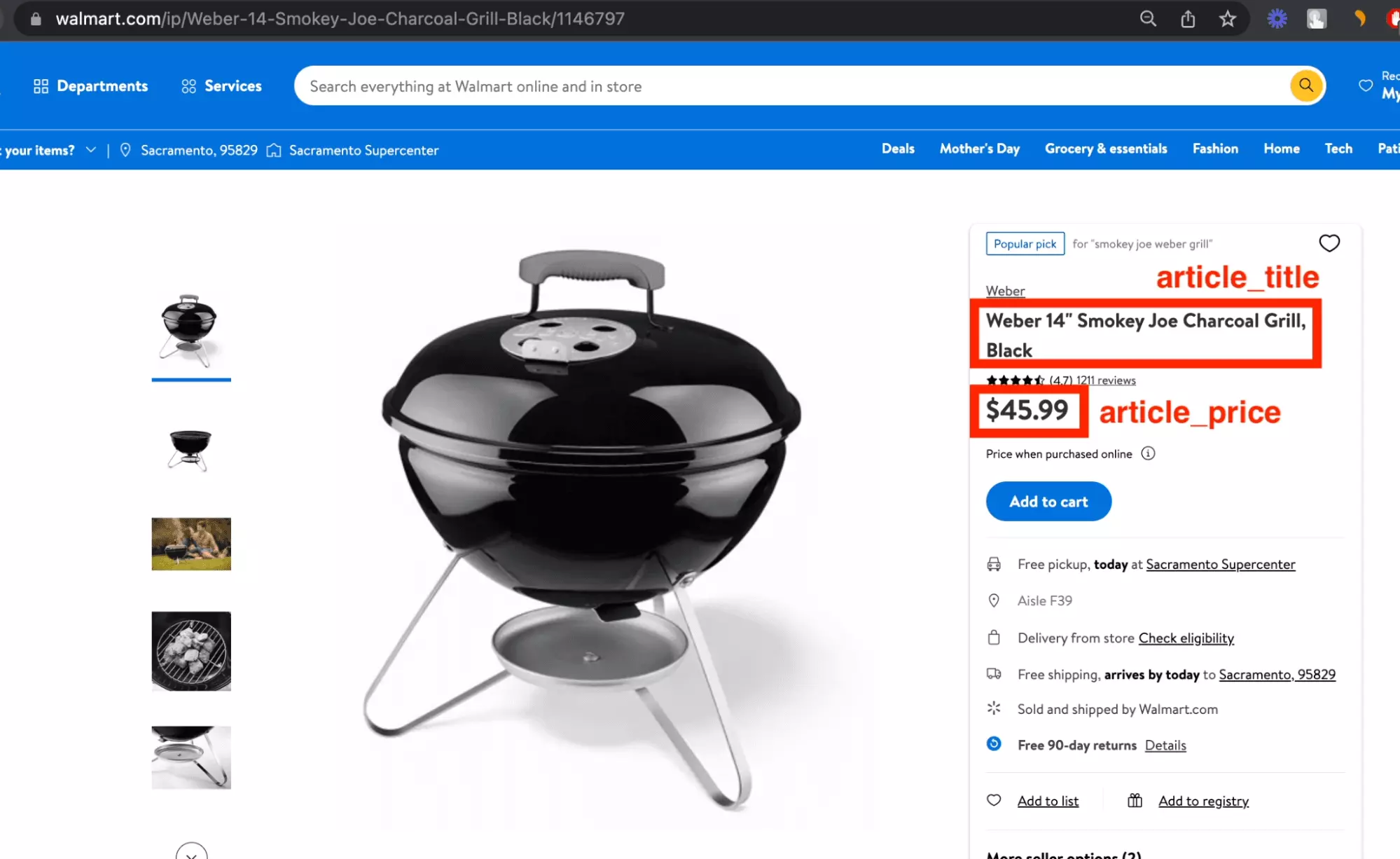
On 3 tries, we have a solid return, with :
✅3 titles ✅3 prices 🔴1 url
Not perfect, but more than satisfactory. It works!
Benefits
As seen in the previous section, automatic scraping of any product page works superbly with ChatGPT and Python!
What are the benefits of this solution?
First of all, as presented in the introduction, this solution brings an important flexibility. Indeed, there is no need to develop a dedicated robot for each type of product page. You just have to provide the HTML code of a page and get the benefits.
Consequently, this allows massive cost reduction, especially when you have many different types of pages. For example, with 100 product pages of different structure, the solution will be particularly competitive in terms of cost.
Limitations
If the advantages are certain, what are the disadvantages?
First of all, and as we saw in the tutorial, the result is imprecise. Out of 3 URLs provided, we obtained only 1 URL, the two other URLs being unfortunately missing.
More seriously, if we do a test with this URL, here is the result we get:
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.amazon.com/dp/B0014C2NBC { "article_title": "Crocs Unisex-Adult Classic Clog", "article_url": "https://www.amazon.com/dp/B07DMMZPW9", "article_price": "$30.00$30.00 - $59.99$59.99" }f
The format of the price is strangely pasted, which makes it difficult to exploit:
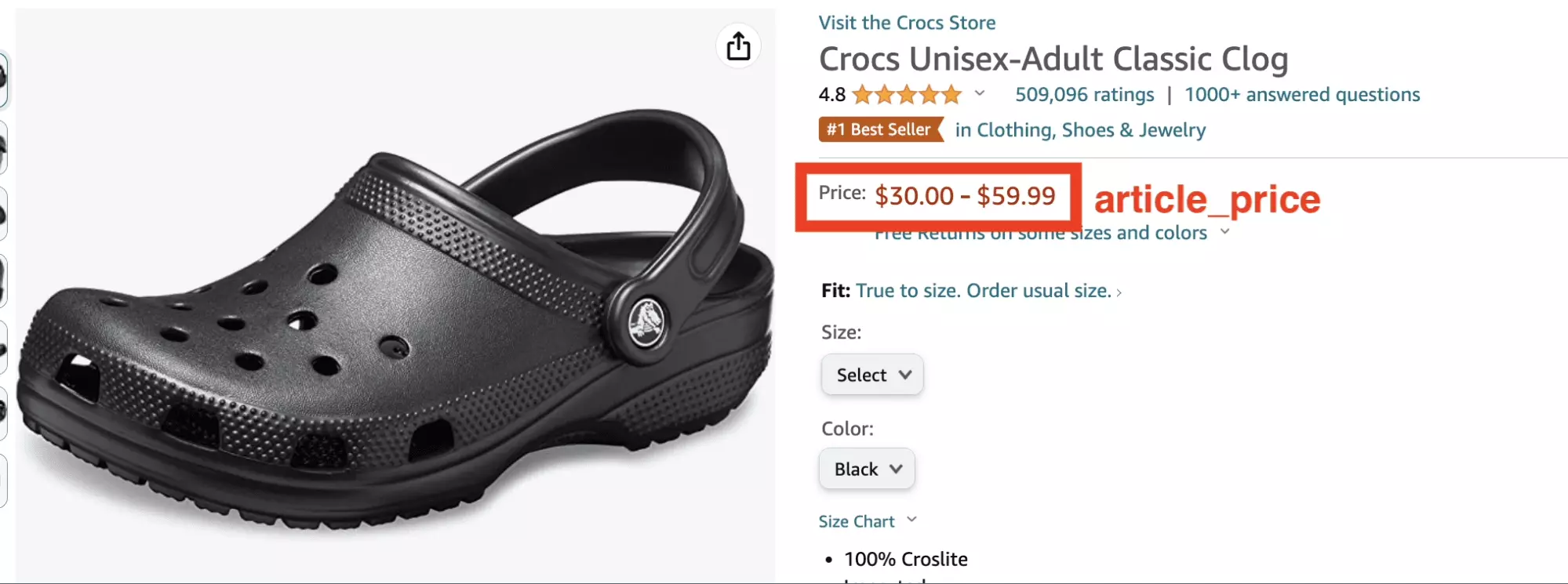
And the result is even more inaccurate when you add additional attributes: ranking, number of reviews, score, categories, associated products, delivery date etc.
Moreover, if you multiply the collections on several product pages, it quickly appears that the result is unstable.
For example, if we modify the prompt to obtain the URL of the product image, we will obtain the following results after two attempts:
$ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.amazon.com/dp/B0BQZ9K23L { "article_title": "Stanley Quencher H2.0 FlowState Stainless Steel Vacuum Insulated Tumbler with Lid and Straw for Water, Iced Tea or Coffee, Smoothie and More", "article_image_url": null } $ python3 chatgpt_powered_product_page_universal_scraper.py --url https://www.amazon.com/dp/B0BQZ9K23L { "article_title": "Stanley Quencher H2.0 FlowState Stainless Steel Vacuum Insulated Tumbler with Lid and Straw for Water, Iced Tea or Coffee, Smoothie and More", "article_image_url": "https://m.media-amazon.com/images/I/61k8q3y1V7L._AC_SL1500_.jpg" }f
One shot yes, one shot no.
Then, as seen in the tutorial, the size of the input text is limited. If in most cases, it is OK, it can happen that the text of the product page is cut in 2, and lose 50% of its initial size.
Starting text size: 26556
/!\ text too large! size being divided by 2.088
Ending text size: 12718
In these situations, one can imagine that this will have a negative impact on the rendering.
Finally, the price is high. As seen in the FAQ section, it takes about $4 for 1000 products. This is a competitive price when you think that you can scrape any product page.
FAQ
How much does it cost?
This solution is nice, but how much does it cost?
Is it legal?
Yes, it is entirely legal!
How fast does it work?
We did the experiment with 3 barbecue URLs. The charm of summer.
https://www.ebay.com/itm/165656992670 https://www.walmart.com/ip/1146797 https://www.amazon.com/dp/B09723XSVM
And we calculated the execution speed for each URL.
Here is the result:
$ python3 test_speed_chatgpt_powered_product_page_universal_scraper.py amazon.com 10.951031041999999 walmart.com 5.695792166000002 ebay.com 7.3706024580000005f
It is therefore necessary to count on average 7 seconds per request. To be confirmed of course with a larger sample.
Is there a no-code solution?
No, not for the moment. But it will be soon!
Conclusion
And that's the end of this tutorial!
In this tutorial, we saw how to scrape any product page with Python, and OpenAI's amazing artificial intelligence, ChatGPT. And retrieve the main attributes: the product name, the price, and the product URL.
Let's face it, if you need to scrape the main attributes from 100 product pages, all of which come from different websites, this is a real revolution. It's solid, (rather) reliable, inexpensive and rather fast.
Be careful though, if you need to collect precise information, always accurate, with a large volume spread over the same site(s), you may end up paying more than you expected, for unreliable information.
Happy scraping!
🦀