
How to bypass a (simple) Captcha with Python3 and Pytesseract?
A CAPTCHA, which stands for Completely Automated Public Turing test to tell Computers and Humans Apart, is a test used by websites around the world to determine if a user is truly human.
Prerequisites
In order to complete this tutorial from start to finish, be sure to have the following items installed on your computer.
You can click on the links below, which will take you either to an installation tutorial or to the site in question.
To clarify the purpose of each of the above: python3 is the computer language with which we will scrape the pdf, and SublimeText is a text editor. Sublime.
Let's play!
Setup
We will proceed as follows:
- Install open-cv
- Install pytesseract
- Install tesseract
- Download the captcha
For the first 2 libraries, you just have to type the following commands in the console:
$ pip3 install opencv-python $ pip3 install pytesseractf
Finally, you need to install tesseract, which is an OCR, the acronym for Optical Character Recognition, i.e. the technology that will allow you to decipher the characters of the Captcha.
Mac OS
$ brew install tesseractf
Linux
sudo apt update sudo apt install tesseract-ocr sudo apt install libtesseract-devf
And here we are, the libraries are installed!
And there you have it, the bookstores are set up!
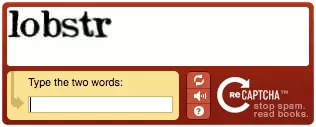
Let us now decipher this image. And prove our humanity. Without any human intervention.
🤖
Step-by-step Guide
We will go through 3 distinct steps:
- Resize
- Close
- Threshold
With the 3 transformations as follows:

1. Resize
First, we will resize the image. Resizing the image allows the OCR algorithm to detect the character or number strokes in the input image.
The code as follows:
filename = 'lobstr.jpeg' img = cv2.imread(filename) gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) (h, w) = gry.shape[:2] gry = cv2.resize(gry, (w*2, h*2))f
2. Close
Closing is a morphological operation to remove small holes in the input image. If we look carefully the characters 'l' and 'b' are composed of many small holes.
Code:
cls = cv2.morphologyEx(gry, cv2.MORPH_CLOSE, None)f
3. Threshold
We will apply a simple threshold to binarize the image. Our goal is to remove any remaining artifacts from the image that impair readability.
Code:
thr = cv2.threshold(cls, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]f
4. Decrypt
Finally, once the image is clear enough, we decode the message with the tesseract library for Python.
And we print the decoded message in the console:
txt = image_to_string(thr) print(txt)f
Code
Here is the complete code:
import cv2 from pytesseract import image_to_string # pip3 install opencv-python # pip3 install pytesseract # brew install tesseract filename = 'lobstr.jpeg' img = cv2.imread(filename) gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) (h, w) = gry.shape[:2] gry = cv2.resize(gry, (w*2, h*2)) cls = cv2.morphologyEx(gry, cv2.MORPH_CLOSE, None) thr = cv2.threshold(cls, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] txt = image_to_string(thr) print(txt)f
To execute the code:
- Download the .py code
- Change the path of the image
- Launch the script via the command line
And this is what will appear directly on your terminal:
$ python3 bypass-captcha-pytesseract-tutorial.py lobstrf
Eureka!
✨
Limitations
However, this script only works for simple captchas. Let's try it with an Amazon Captcha, below:
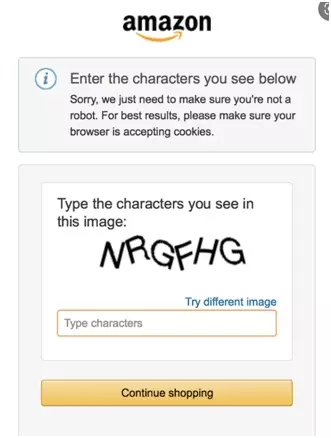
We run the script:
$ python3 bypass-captcha-pytesseract-tutorial.py nrrthf
Which simply does not work.
🤷♀️
Conclusion
And that's the end of the tutorial!
In this tutorial, we've seen how to bypass a simple Captcha with Python3 and Pytesseract, programmatically.
If you have any questions, or if you need a custom, robust and scalable scraping service that can bypass even the most robust captchas, contact us here.
Happy scraping!
🦀