
Best Yelp Scrapers 2026 [No-code Edition]
TL;DR
- I tested no-code Yelp scrapers across data, pricing, speed, scalability, and ease of use
- I skipped browser extensions, API-only tools, and desktop apps — only dedicated no-code scrapers with a Yelp template made the cut
- lobstr.io is the most complete option — most data fields, the fastest at 51 minutes per 1,000 results, and the only one with deduplication
- lobstr.io is also the only tool that pulls business emails directly from business websites
- Apify is not reliable — zero results twice on URL input, and a 37% failure rate in a single test run
- Bright Data returns rich data, but not reliable — 1 in 3 records came back missing, and two of its three scrapers returned zero results
- ScrapeHero Cloud is reliable for small runs and the only tool with rating_histogram — but not built for volume
- WebScraper.io is reliable for small runs — but the most expensive option on this list
Most no-code Yelp scrapers look like they'll work — until you actually run them.
Zero results. Partial data. No explanation why.
If you've been there, you're not alone.
So I tested the best no-code Yelp scrapers — across data, pricing, speed, scalability, and ease of use — to save you the trial and error.
Here's what actually worked.
| Criteria | lobstr.io | Apify | Bright Data | ScrapeHero Cloud | WebScraper.io |
|---|---|---|---|---|---|
| Data fields | 30 | 9 | 29 | 23 | 10 |
| Data reliability | 💯 | 👎 | 👎 | 💯 | 💯 |
| Email scraping | ✅ | ❌ | ❌ | ❌ | ❌ |
| Entry price /1K | $2.00 | $1.00 | $1.50 | $8.33 | $11 |
| Scale price /1K | $0.50 | $1.00 | $1.00 | $2.50 | $5.50 |
| Free plan | ✅ | ✅ | ❌ | ✅ | ❌ |
| Speed /1K | 51 min | 2,667 min | 94 min | 308 min | 182 min |
| CSV import | ✅ | ❌ | ✅ | ❌ | ✅ |
| Concurrency slots | ✅ | ❌ | ❌ | ❌ | ✅ |
| Scalability | ✅ | ❌ | ❌ | ✅ | ✅ |
| Stability | 💯 | 👎 | 👎 | 👍 | 💯 |
| Deduplication | ✅ | ❌ | ❌ | ❌ | ❌ |
| Scheduling | ✅ | ✅ | ❌ | ✅ | ✅ |
| Export options | 👍 | 💯 | 💯 | 👍 | 👍 |
| Integrations | 👍 | 💯 | 💯 | 💯 | 💯 |
| Customer support | 💯 | 👍 | 👍 | 👎 | 👍 |
But hold up...is it legal?
⚠️ Disclaimer
The information in this section is for general informational purposes only. It reflects publicly available sources and my own interpretation of them.
It does not constitute legal advice and should not be treated as such. Laws vary by jurisdiction and can change.
If you need guidance on compliance, data use, contracts, or platform-specific risks, consult a qualified legal professional who can evaluate your situation in detail.
Is it legal to scrape yelp?
Yes — if you're collecting public data responsibly.
Where things get risky is what you do after you collect it.
Copying or republishing reviews and photos can raise copyright issues.
If the content is public, you're not bypassing technical barriers, and you use the data responsibly, you're usually on safer ground.
For a deeper breakdown, see the linked article.
Now, here's how I filtered the list down to the best scrapers.
How did I choose the best Yelp scrapers?
First, I looked at what people actually struggle with when scraping Yelp.
From there, I narrowed it down to five recurring pain points:
- Data
- Affordability
- Scalability
- Speed
- Ease of use
For data, I checked what fields each tool returns—and whether the output is clean, flat, and usable right away without extra wrangling.
For affordability, I reduced pricing to a simple metric: cost per 1,000 results.
I also compared both entry-level and higher-volume pricing so it stays fair whether you scrape occasionally or run jobs regularly.
For scalability, I measured both input scale and output scale. Input scale is bulk import and how well the workflow holds up with large URL lists.
For output scale, I convert speed into a monthly ceiling using 8h/day of active runtime (≈14,400 min/month) to estimate how many results each tool can produce in a month.
Then I noted whether the tool has concurrency controls to push throughput, or if scaling is mostly linear.
For speed, I timed how long each tool took to return results and projected that to a 1,000-result run.
For ease of use, I looked at the whole workflow — from setting up the first result to exporting the data — paying attention to input clarity, result limiting, scheduling, export options, and integrations.
I also checked customer support: what channels exist, and what real users say about them in reviews.

Next, I made a list of every tool I could find via Google and AI recommendations.

Browser extensions and visual scrapers might work on lightly protected pages, but they're not reliable against a site like Yelp.
And API-only tools? You need to write code, who are we kidding.
So I excluded the usual suspects—visual scrapers, Chrome extensions, desktop apps, and API-only tools.
I'm only comparing no-code tools with dedicated templates.
Best Yelp scrapers
| Criteria | lobstr.io | Apify | Bright Data | ScrapeHero Cloud | WebScraper.io |
|---|---|---|---|---|---|
| Data fields | 30 | 9 | 29 | 23 | 10 |
| Data reliability | 💯 | 👎 | 👎 | 💯 | 💯 |
| Email scraping | ✅ | ❌ | ❌ | ❌ | ❌ |
| Entry price /1K | $2.00 | $1.00 | $1.50 | $8.33 | $11 |
| Scale price /1K | $0.50 | $1.00 | $1.00 | $2.50 | $5.50 |
| Free plan | ✅ | ✅ | ❌ | ✅ | ❌ |
| Speed /1K | 51 min | 2,667 min | 94 min | 308 min | 182 min |
| CSV import | ✅ | ❌ | ✅ | ❌ | ✅ |
| Concurrency slots | ✅ | ❌ | ❌ | ❌ | ✅ |
| Scalability | ✅ | ❌ | ❌ | ✅ | ✅ |
| Stability | 💯 | 👎 | 👎 | 👍 | 💯 |
| Deduplication | ✅ | ❌ | ❌ | ❌ | ❌ |
| Scheduling | ✅ | ✅ | ❌ | ✅ | ✅ |
| Export options | 👍 | 💯 | 💯 | 👍 | 👍 |
| Integrations | 👍 | 💯 | 💯 | 💯 | 💯 |
| Customer support | 💯 | 👍 | 👍 | 👎 | 👍 |
Lobstr.io
| Pros | Cons |
|---|---|
| Only tool that pulls business emails | Only CSV export |
| Most data fields | |
| CSV import | |
| Deduplication built in | |
| Strong live chat support | |
| Fastest | |
| Concurrency slots |
Key features
- 30 data fields per listing
- Collect Contacts toggle pulls business emails
- IS SPONSORED and ADVERTISER STATUS to identify and filter paid placements
- Bulk keyword + location upload via CSV
- Slots to control scraping speed and run multiple inputs in parallel
- Deduplication via unique results toggle
- Schedule recurring scrapes
- Export to CSV or deliver to Google Sheets, Amazon S3, SFTP, or email
- Integrates with Make.com and 3,000+ apps
- Cloud-based, no installation needed
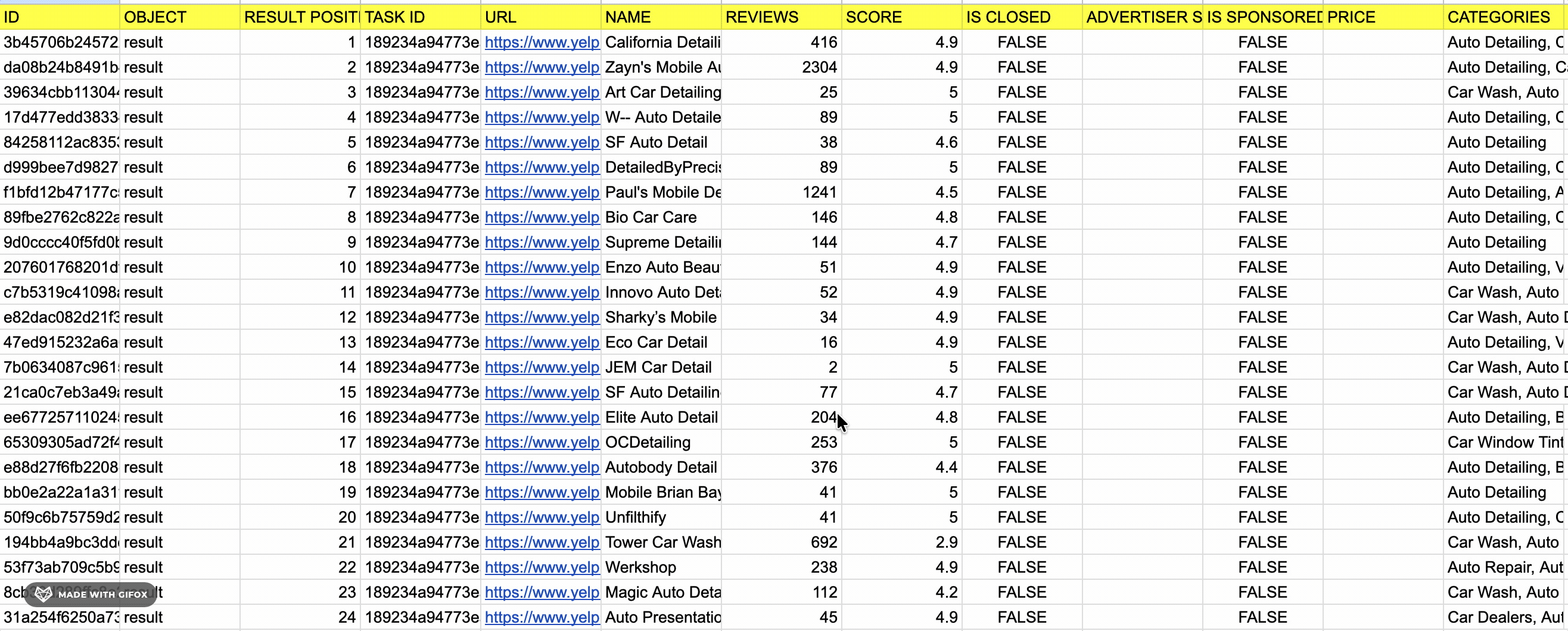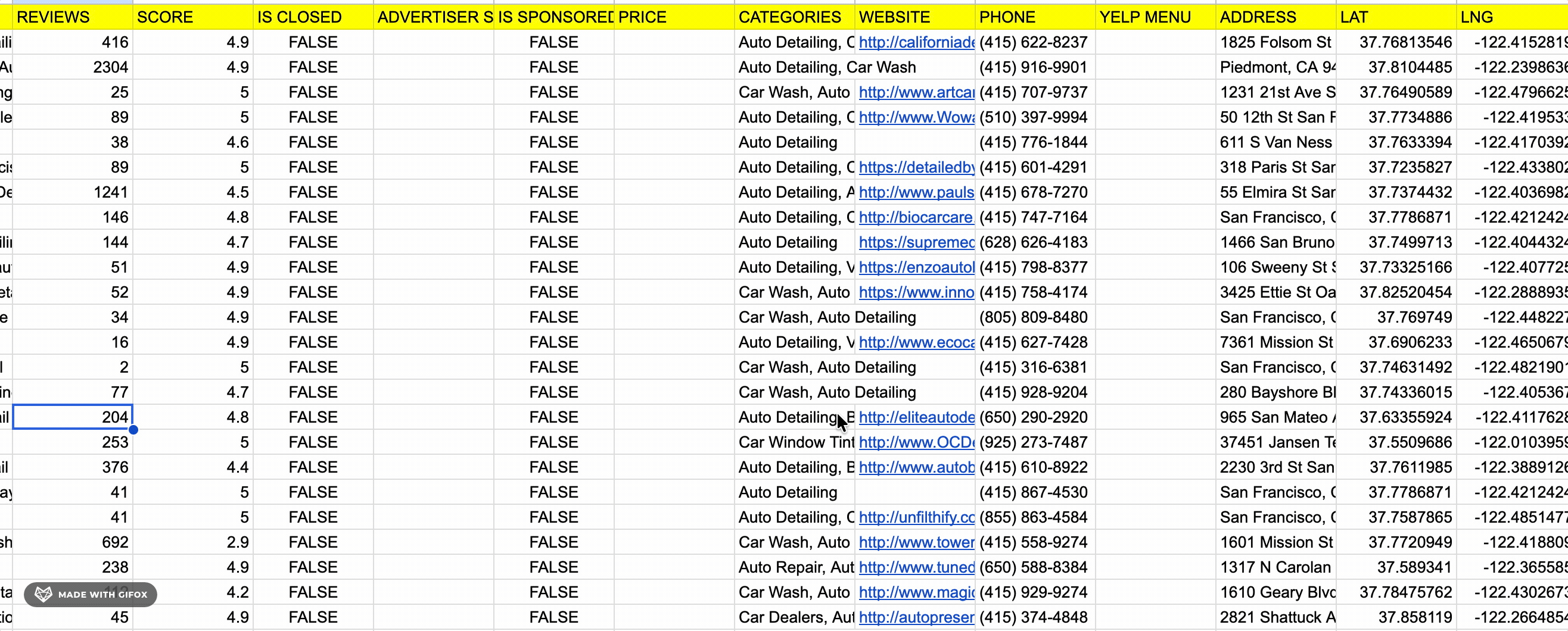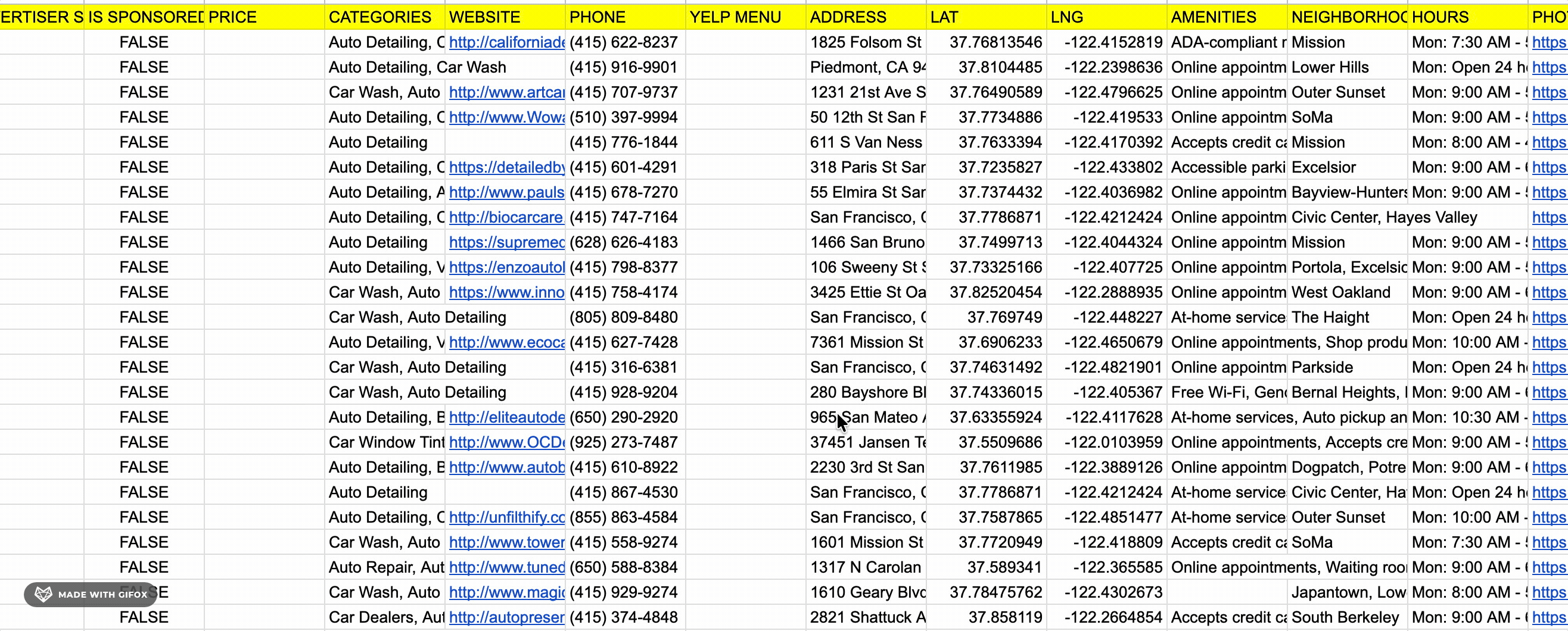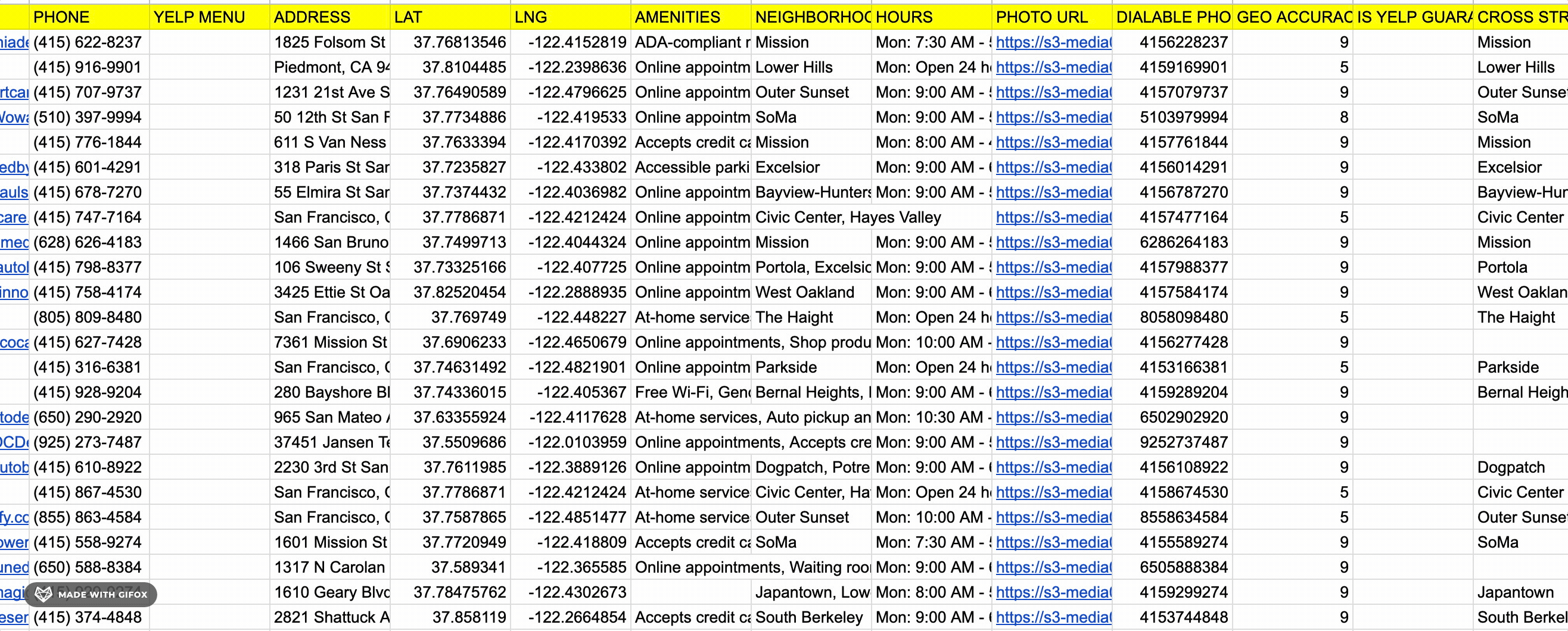
Data
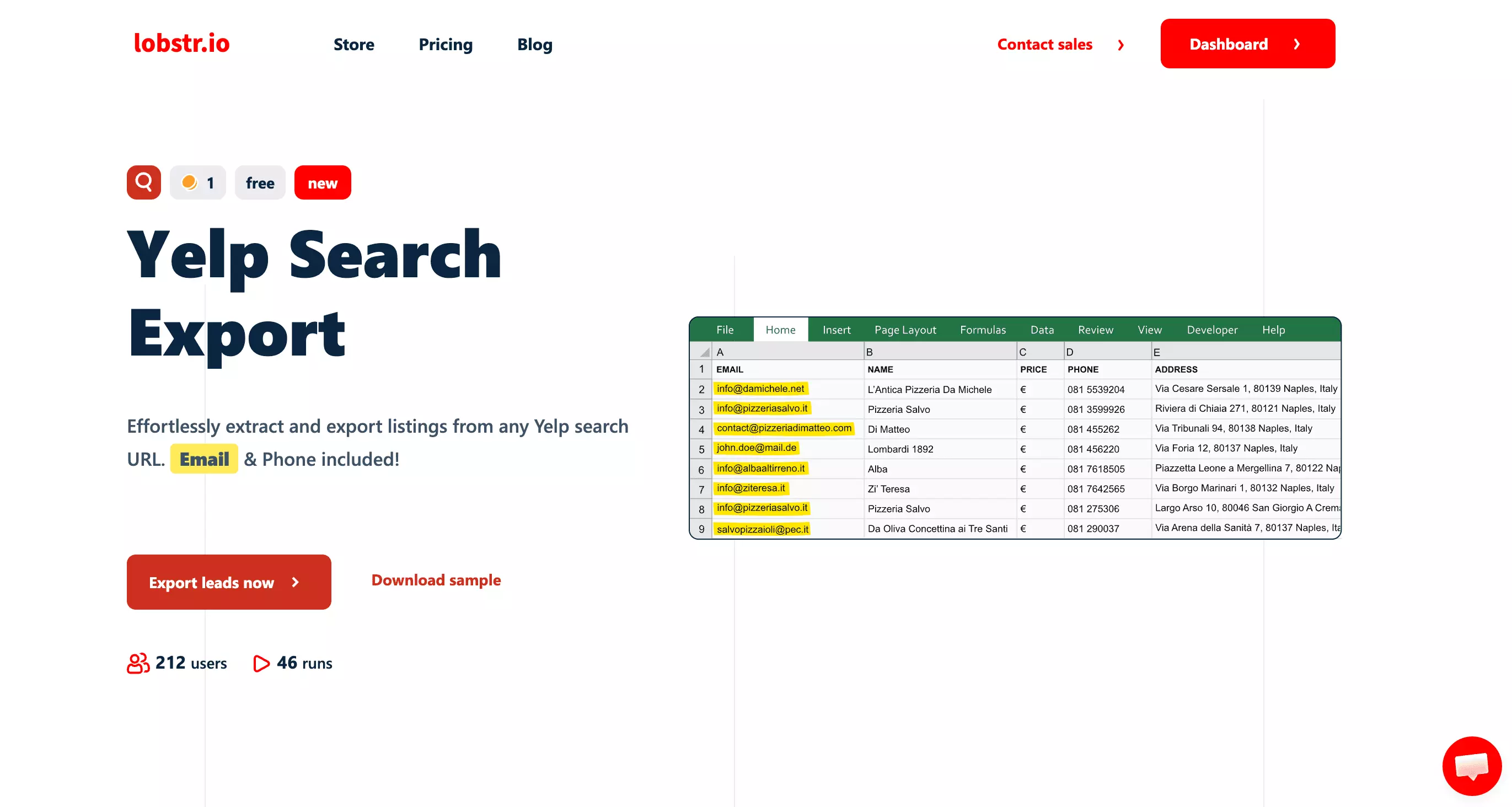
lobstr.io returns 30 fields per listing.
Here are all 30 fields:
| 🔗 URL | 📄 NAME | ⭐ REVIEWS | ⭐ SCORE |
| 📊 IS CLOSED | 📊 ADVERTISER STATUS | 📊 IS SPONSORED | 💰 PRICE |
| 🏷️ CATEGORIES | 🔗 WEBSITE | 📞 PHONE | 🔗 YELP MENU |
| 📍 ADDRESS | 📌 LAT | 📌 LNG | 🏷️ AMENITIES |
| 📍 NEIGHBORHOODS | 📅 HOURS | 🖼️ PHOTO URL | 📞 DIALABLE PHONE |
| 📊 GEO ACCURACY | 📊 IS YELP GUARANTEED | 📍 CROSS STREETS | 🖼️ PHOTO COUNT |
| 🖼️ PHOTOS | 📊 IS PERMANENTLY CLOSED | 📊 IS ONLINE BUSINESS | 📝 DESCRIPTION |
| 🖼️ LOGO URL |
lobstr.io has a few exclusive fields that no other tool on this list returns. Here are those fields:
| 📊 IS SPONSORED | 📊 ADVERTISER STATUS | 🔗 YELP MENU | 👤 EMAIL |
IS SPONSORED and ADVERTISER STATUS let you flag paid placements directly in the output, so you can filter them out without a second pass.
It's useful when you're building a lead list and don't want to target advertisers.
YELP MENU returns a direct menu link per business — no additional request needed.
EMAIL isn't pulled from the Yelp page itself.
lobstr.io visits each business's own website to find it — meaning you get a contact address even when Yelp doesn't surface one.
When it's off, EMAIL is blank across all rows.
When it's on, lobstr.io scrapes each business's website for an email address before writing the row.
Affordability
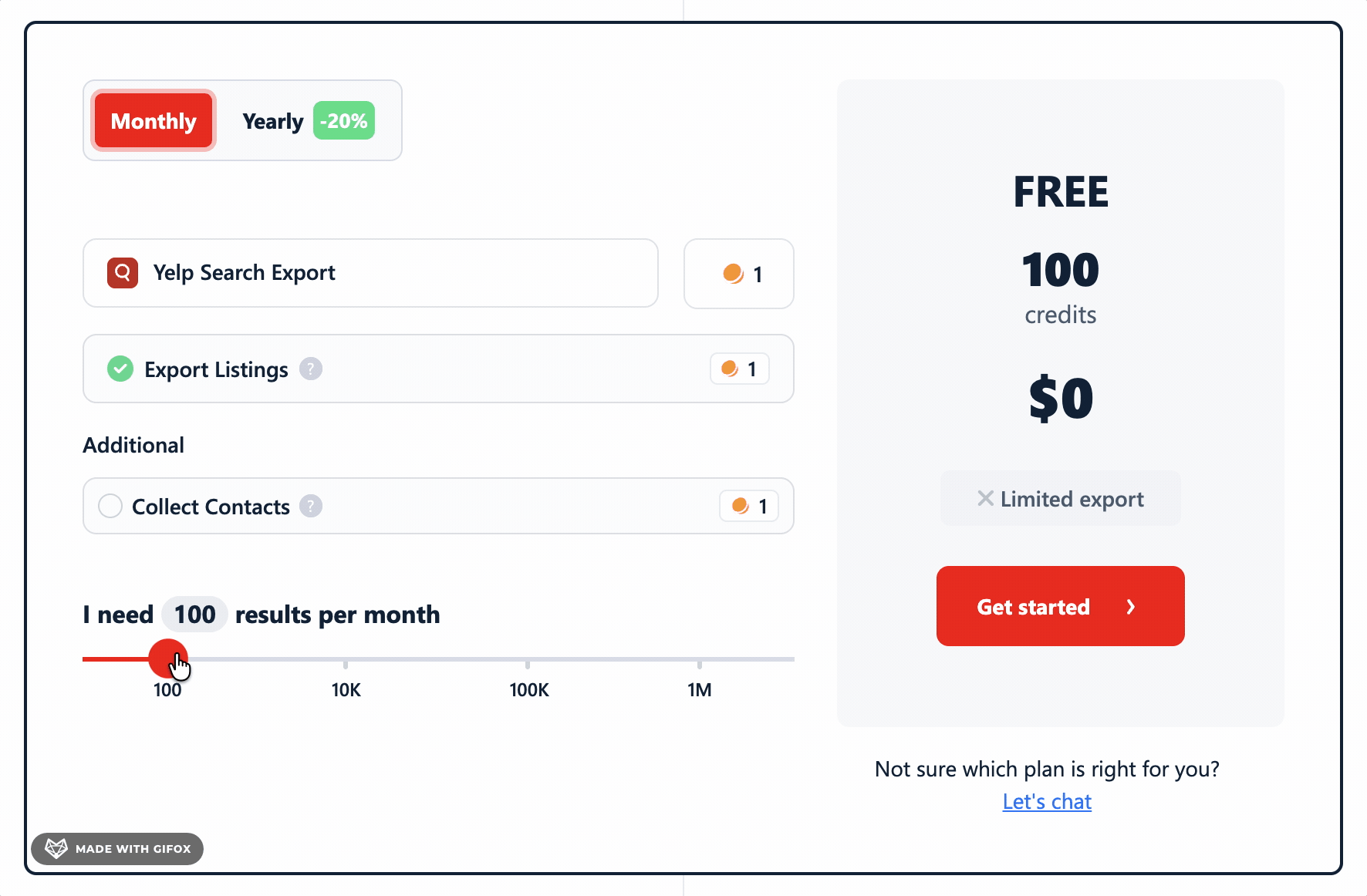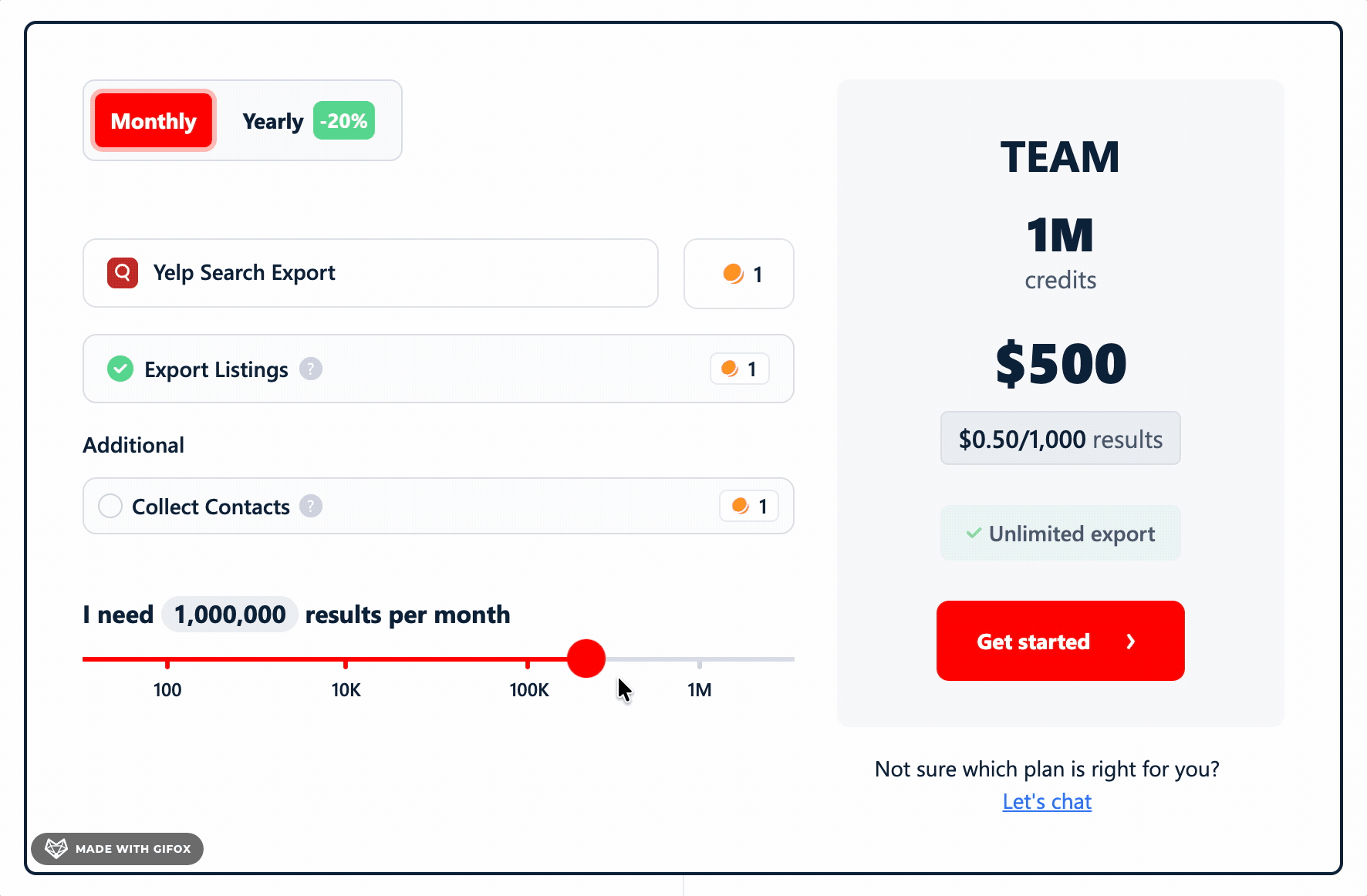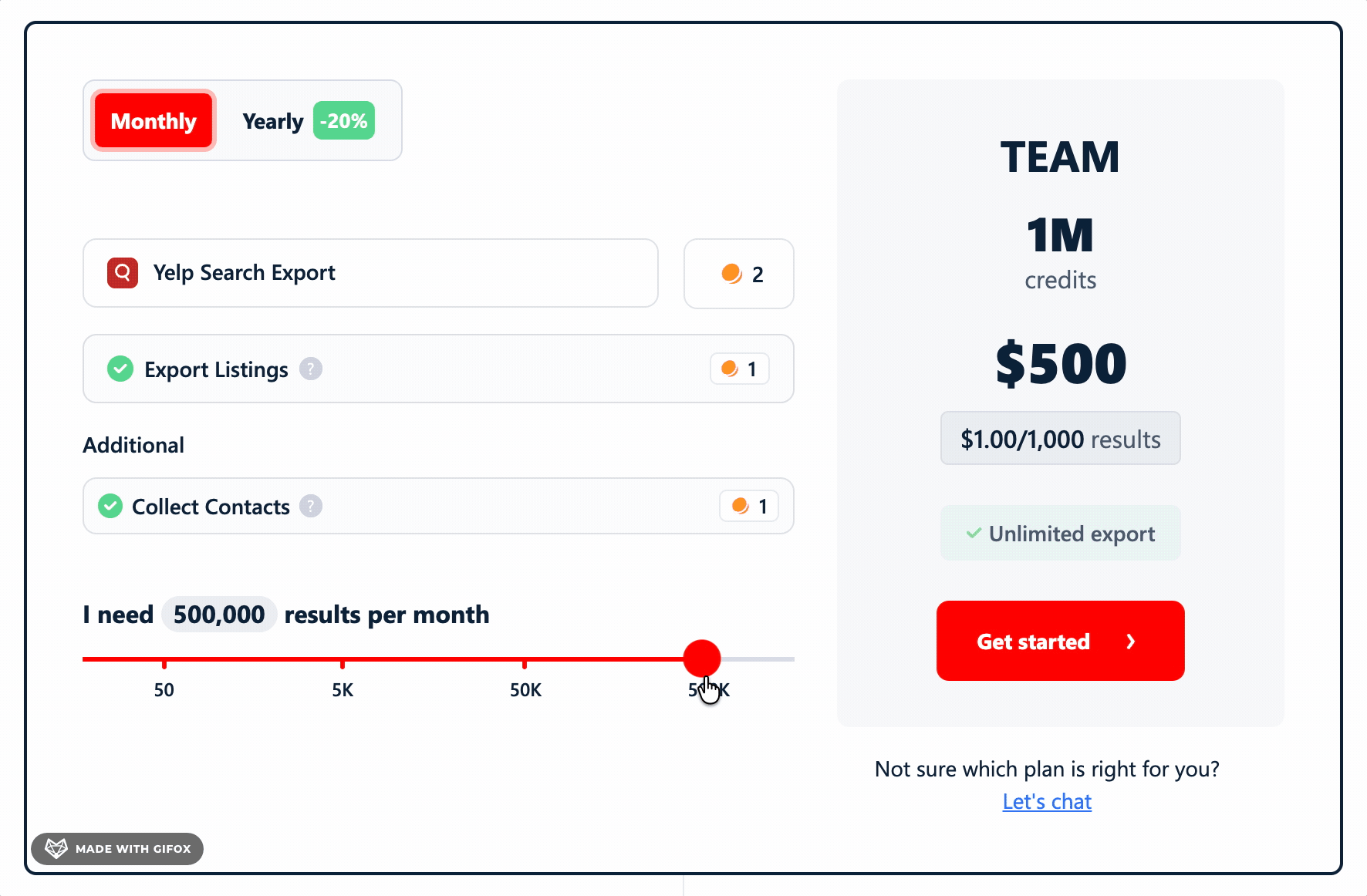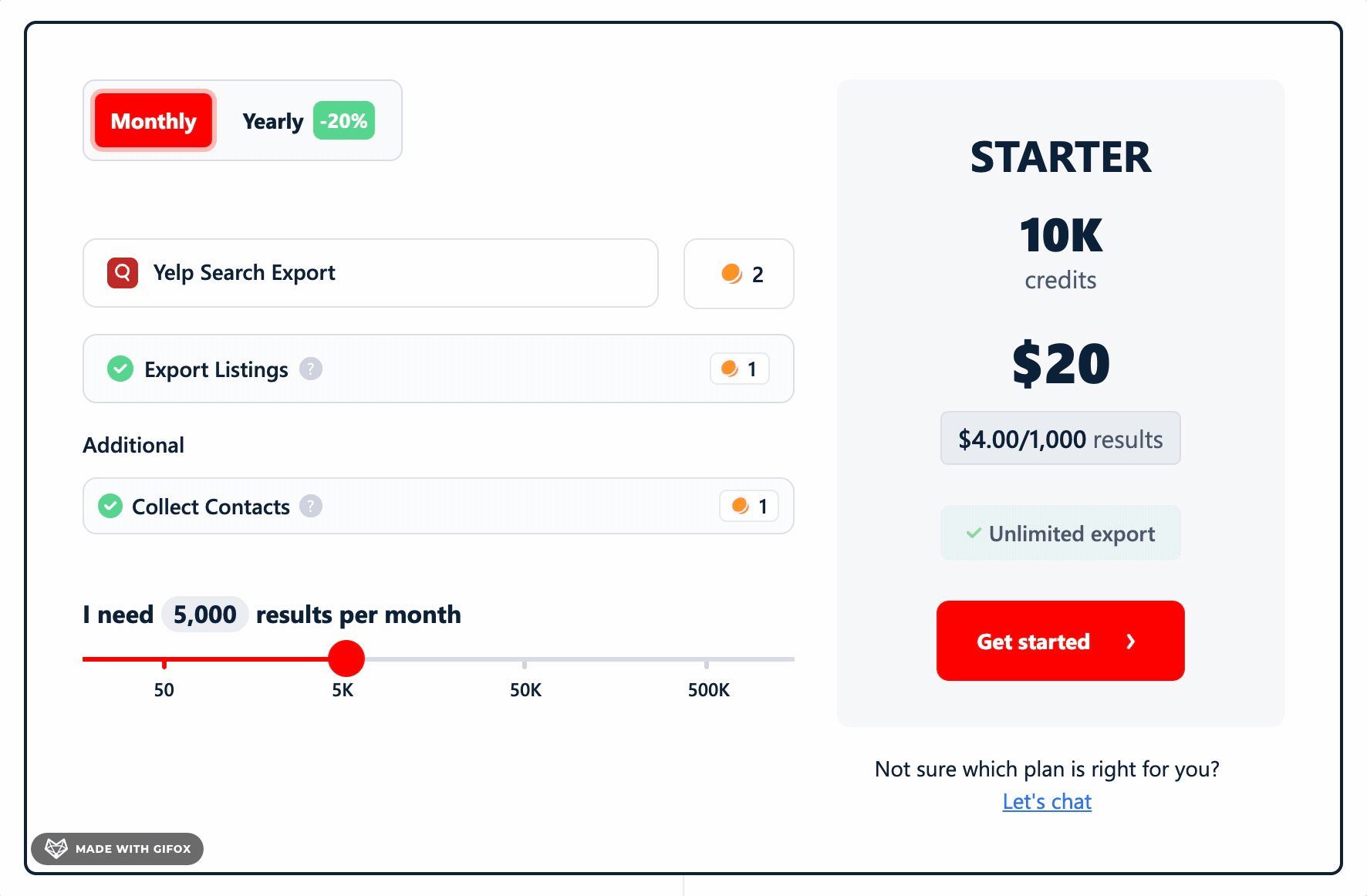
lobstr.io runs on a credit-based subscription model. The cost per result depends on which features you enable.
Without Collect Contacts:
- FREE plan: 100 results per month
- STARTER plan: $2.00 per 1,000 results
- TEAM plan: $0.50 per 1,000 results

With Collect Contacts enabled:
- FREE plan: 50 results per month
- STARTER plan: $4.00 per 1,000 results
- TEAM plan: $1.00 per 1,000 results

The cost doubles when you turn on contact collection.
But it's the only tool on this list that pulls emails directly from business websites.
Scalability
lobstr.io handles large input and lets you push throughput when you need it faster.
On the input side, you upload keywords and locations in bulk via CSV.
On the output side, at 51 minutes per 1,000 results, the baseline ceiling is roughly 282K results/month without contact collection.
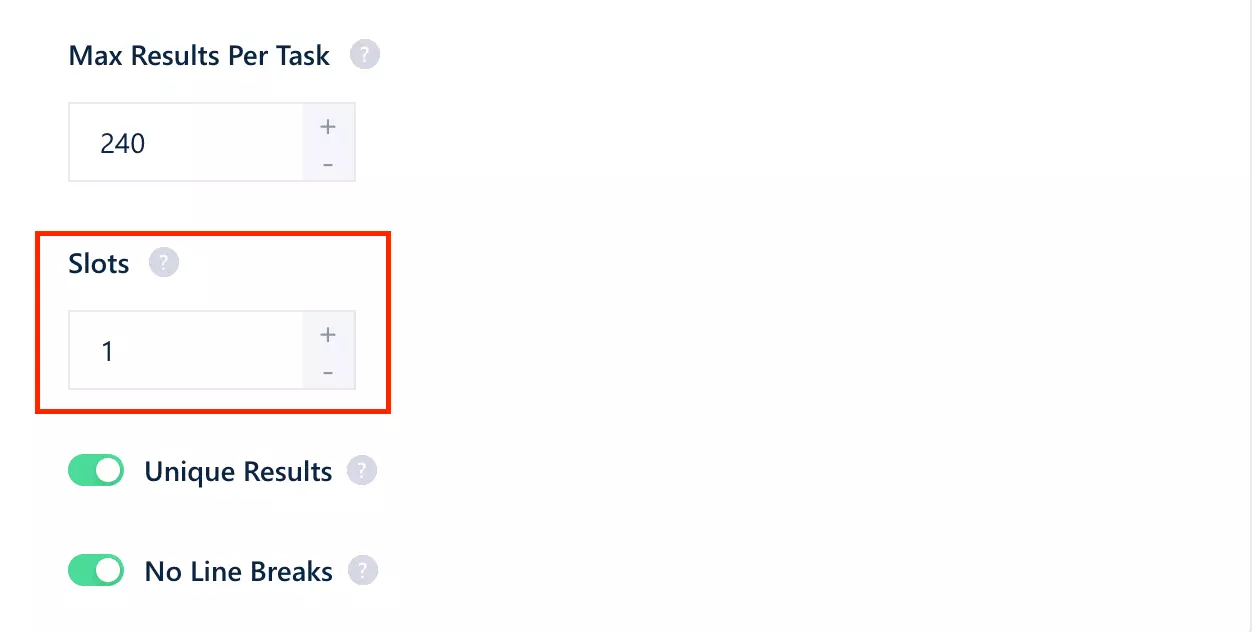
Each Slot adds a parallel scraper, so multiple inputs run at the same time instead of moving through the queue one by one.
lobstr.io is stable at scale.
Ease of use
lobstr.io still uses a guided 4-step setup. It's hard to get lost.
You always know where you are and what comes next.
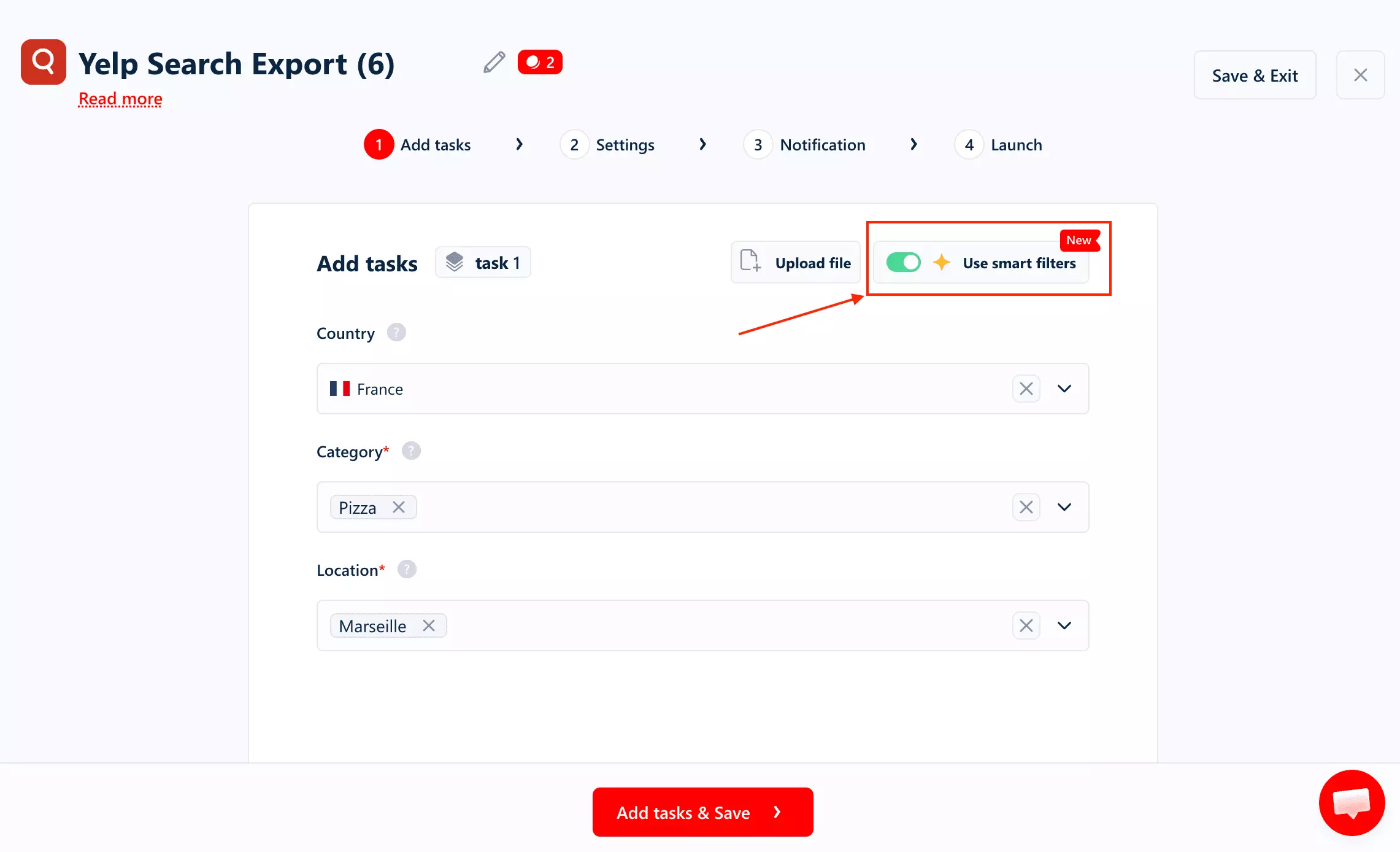
Task creation supports two ways to start:
You enter a keyword and location (or upload a CSV for bulk jobs).
You paste a Yelp search URL and run that exact query.
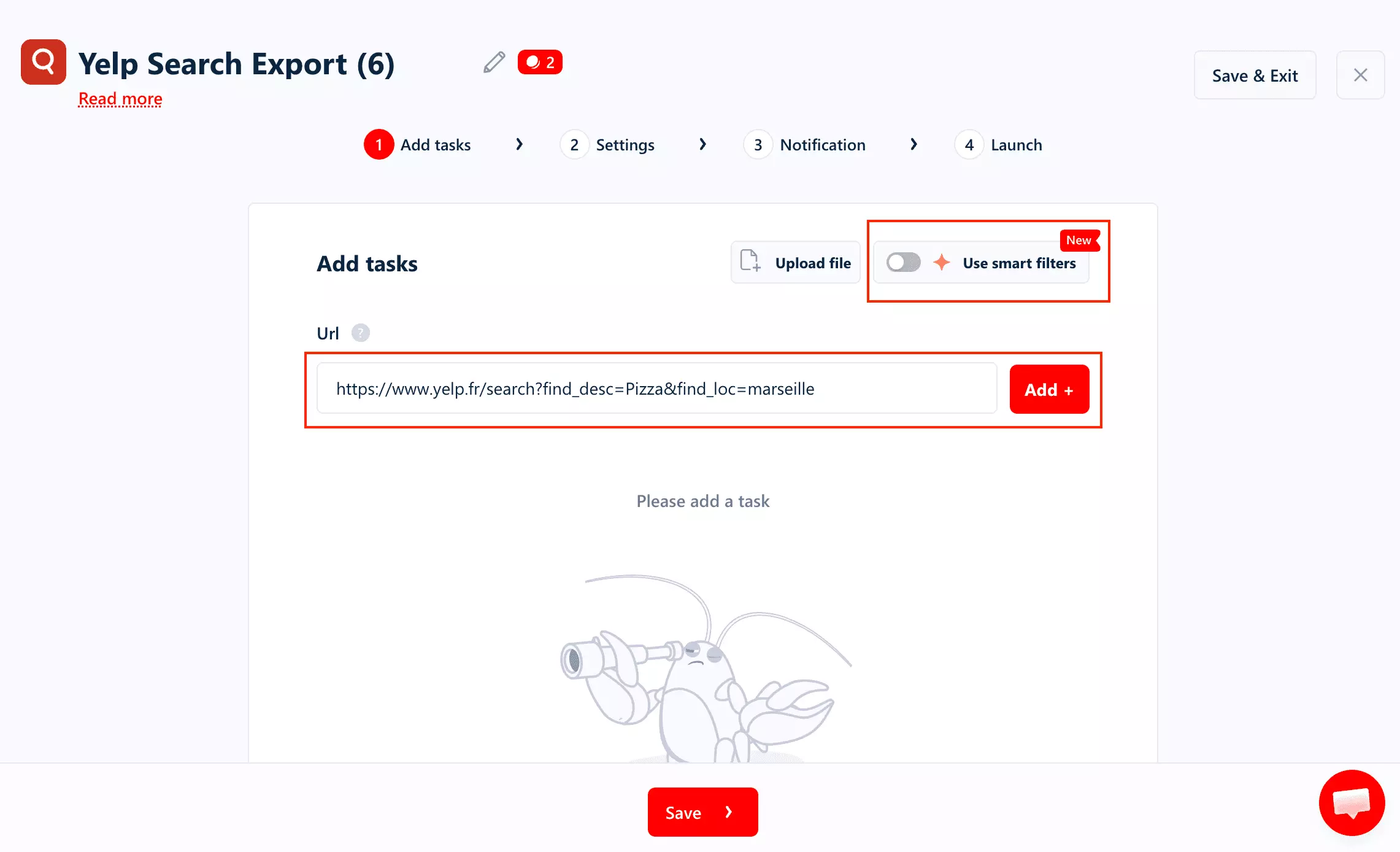
So you can either build the search in lobstr.io, or bring your own pre-built Yelp search and let it do the extraction.
Settings give you real control.
You can keep the run focused on Yelp data, or turn on contact collection when you need enriched lead information.
After that, it's filters—lots of them.
They let you decide what belongs in the export before you spend credits collecting it.
Price tiers ($ to $$$$) help you avoid the wrong market.
Sorting makes your intent explicit.
Distance and attribute toggles make the output less generic.
You can narrow by radius, then layer on flags like good for kids/groups, Wi-Fi, dogs allowed, accessibility, and payment methods.
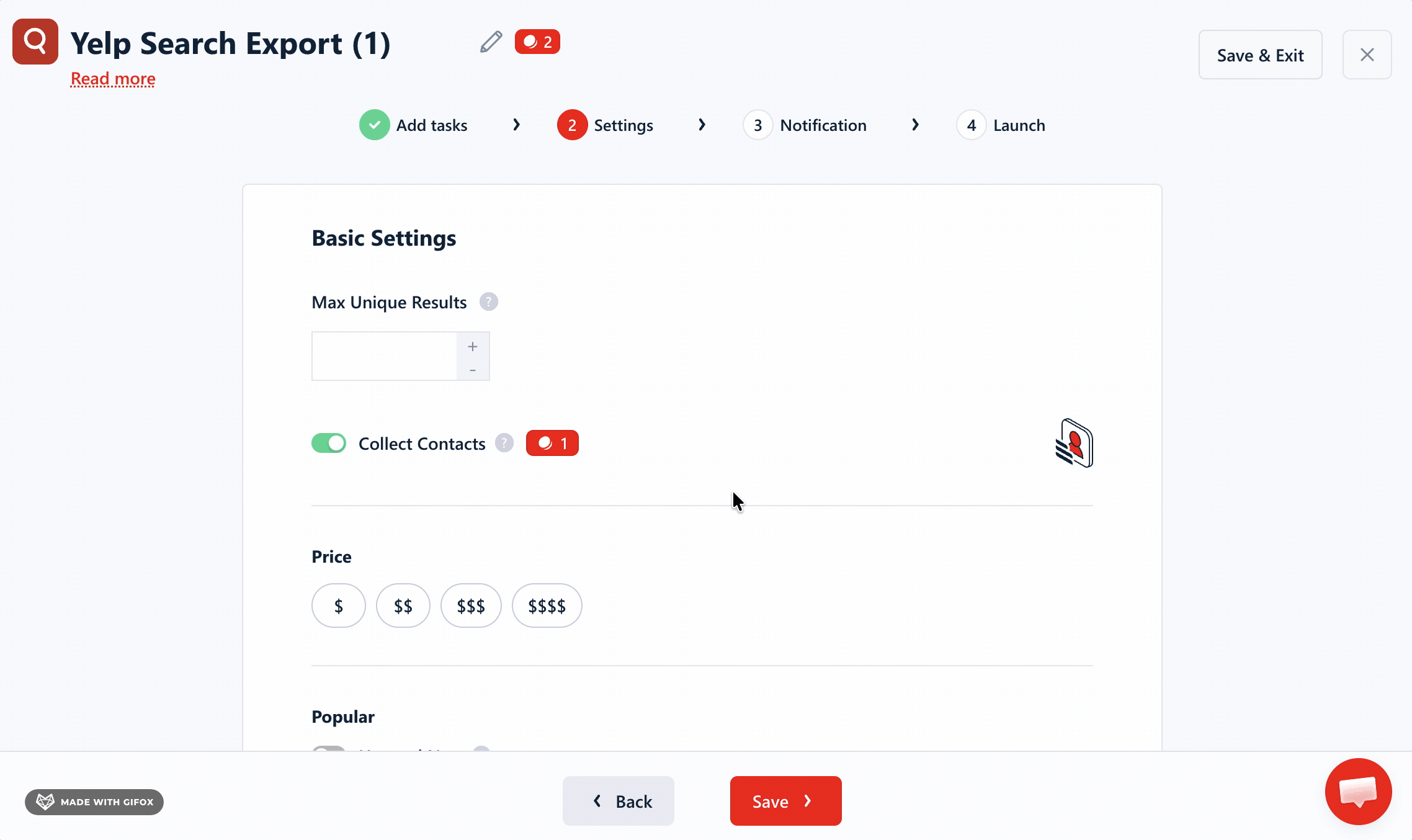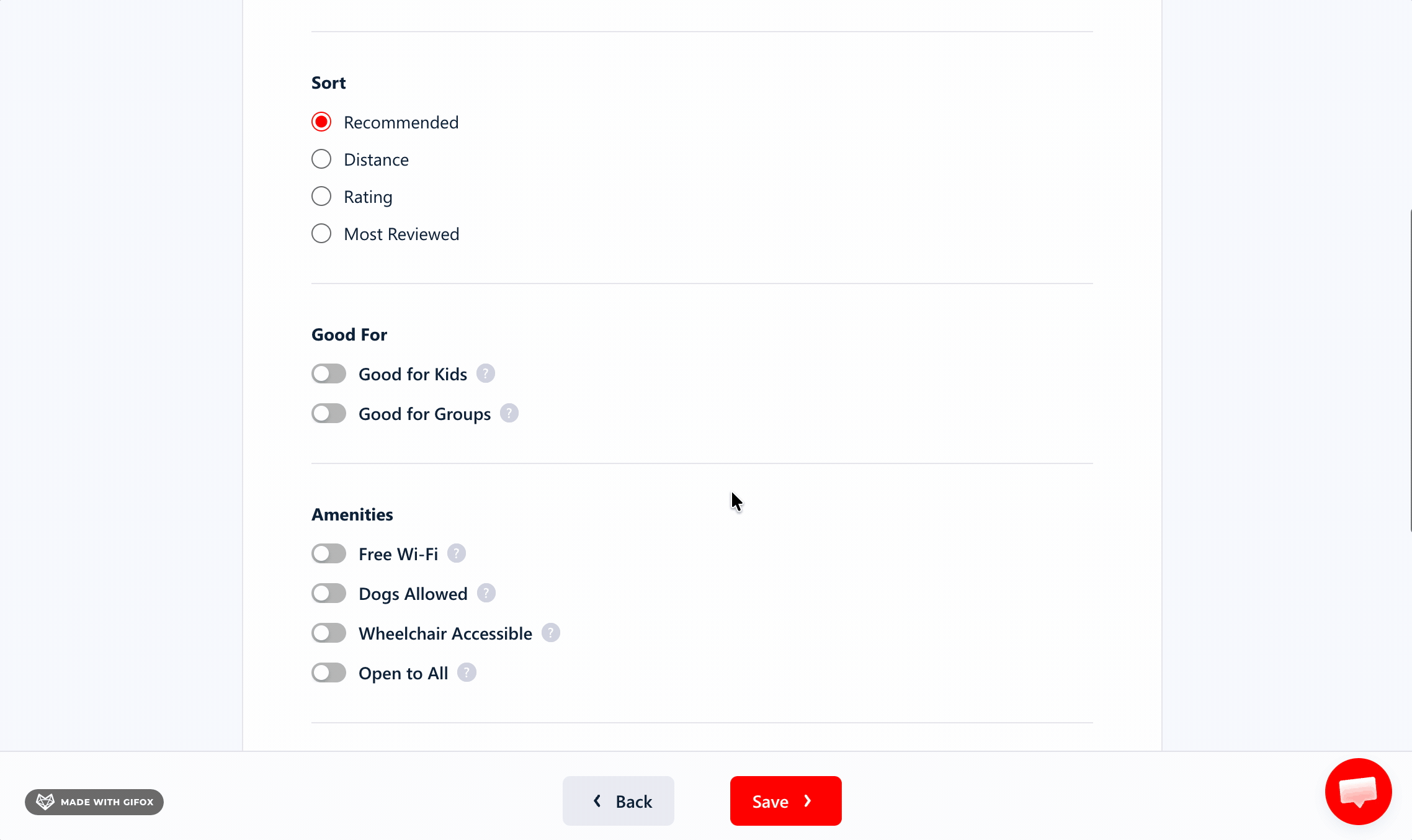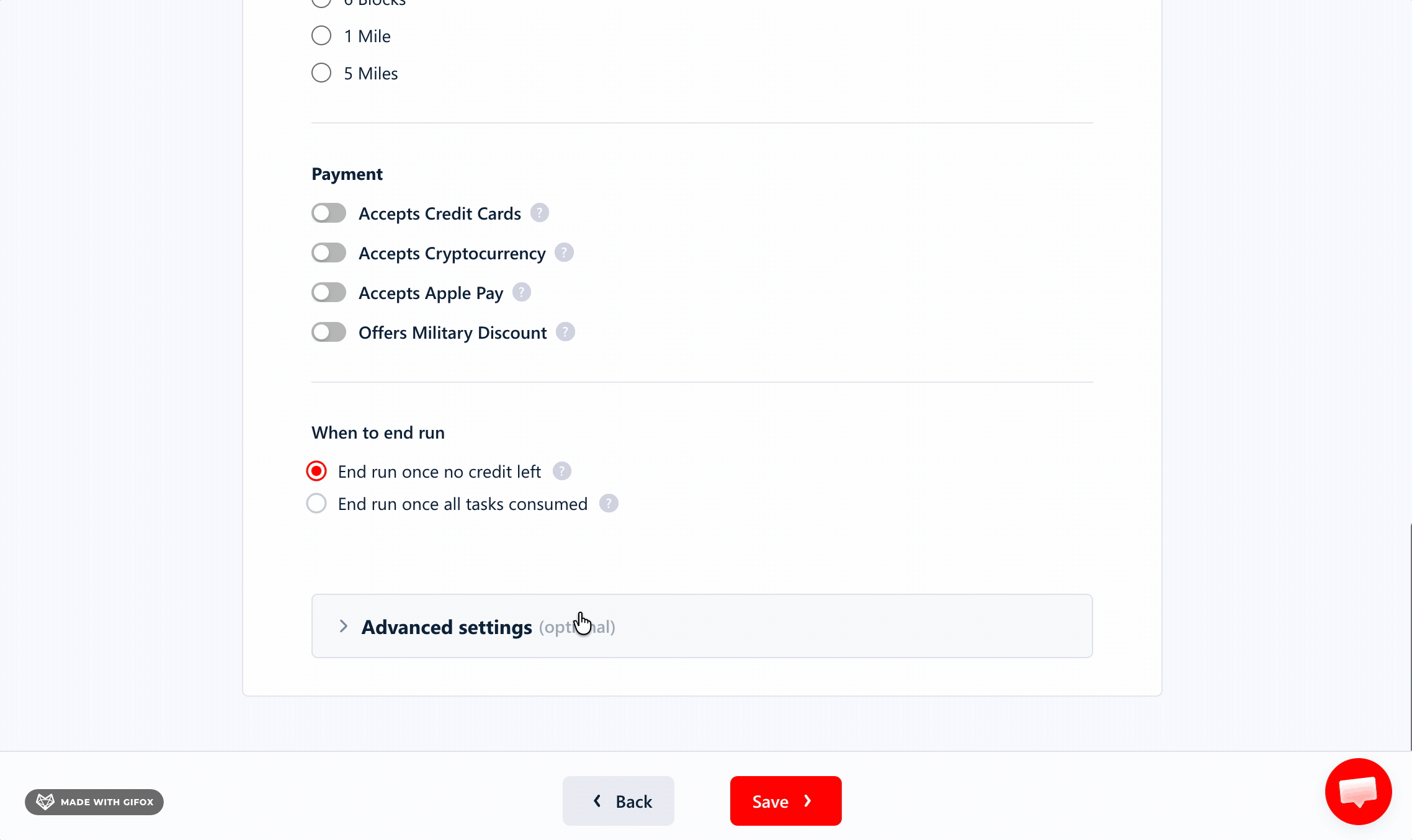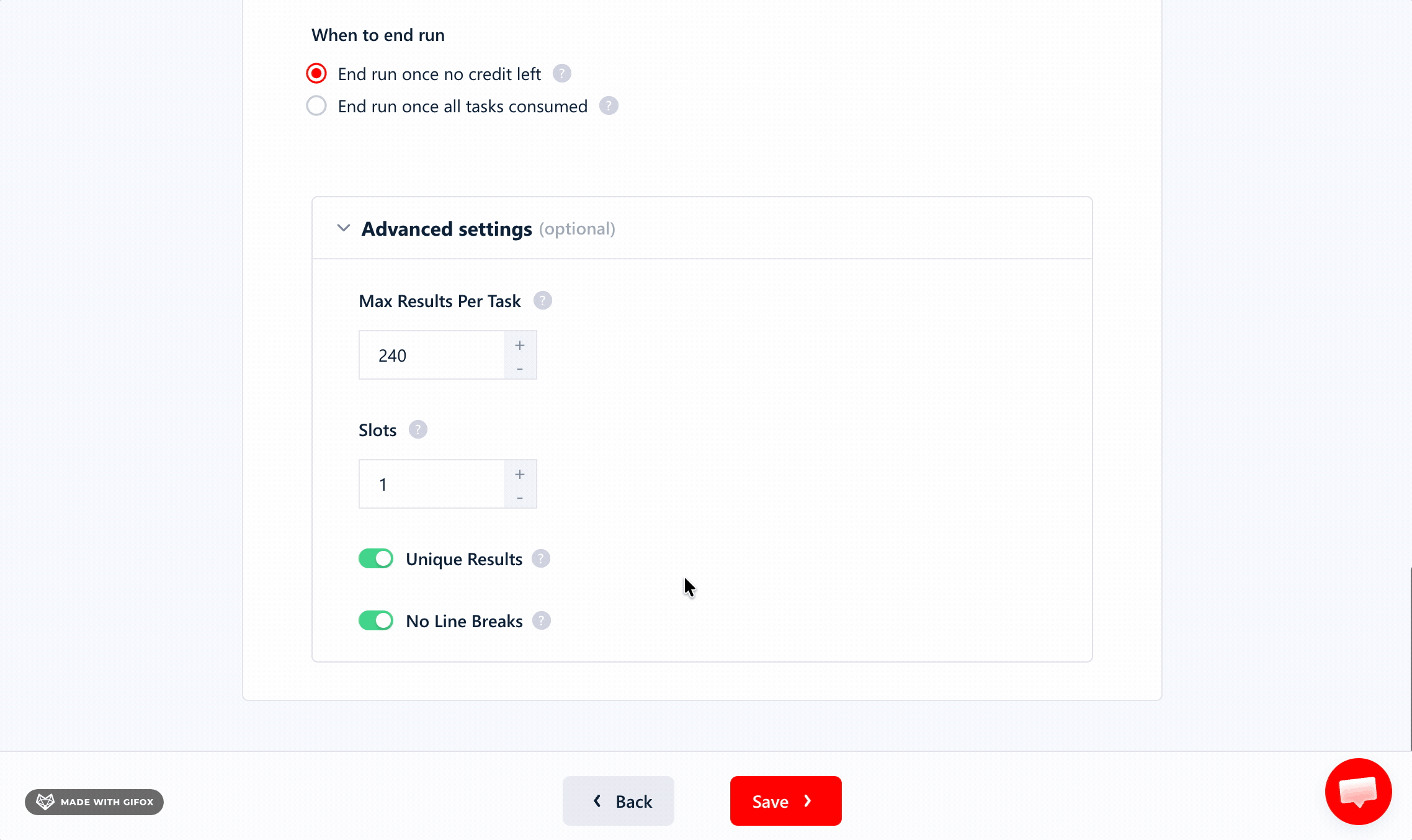
It handles deduplication automatically, so you're not paying for duplicates — or cleaning repeats after export.
Scheduling is built into the launch step. Minutes, hours, days, weeks, or months — configurable with timezone and start time.
Every day or every weekday. Simple, clear choices.
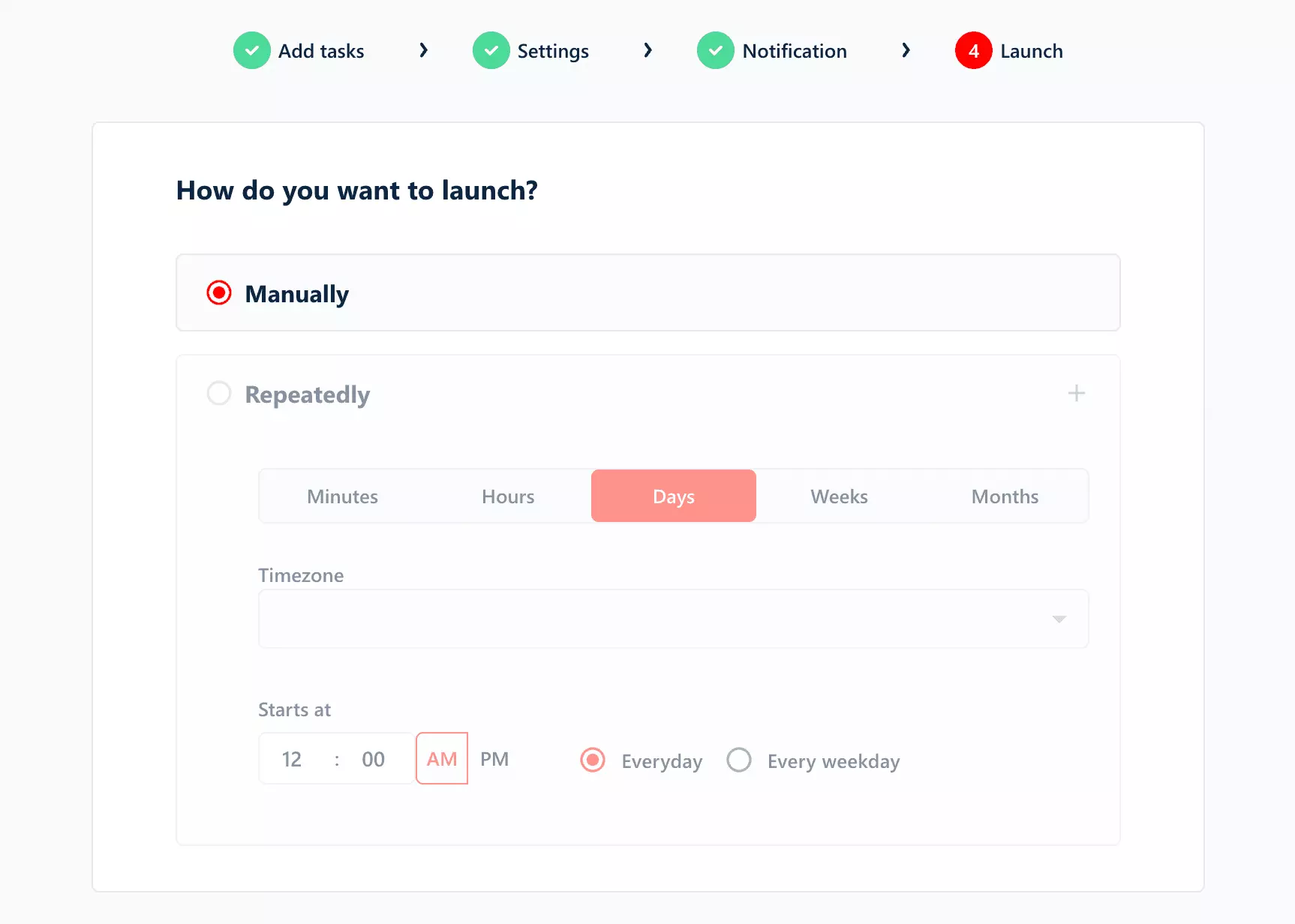
Getting the data out is straightforward.
Once a run finishes, you can export everything as a CSV.
If you want it to show up somewhere automatically, lobstr.io can push results to Google Sheets, Amazon S3, SFTP, or email.
And if this needs to plug into something bigger, the Make.com integration opens the door to 3,000+ other apps.
Speed
lobstr.io performed well in the speed test.
Without email collection, it returned 100 unique results in 5 minutes 06 seconds — roughly 51 minutes for 1,000 results.
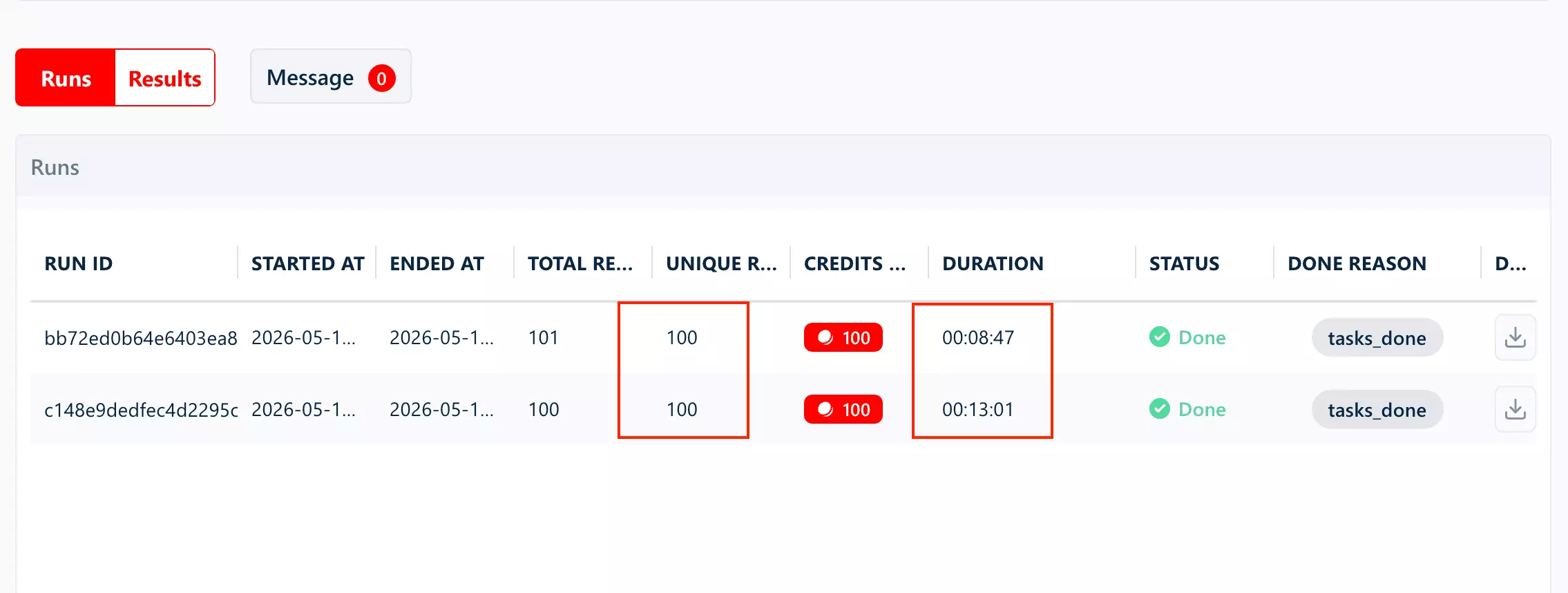
That makes sense. Email collection adds extra work because the scraper has to visit business websites and look for contact details.
The speed is also adjustable.
Customer support
lobstr.io offers customer support through a live chat pop-up directly on the website.
It's one of the few things users mention consistently—and for once, it's not vague praise.
The team is typically quick to respond, technically competent, and actually helpful.
Best for
Pick this when Yelp is part of a real workflow — lead gen, outreach, market mapping — not a one-off experiment.
It's built for runs you'll repeat, lists you'll grow, and data you'll actually use.
If contact details matter at all, there's no comparison.
It's the only tool that visits each business's website to pull an email — and that changes what you can do with the output.
Apify
Apify's marketplace is crowded, and quality varies a lot between actors.
For the comparison, I picked the Yelp actor with the most users. It's a quick sanity check that the actor is actively used.
| Pros | Cons |
|---|---|
| Free plan available | Runs zero results |
| Export to CSV, JSON, and Excel | Smallest data fields |
| Scheduling available | No deduplication |
| No CSV import | |
| Slowest | |
| No concurrency control |
Key features
- 9 data fields per listing
- Schedule recurring scrapes
- Export to CSV, JSON, and Excel
- Integrates with Make, Zapier, and n8n
- Cloud-based, no installation needed
Data
Apify returns 9 fields per listing — the fewest of the five tools.
Here are all 9 fields:
| 🖼️ primaryPhoto | 📄 name | 🏷️ type | 💰 priceRange |
| 🍽️ cuisine | ⭐ aggregatedRating | ⭐ reviewCount | 🔗 directUrl |
| 🔗 website |
Snapshot-level data — enough to identify a business and check its rating, not enough to contact it, map it, or qualify it further. There is no phone, no address, no coordinates, no hours, no claimed status, no amenities.
That said, the bigger problem isn't what's missing—it's reliability.
In my test, a search URL returned zero results, while switching to keyword search returned three. I assumed I'd misconfigured something.
I hadn't. That was the output.
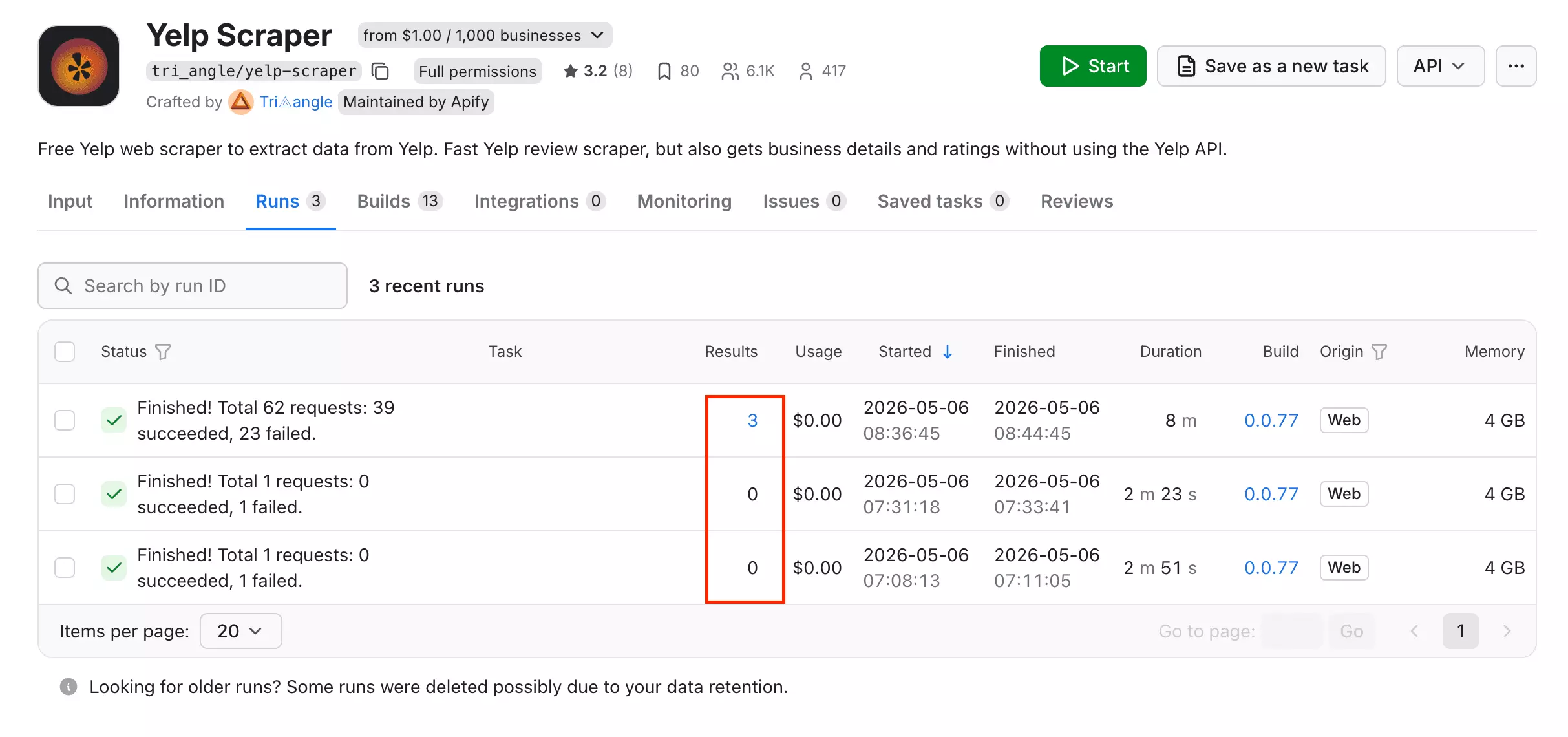
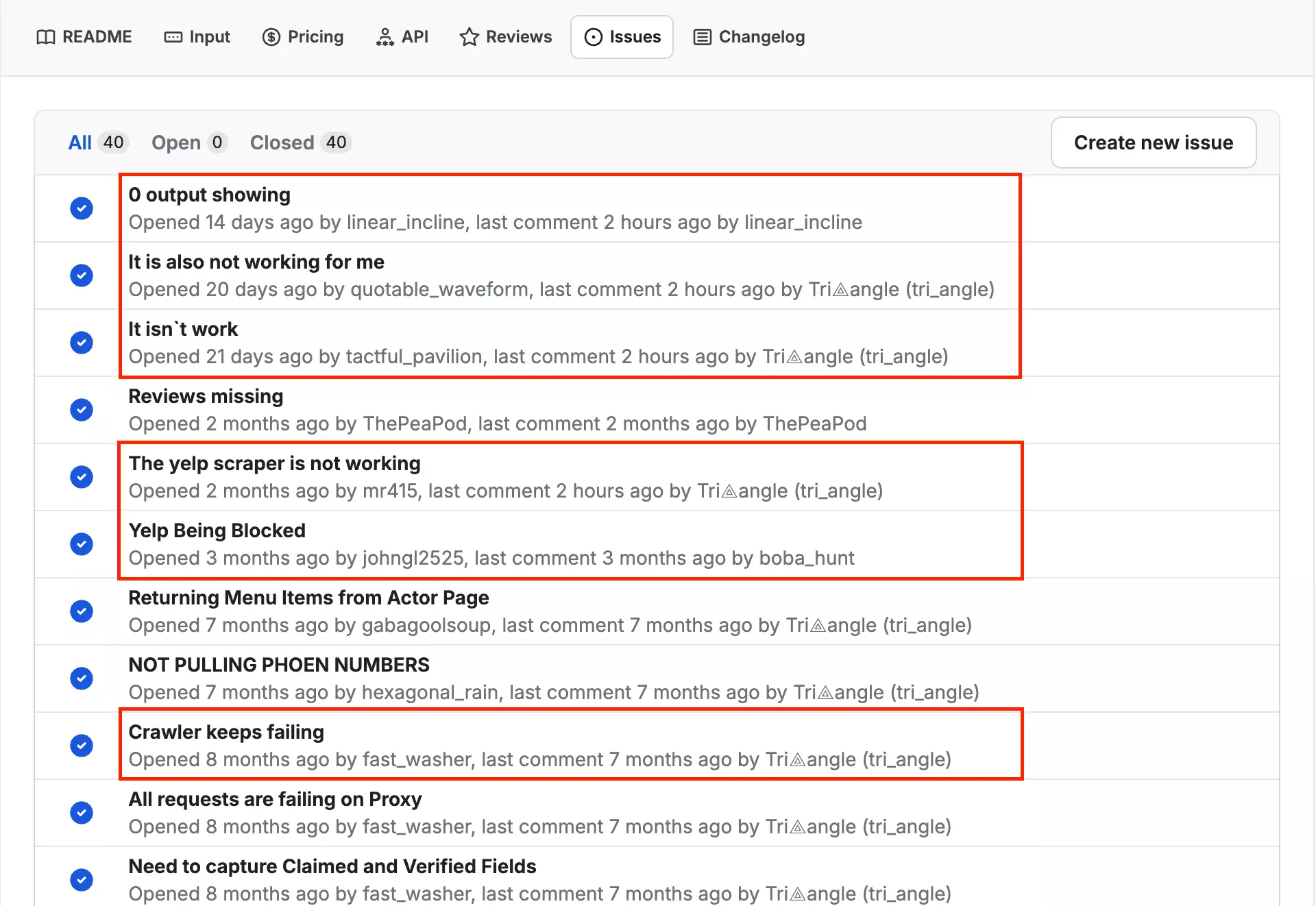
Other users report the same pattern—zero output, missing reviews, phone numbers not pulling.
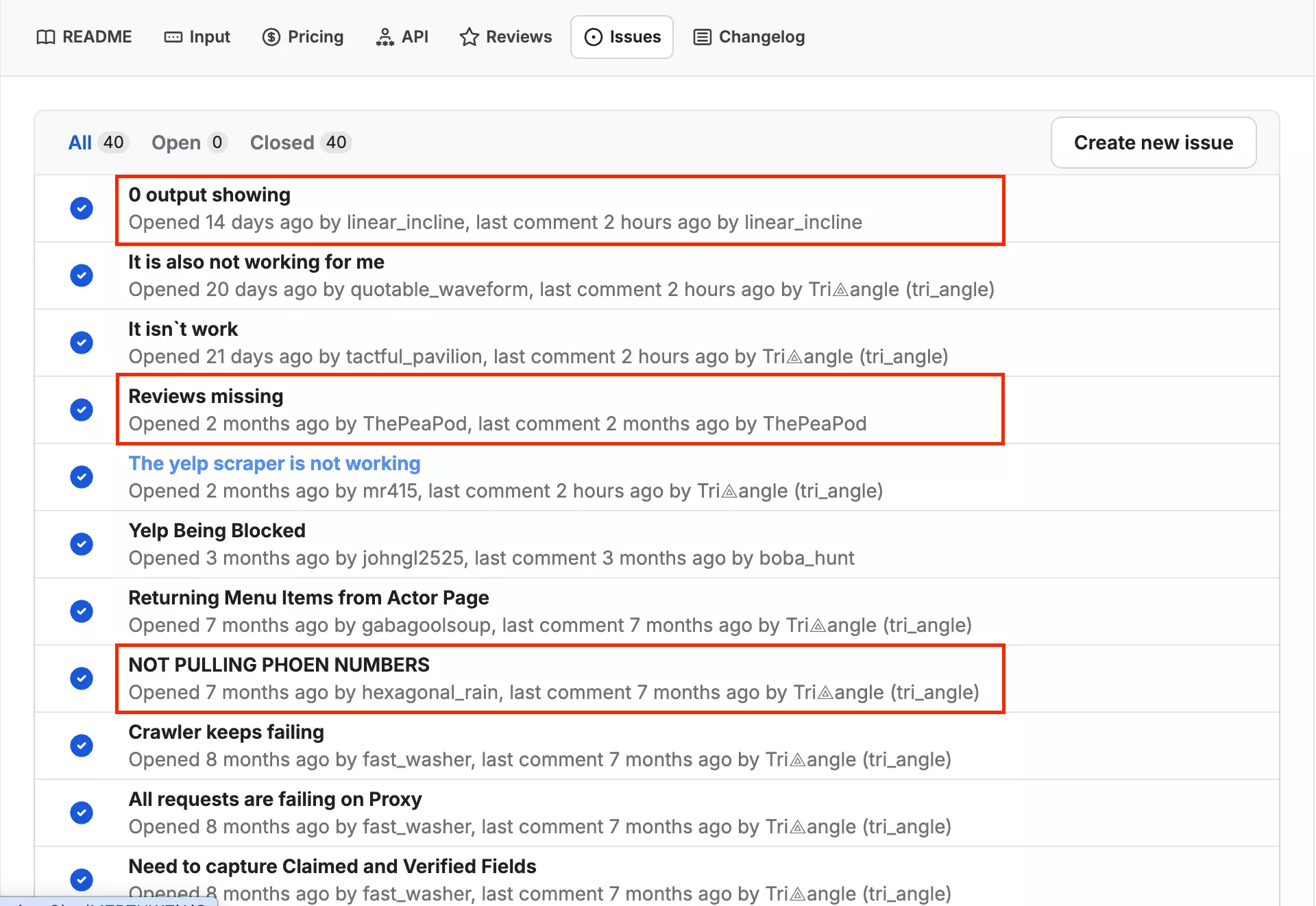
That's not a missing feature. That's a failure mode.
Affordability
Apify uses a pay-per-result model.
The pricing is flat — $1.00 per 1,000 businesses, across all plans.
- All plans: $1.00 per 1,000 results
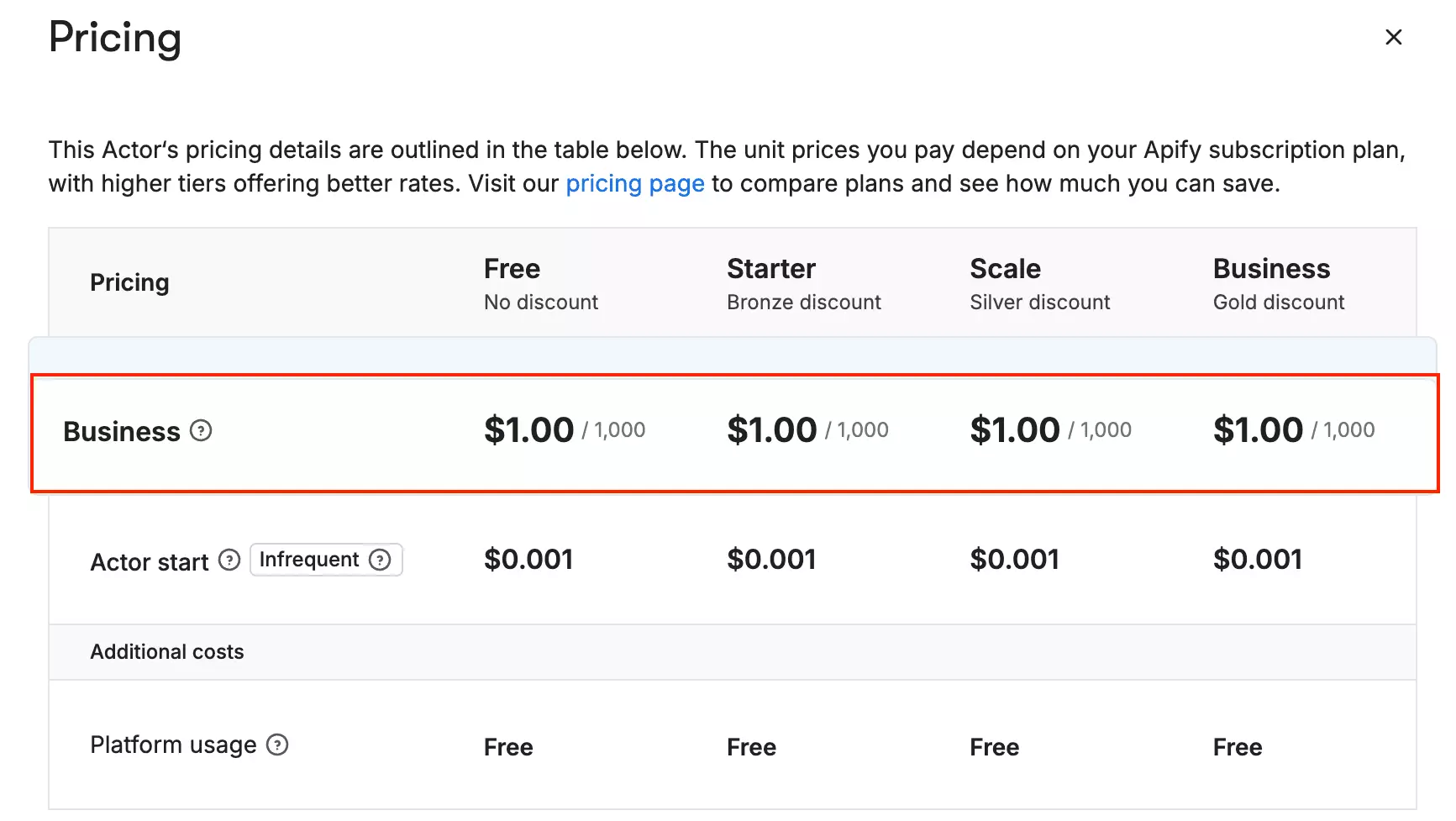
There is a free plan that comes with $5/month in platform credits.
One thing worth noting: the cost doesn't drop as you scale.
Whether you scrape 1,000 results or 100,000 results, the per-result rate stays the same.
So Apify rewards no one for volume.
Scalability
Apify can handle large inputs — but scaling runs into two walls fast.
On the input side, there's no CSV upload.
Fine for small batches, not for repeatable large-volume work.
On the output side, there's no concurrency dial.
You can queue more URLs, but you can't control how aggressively the scraper processes them.
Scaling is linear — a bigger job just means a longer wait, with no lever to compress it.
Then there's the reliability problem.
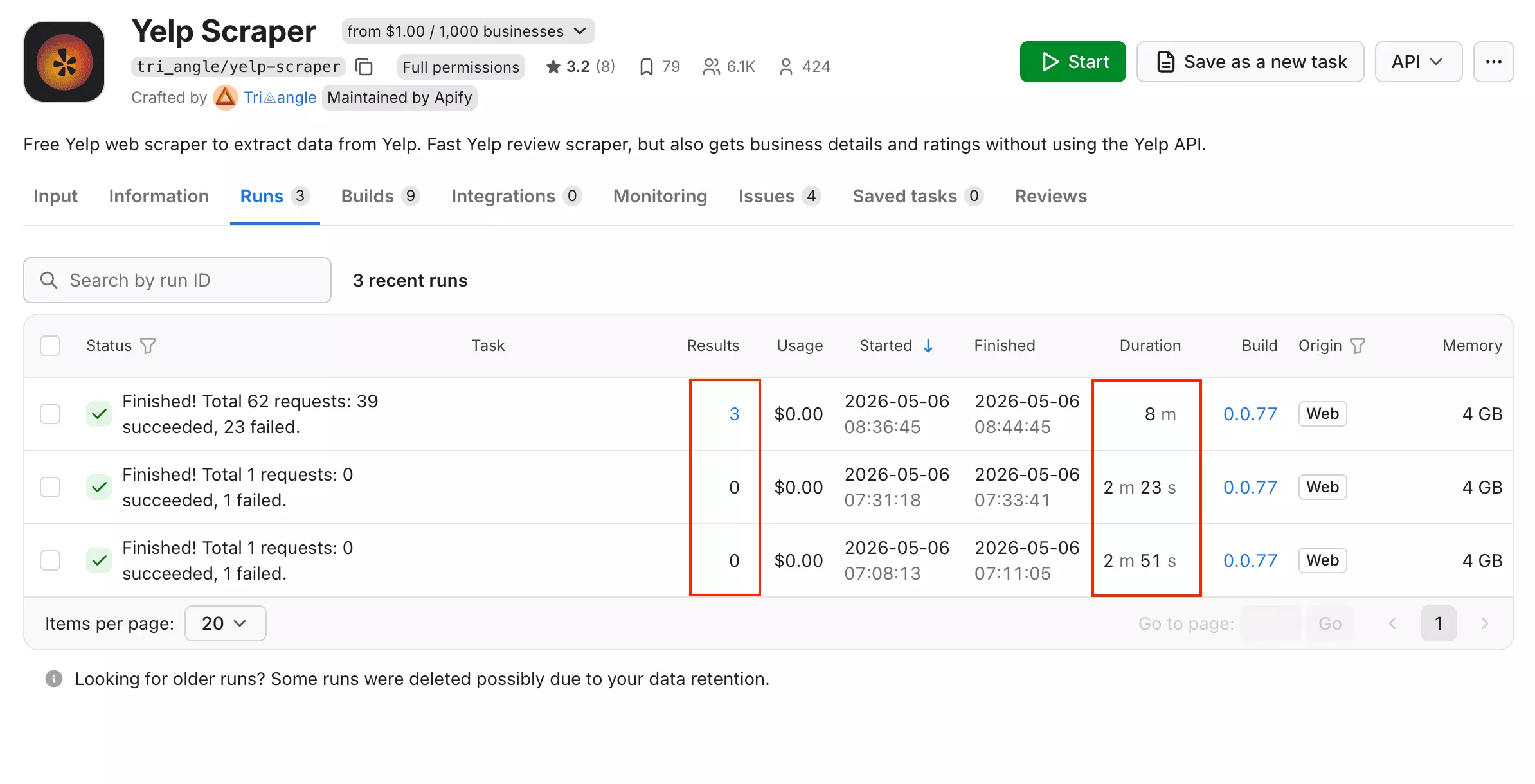
In my test, 23 out of 62 requests failed — a 37% failure rate on a small run. At scale, that compounds fast.
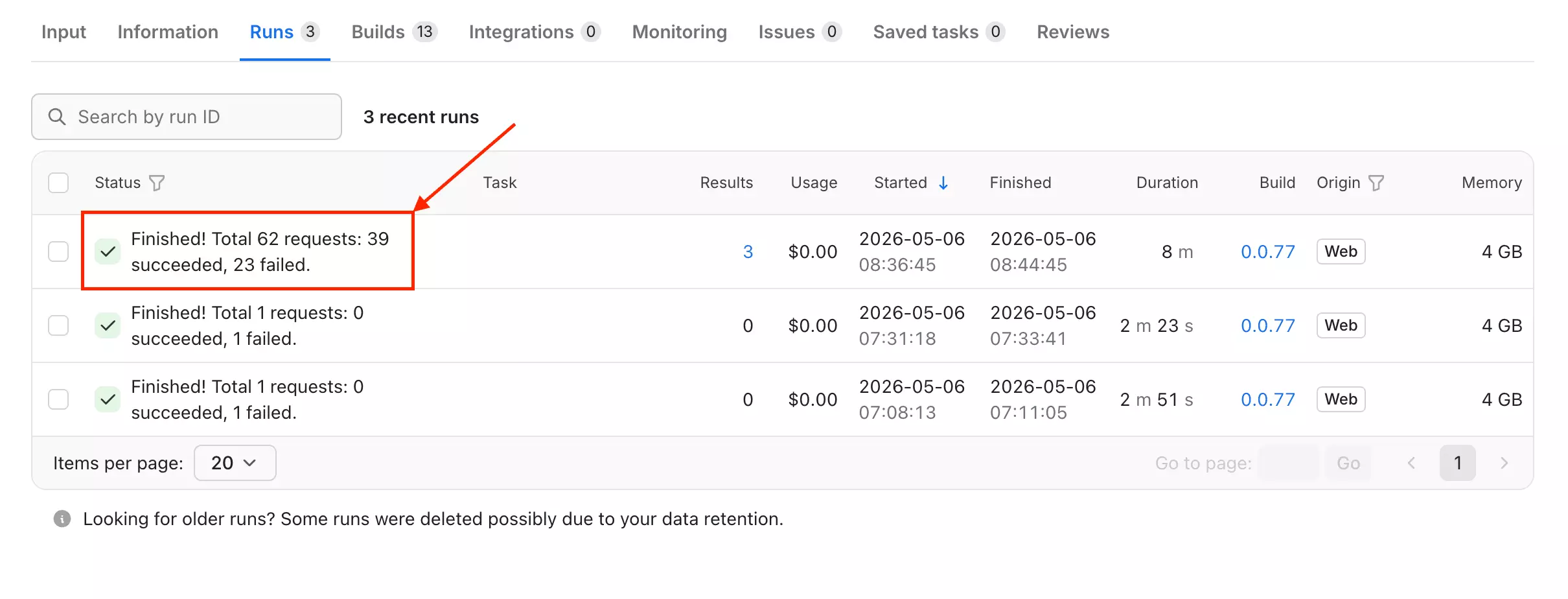
The Issues tab tells the same story: users report zero output, proxy failures, the scraper not returning anything at all.
These aren't edge cases — they follow a consistent pattern of Yelp blocking the actor with no clear feedback to the user.
At 2,667 minutes per 1,000 results, the monthly ceiling is roughly 5,400 results/month — and that assumes every request succeeds.
Apify is unstable at scale.
No throughput control and a 37% request failure rate mean you cannot count on consistent results.
A larger job just compounds the data loss with no lever to fix either problem.
Ease of use
Getting started looks straightforward. You enter a search term, set a location, and hit run.
The interface accepts either search terms or direct Yelp URLs from the same screen.
Result limiting is available so you can cap results before running.
There's no deduplication or "unique results" control. If your inputs overlap, you'll be cleaning duplicates after export.
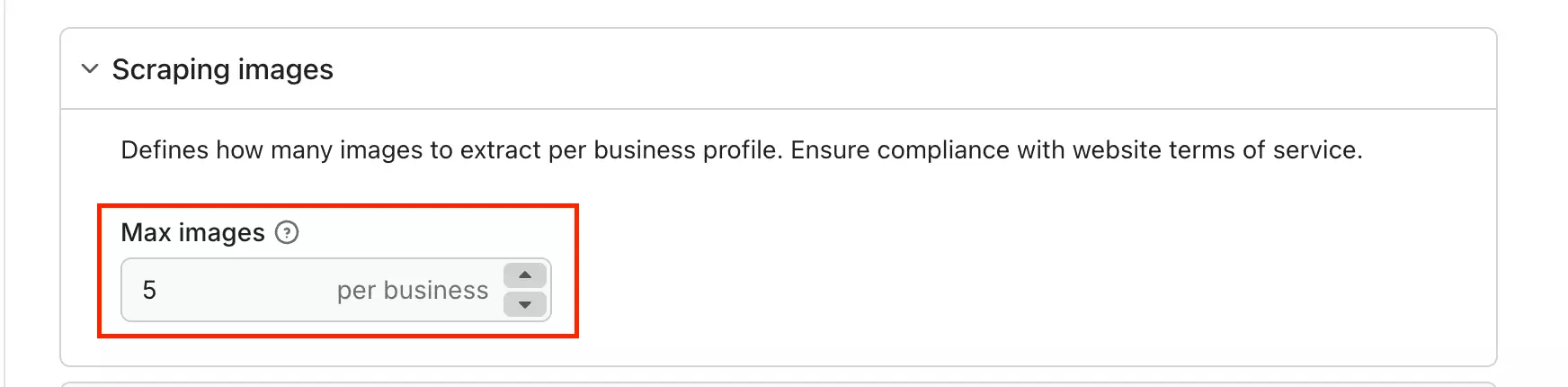
There's also an image scraping tab — you set how many images to pull per business profile.
Practical if you need visual data, unnecessary overhead if you don't.
Scheduling is available. Recurring scrapes can be set up without extra tools.
Export options are strong: CSV, JSON, Excel, and direct integrations with Make, Zapier, and n8n.
Speed
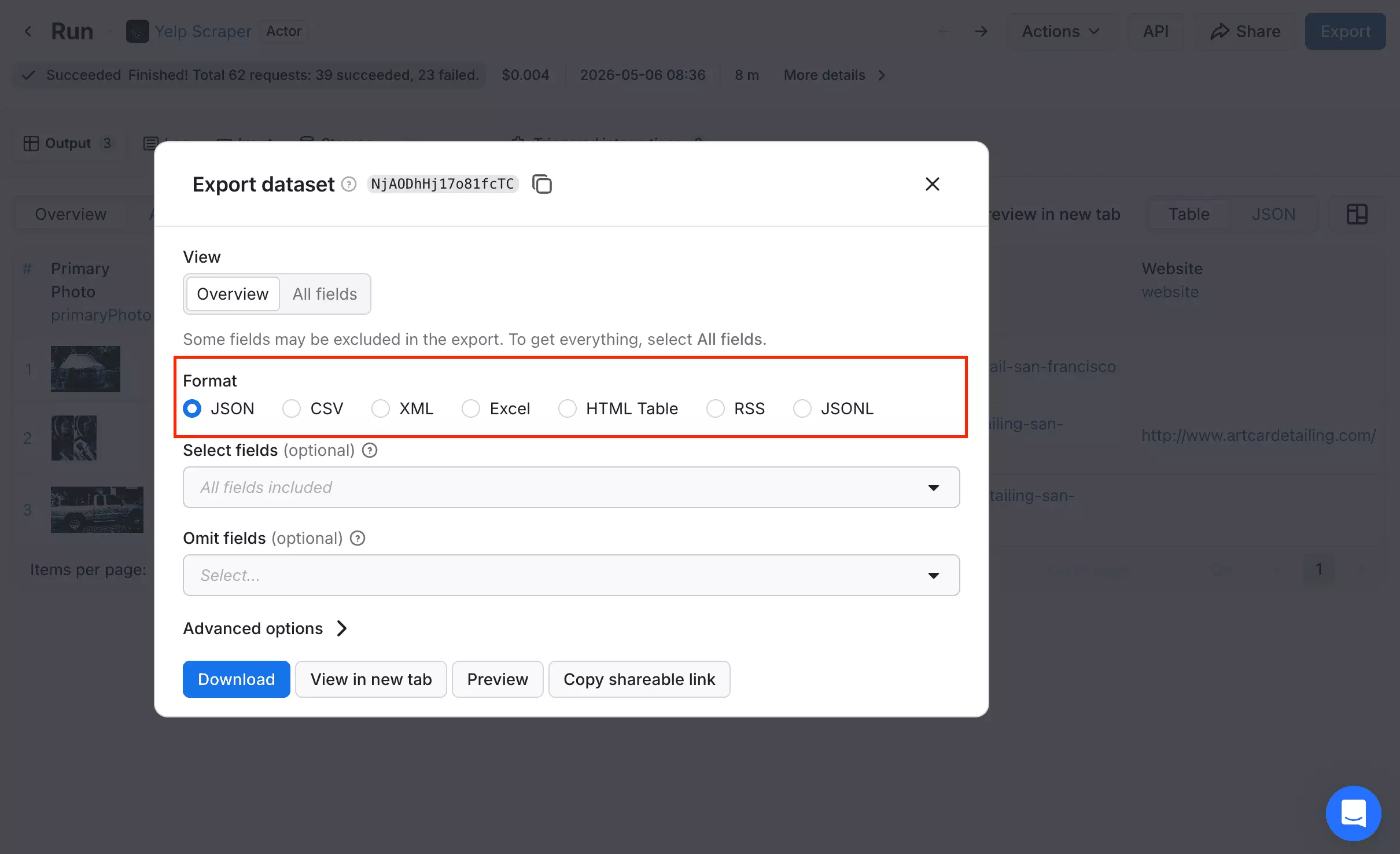
Apify was inconsistent. Two runs returned zero results. The third returned 3 results in 8 minutes.
With a 37% request failure rate and 2,667 minutes for 1,000 results, this is just not usable.
Customer support
Apify provides support through live chat, a ticketing system, and a Discord community.
Live chat is solid for general questions. For technical troubleshooting, the issue system is the better route.
That said, response time for this actor was extremely slow—15 days. That's not a backlog; that's a different calendar.
For a tool with documented zero-result failures, a 15-day support window means you're on your own when a run breaks.
Best for
Pick this when you want to see what Yelp data looks like before spending anything.
The $5 free credit is real, and for a quick sample to check if the field coverage fits your use case, it's enough.
Don't treat it as a production tool. The reliability record is too inconsistent for anything you need to count on.
Bright Data
| Pros | Cons |
|---|---|
| Rich business data coverage | No scheduling |
| Only tool that returns video URLs | 1 in 3 records missing |
| Multiple export and delivery options | No deduplication |
| Pay-as-you-go option available | No concurrency control |
| CSV import |
Key features
- 29 data fields per listing
- images_videos_urls — captures photos and video links in a single field
- Bulk URL upload via CSV
- Export to CSV, JSON, NDJSON, or Parquet
- Cloud delivery to Amazon S3, Google Cloud, Azure, Snowflake, or SFTP
- Cloud-based, no installation needed
Data
Bright Data returns 29 fields per listing.
Here are all 29 fields:
| 🆔 business_id | 🆔 yelpbizid | 📄 name | 📝 updatesfrombusiness |
| ⭐ overall_rating | ⭐ reviews_count | 📊 is_claimed | 🏷️ categories |
| 🔗 website | 📞 phone_number | 📅 opening_hours | 📍 address |
| 📍 address:zip_code | 📍 full_address | 🏷️ amenities | 📝 aboutthebusiness |
| 🏷️ highlights | 📋 services_offered | 🔗 url | 💰 price_range |
| 📌 latitude | 📌 longitude | 🌐 service_area | 🏙️ city |
| 🌐 state | 🌐 country | 📍 zip_code | 🖼️ imagesvideosurls |
| 📊 is_closed |
The address coverage is the most granular of any tool. Bright Data splits location into address, fulladdress, address:zipcode, city, state, country, and zip_code — seven separate location fields.
Bright Data has four fields no other tool returns:
| 📝 updatesfrombusiness | 🏷️ highlights | 📋 services_offered | 🌐 service_area |
service_area returns the geographic area the business covers, not just where it's located. Relevant for mobile or delivery-based businesses.
Affordability
Bright Data gives you two ways to pay.
No monthly commitment, or a subscription that gets cheaper as you scale.
Pay as you go:
- $1.50 per 1,000 results
Monthly subscription:
- 380K plan: $1.30 per 1,000 results
- 900K plan: $1.10 per 1,000 results
- 2M plan: $1.00 per 1,000 results
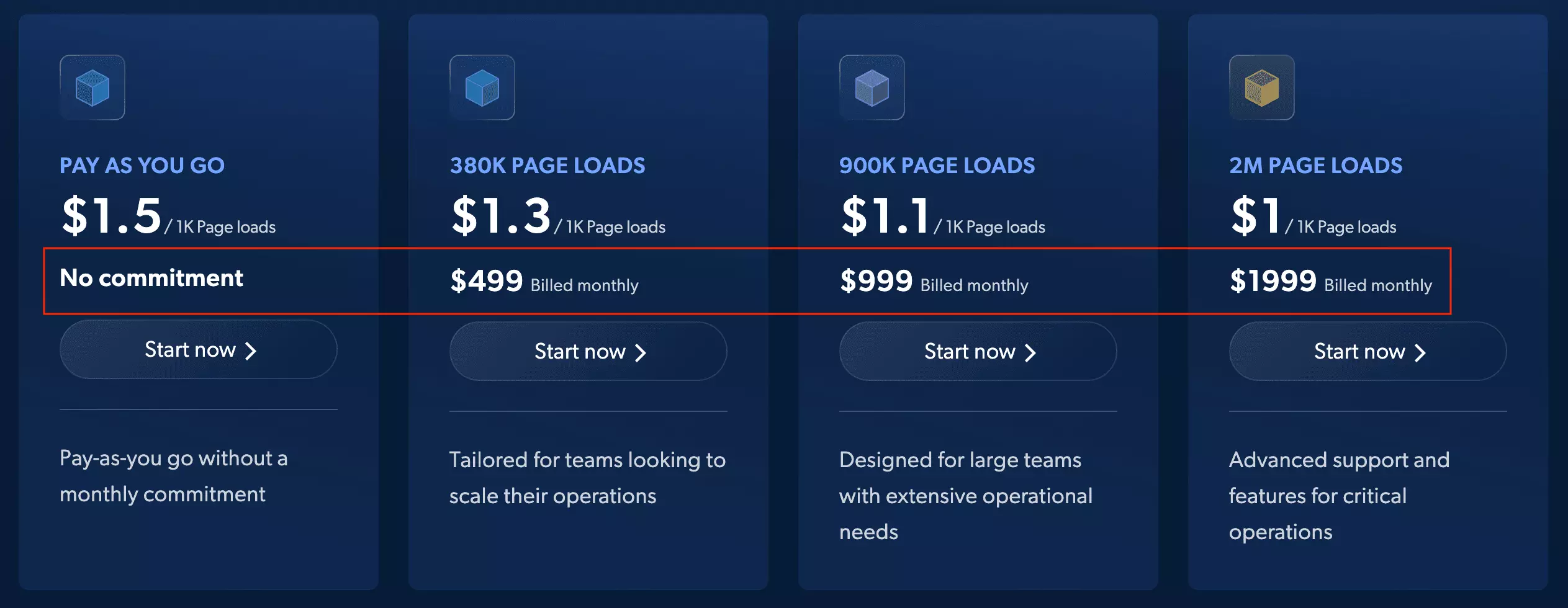
The pay-as-you-go option is the most flexible. No commitment, no monthly fee — you only pay for what you use.
There is no free tier. But a 7-day trial is available to test before committing.
Scalability
Bright Data supports CSV upload for bulk inputs, so large input lists are easy to load.
On the output side, there's no concurrency control inside the scraper setup.
Scaling depends on the platform's execution layer rather than a setting you can tune yourself.
More inputs means a longer wait, with no lever to push throughput.
Then there's the reliability problem.
That's a 66.67% success rate — roughly 1 in 3 records simply doesn't come back.
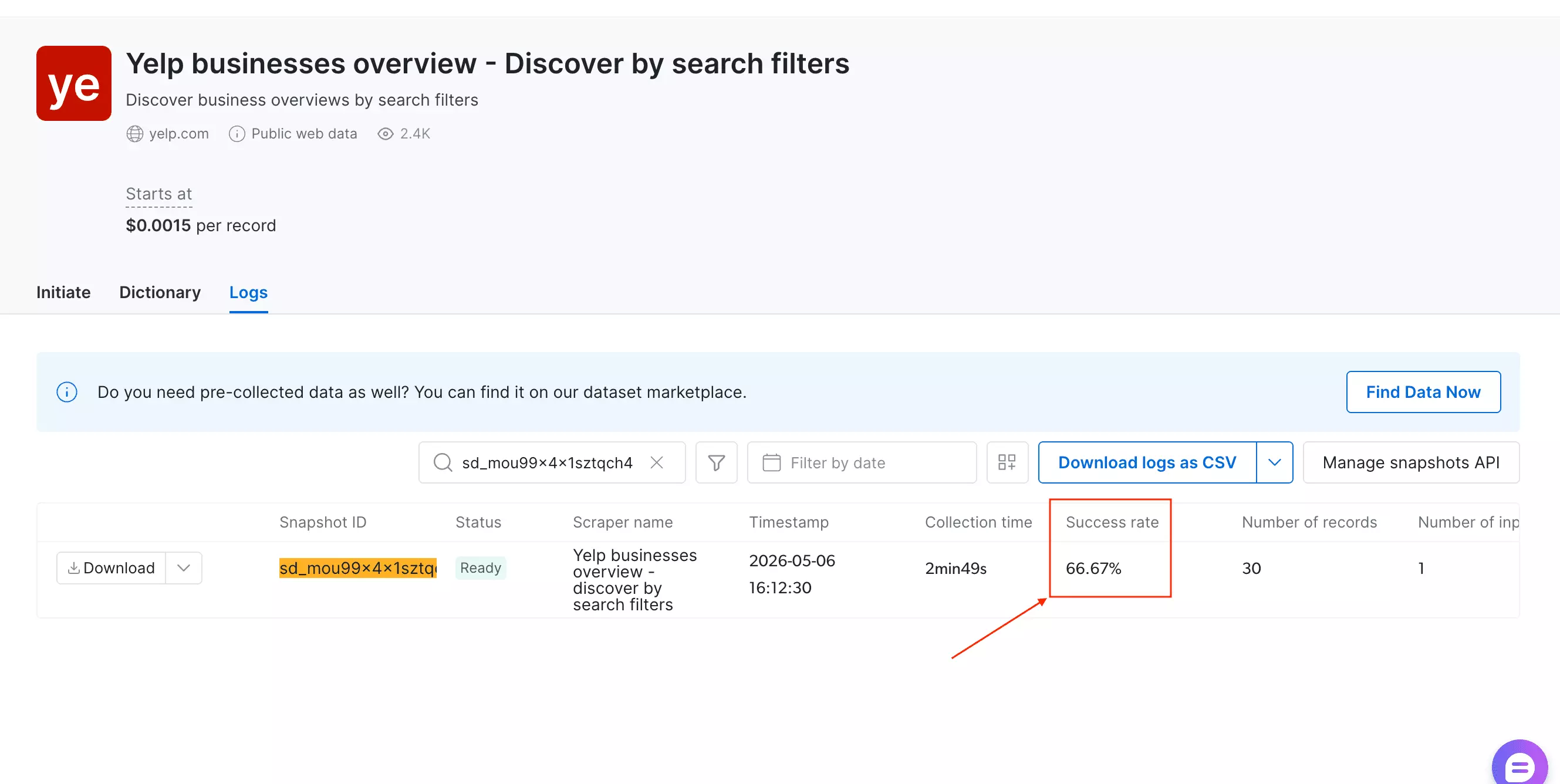
At scale, that's not a rounding error. That's missing data.
At 94 minutes per 1,000 results, the theoretical monthly ceiling is 153K results/month.
At a 66.7% success rate, the usable ceiling is closer to 102K results/month.
Bright Data is unstable at scale.
No concurrency control and a 33% record failure rate mean output volume and completeness are both unpredictable.
You have no control over either.
Ease of use
Bright Data offers five different Yelp scrapers. Two are for reviews (so let's ignore them).
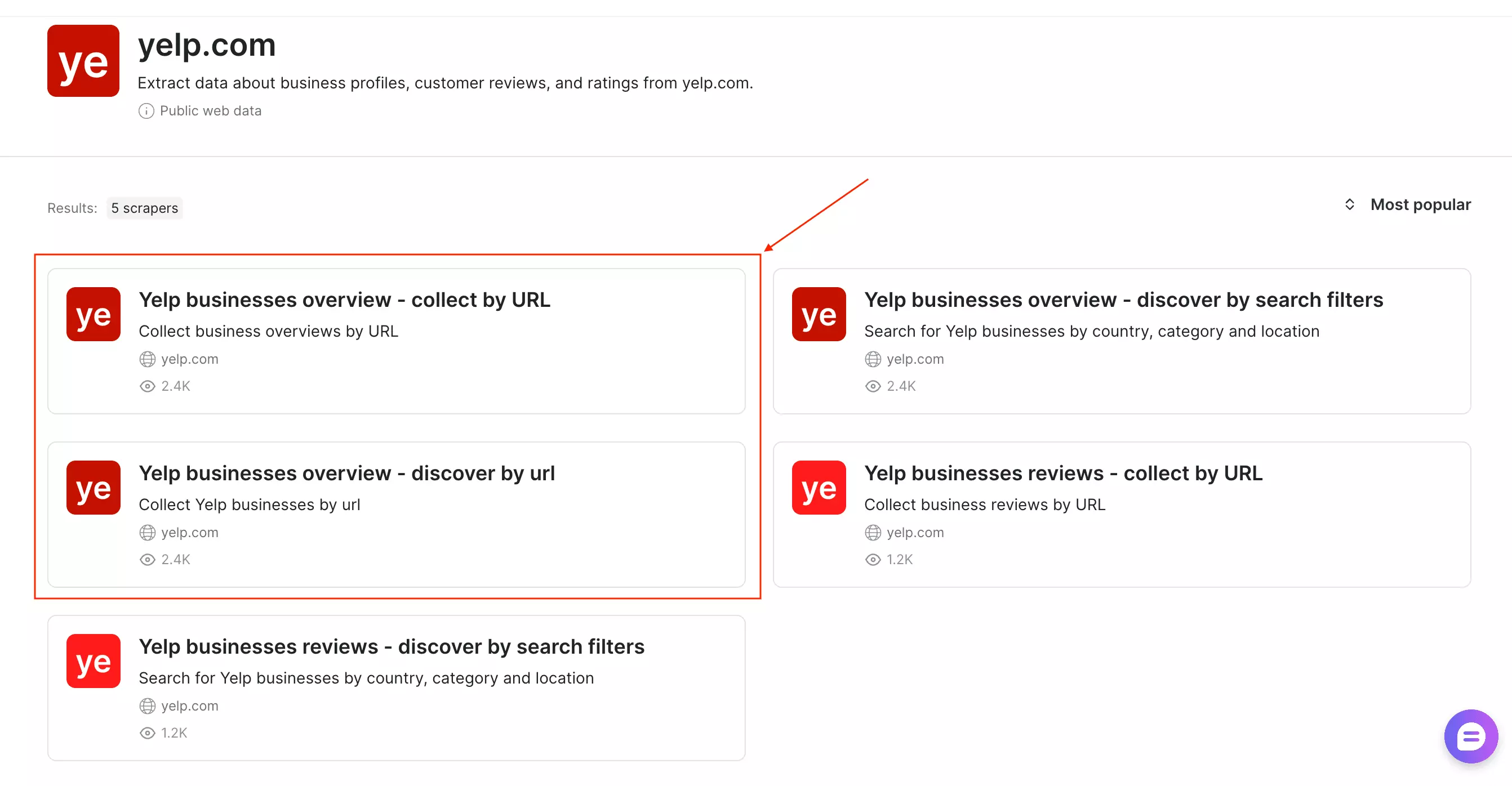
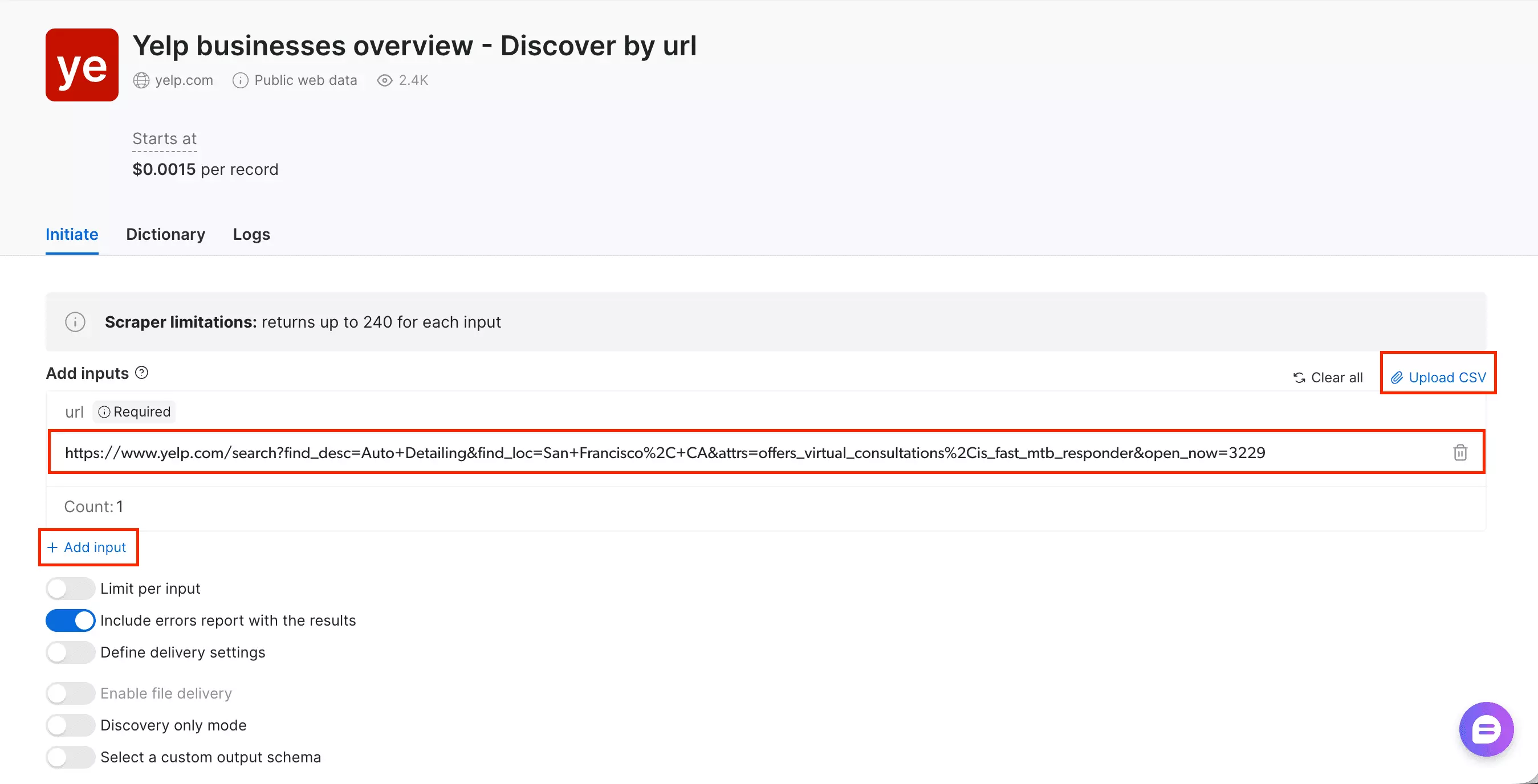
Result limiting is available so you can cap results before running, but there's no deduplication control, so overlapping inputs can produce repeats.
The bigger issue wasn't duplicates though. It returned zero results. Repeated runs, same outcome.
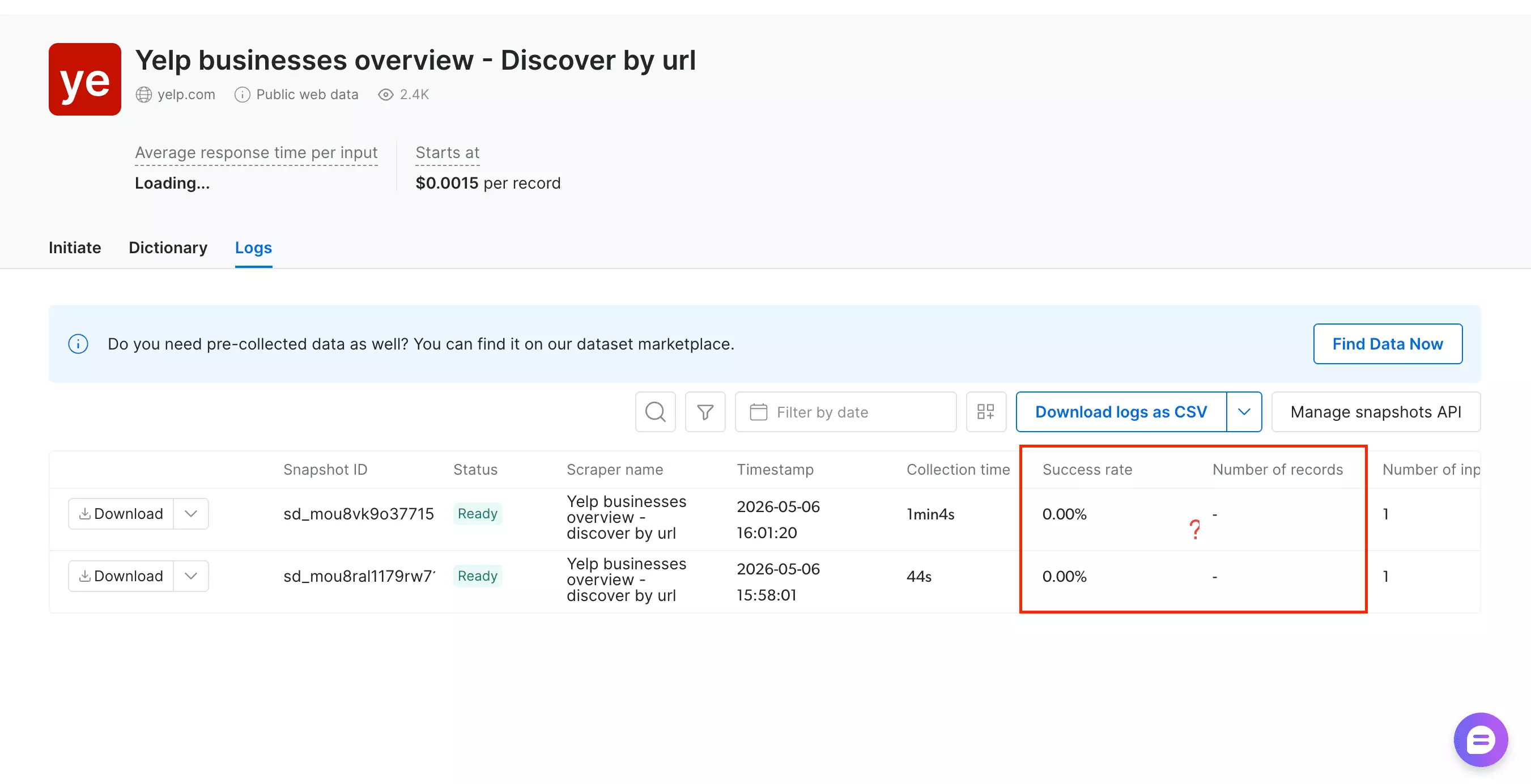
Discover by search filters is the one that actually works.
Three fields — country, category, and location — one row, done.
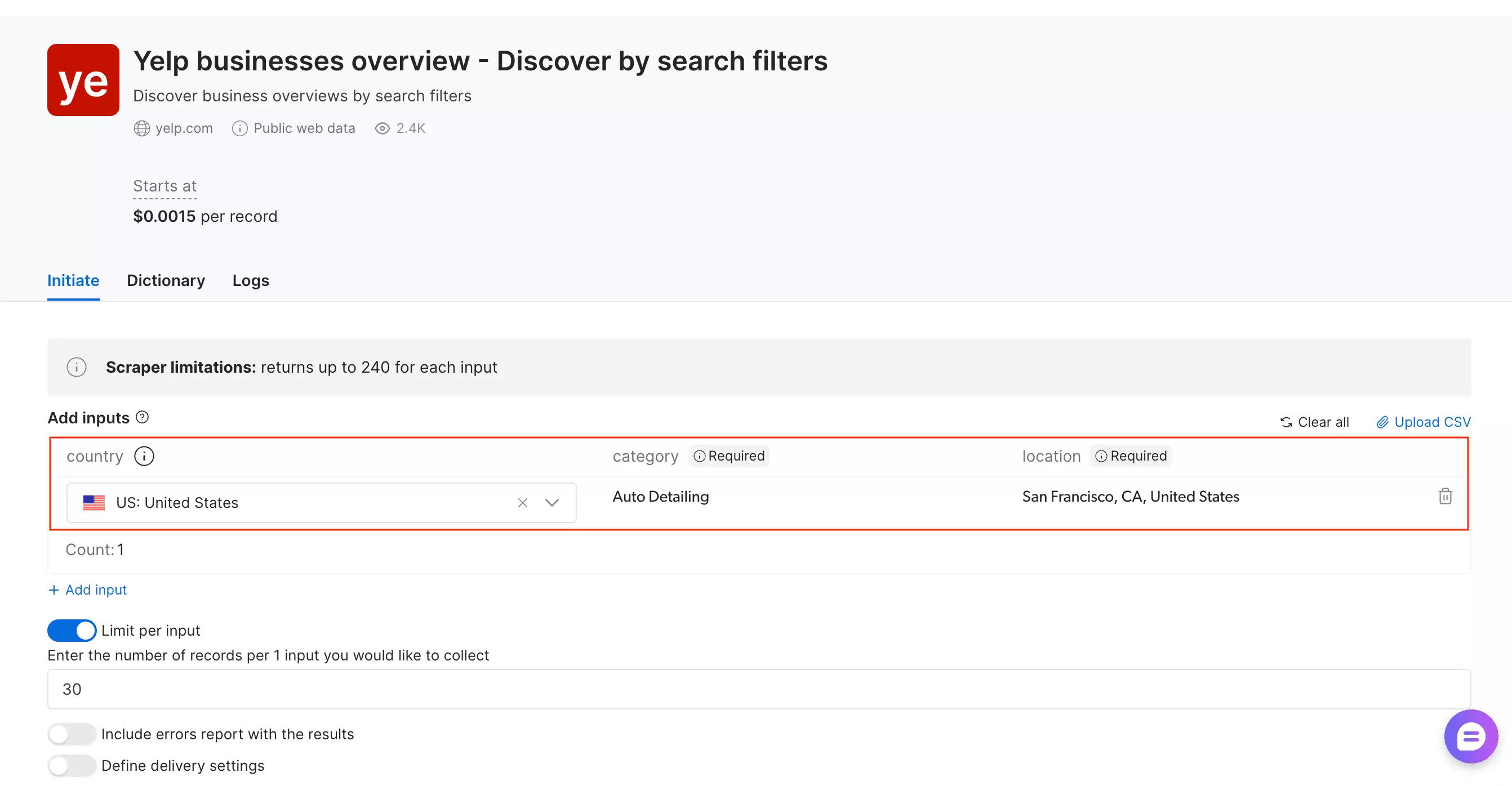
Simple enough, but if your workflow is URL-first, it's not a natural fit.
You're forced into their filters instead of feeding it the exact pages you already know you want.
Scheduling isn't available on the no-code platform either. If you need recurring scrapes, you'll be re-triggering runs manually every time.
Exports and integrations are the bright spot. JSON, NDJSON, CSV, or Parquet — delivered straight to Amazon S3, Snowflake, Google Cloud, Azure, or SFTP.
Speed
The numbers here depend on which scraper you're using — and that matters.
So let's drop that for now.
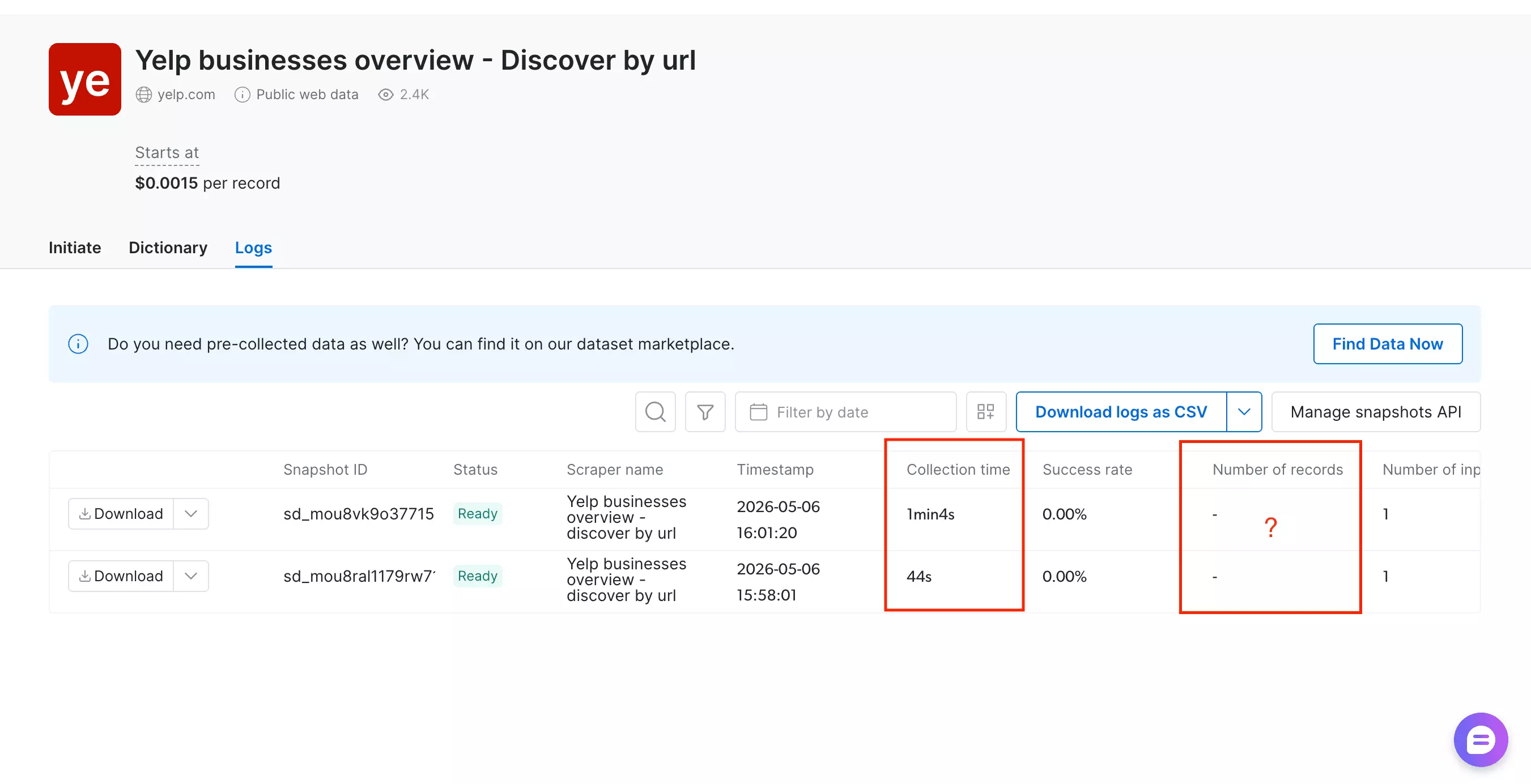
But the success rate was 66.67%. That means 1 in 3 requested records didn't come back.
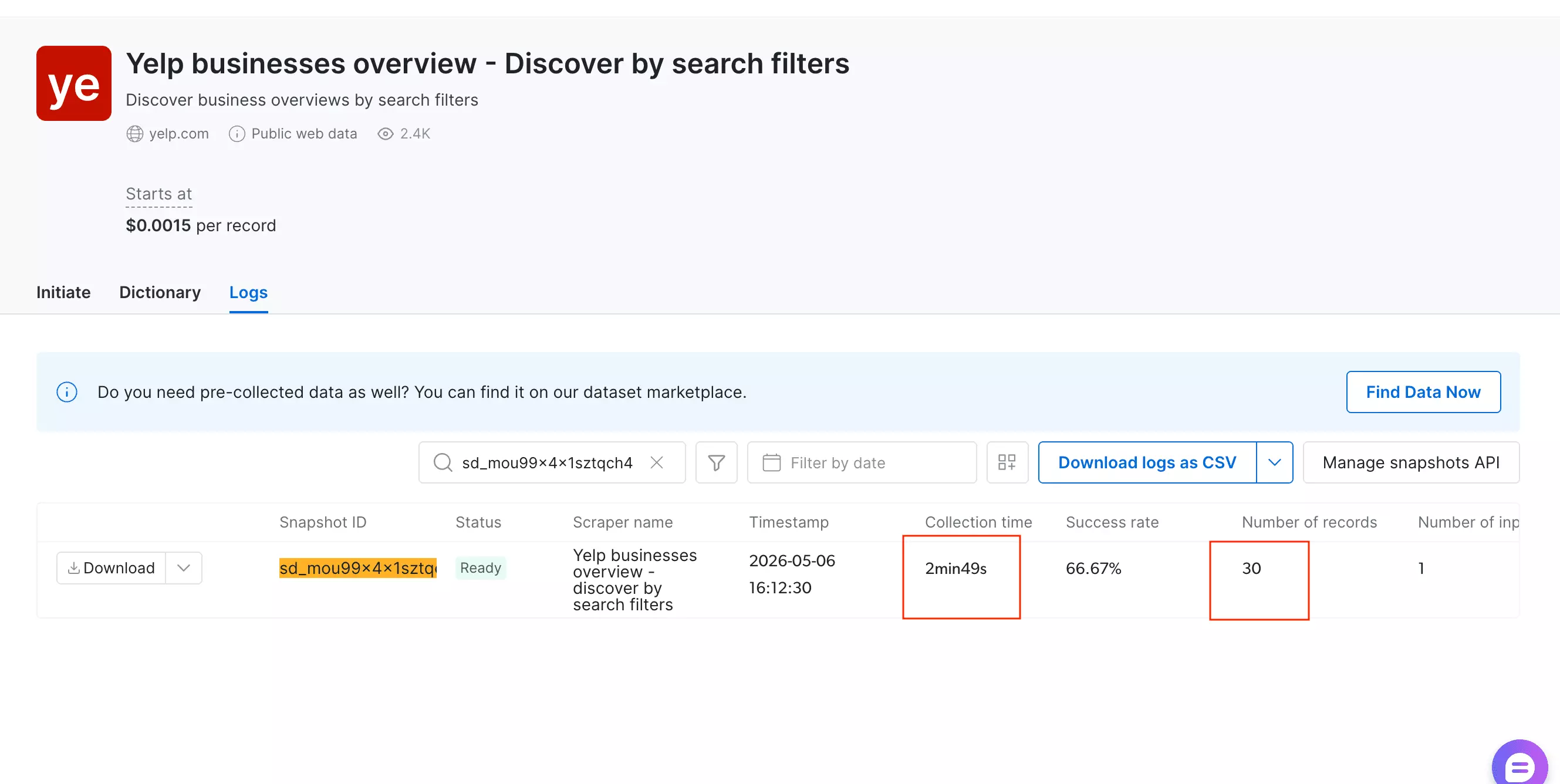
Fast on paper. Less so when you factor in the missing data.
Customer support
Customer support is available through a live chat widget on the platform.
If you notice missing data, there's also a Request missing data option.
It works, but the process is slow — you fill out a form, then wait for a follow-up over email.
Best for
Pick this when Yelp is one of several sources feeding into a larger system — and the destination matters more than the scraper.
S3, Snowflake, Google Cloud, Azure: if your pipeline already lives there, Bright Data fits in without friction.
If Yelp is your only source, or you're working URL-first, the setup overhead and incomplete output make it hard to justify.
ScrapeHero Cloud
| Pros | Cons |
|---|---|
| Unique rating_histogram | Expensive at scale |
| Data Credit Calculator before each run | No live chat |
| No deduplication | |
| No CSV import | |
| No concurrency control |
Key features
- 23 data fields per listing
- rating_histogram — full 1-through-5-star review breakdown per business
- Data Credit Calculator shows exact cost before each run
- Schedule recurring scrapes
- Export to CSV, JSON, and Excel
- Cloud delivery to Google Drive, Dropbox, and Amazon S3 — REST API also available
- Cloud-based, no installation needed
Data
ScrapeHero Cloud returns 23 fields per listing.
Here are all 23 fields:
| 📄 business_name | 📍 address | 📞 phone | ⭐ average_rating |
| ⭐ total_reviews | 🔗 url | 🔗 website | 📌 geo_coordinates |
| 📍 street | 🏙️ locality | 🌐 country | 🌐 state |
| 📍 zipcode | 📊 rating_histogram | 📝 fromthebusiness | 👤 owner |
| 🖼️ owner_photo | 📅 year_joined | 📊 claimed | 🏷️ amenities |
| 📅 workhours | 💰 price_range | 🏷️ category |
ScrapeHero Cloud has a few exclusive fields. Here are those fields:
| 📊 rating_histogram | 👤 owner | 🖼️ owner_photo | 📅 year_joined |
year_joined tells you how long the business has been on Yelp.
Affordability
ScrapeHero Cloud runs on a credit-based subscription model. Every 10 credits = 1 record.
- Free plan: 40 records
- Lite plan: $8.33 per 1,000 results
- Ultra plan: $2.50 per 1,000 results
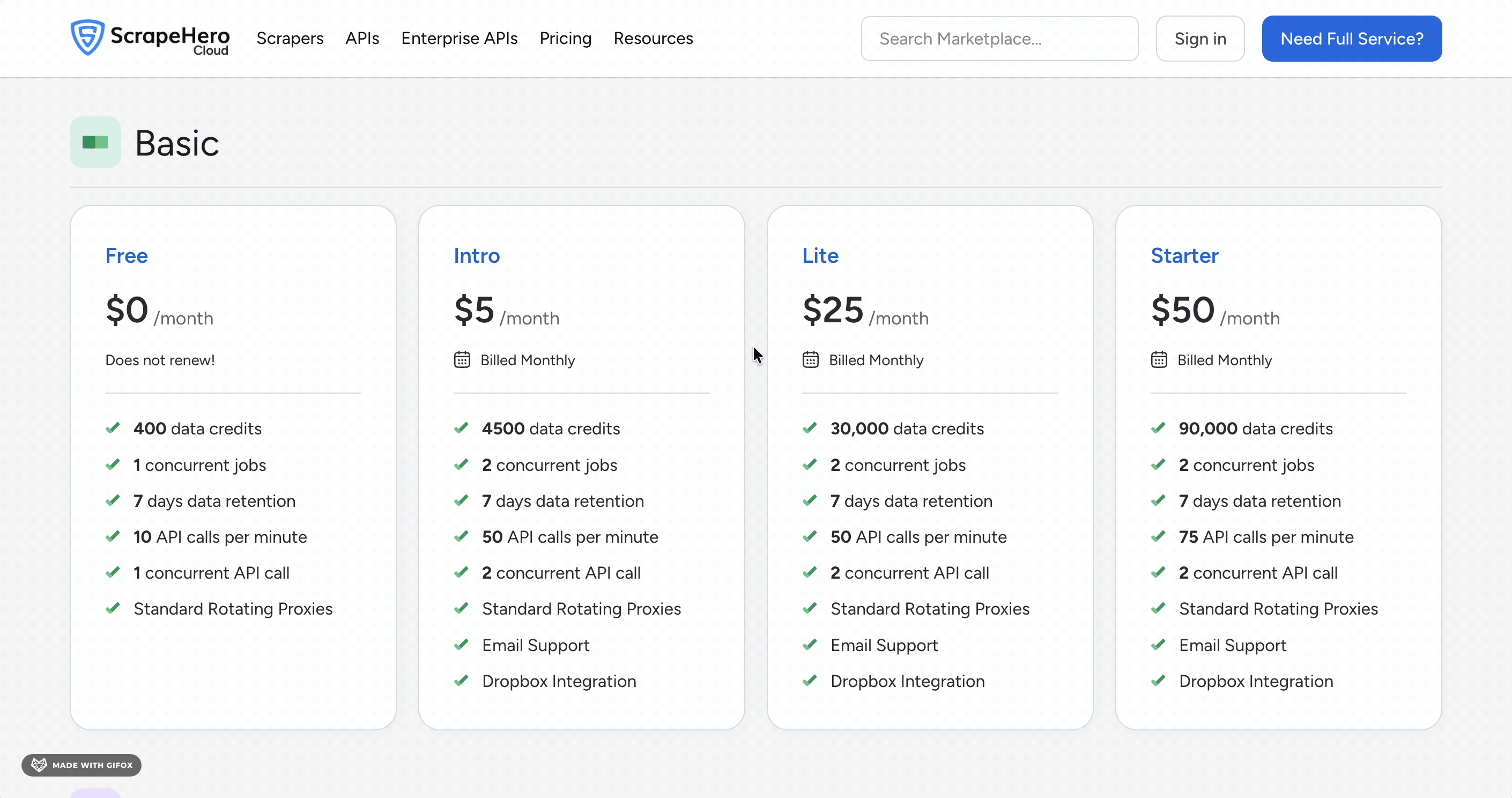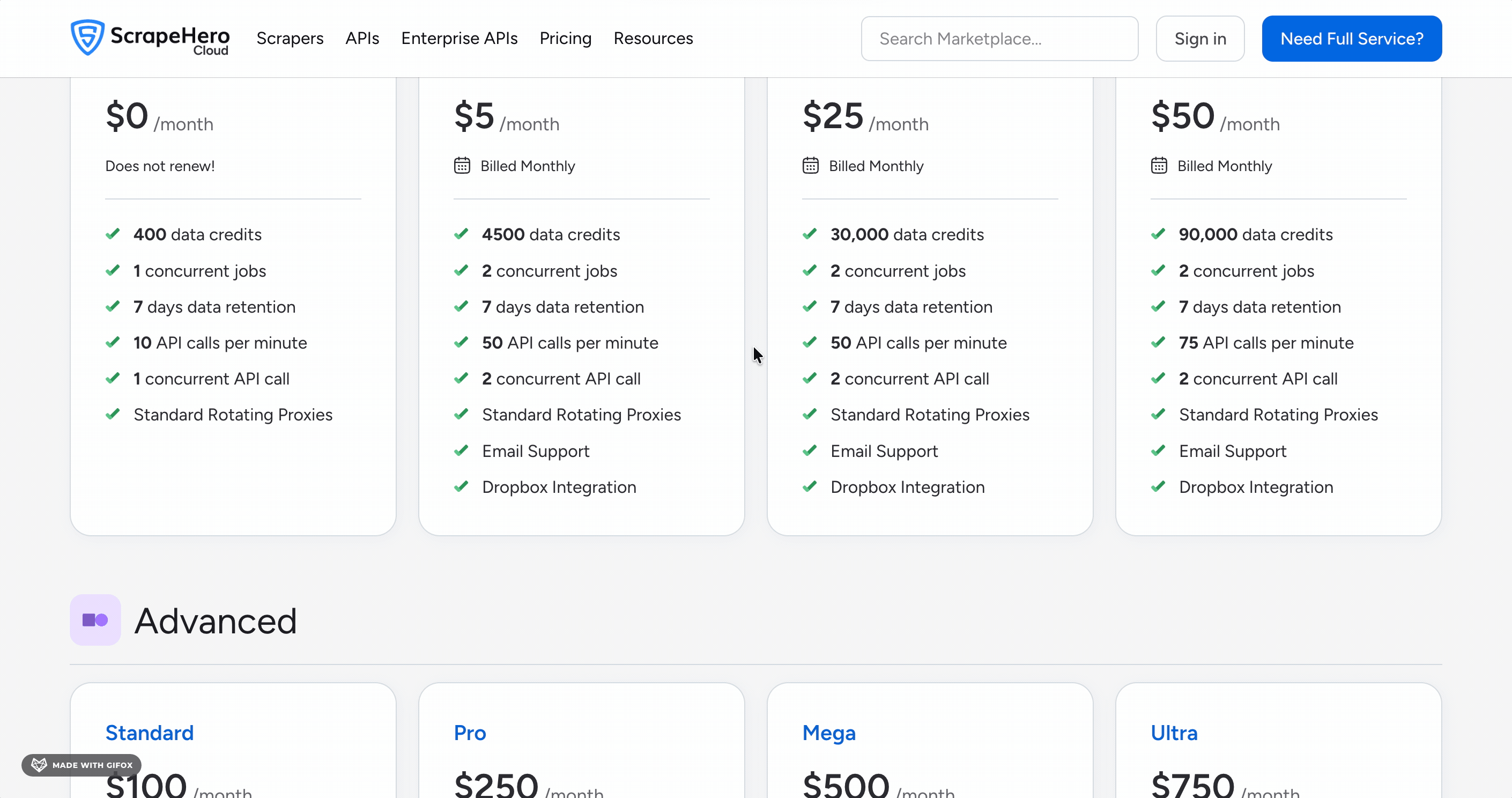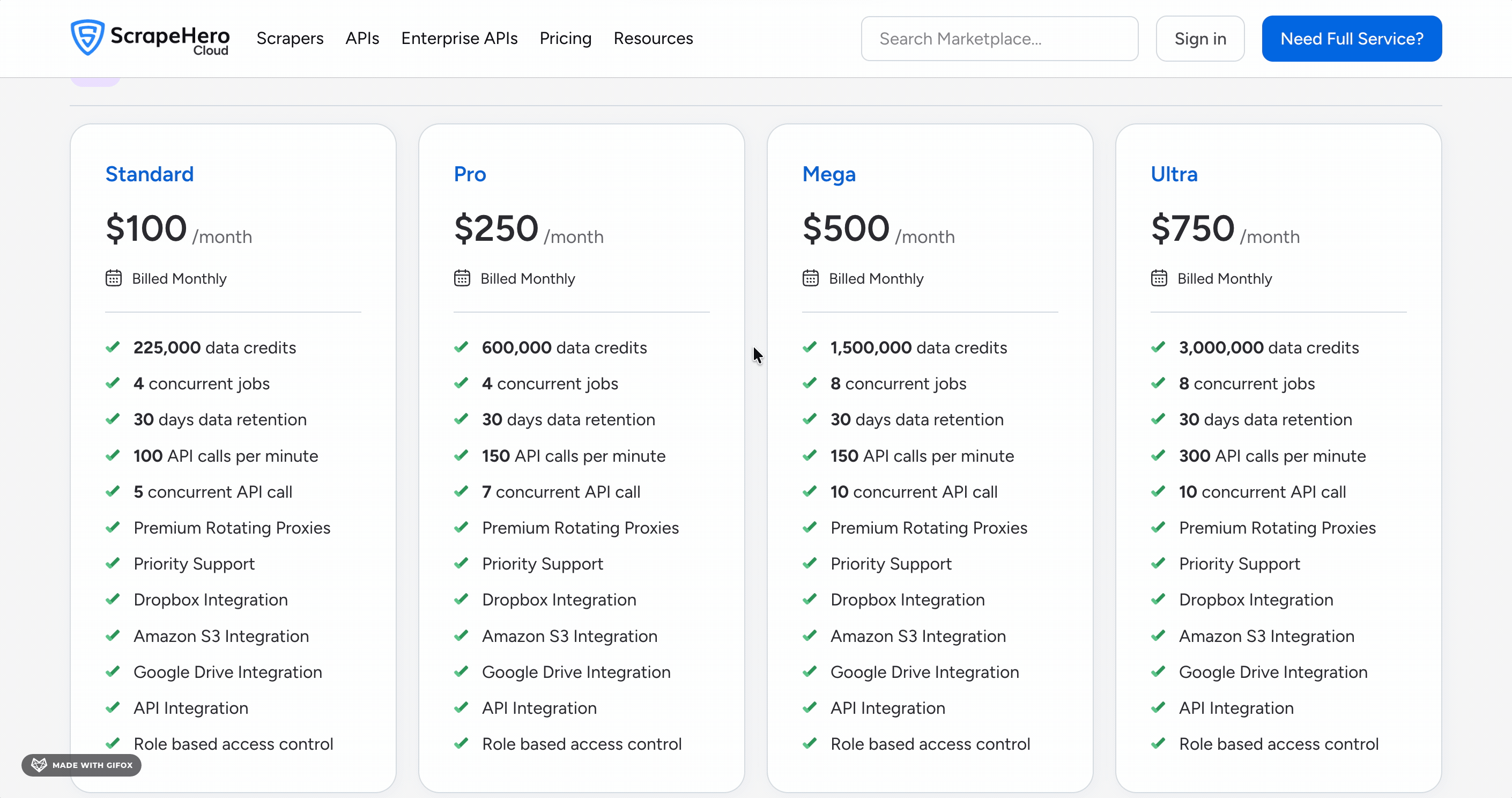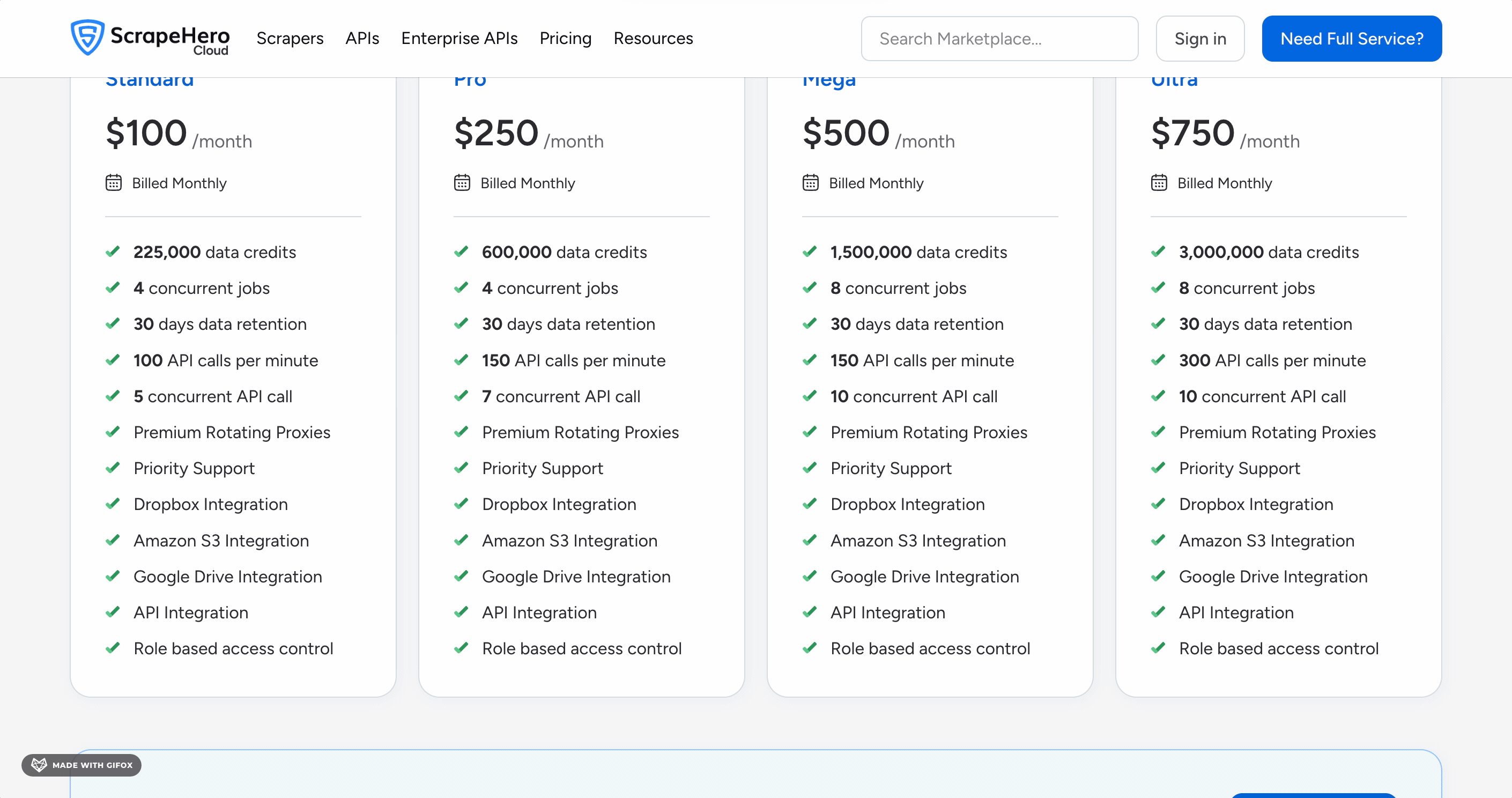
The free plan is genuinely limited — 40 records is barely enough to test the tool.
The cost drops as you scale, but even at Ultra it's more expensive than Apify's flat $1.00 per 1,000 results.
Scalability
ScrapeHero can take a large input without flinching.
There's no CSV import, but you can paste URLs in bulk directly.
I tested that by dropping in 1M+ links — the interface didn't complain or cap it.
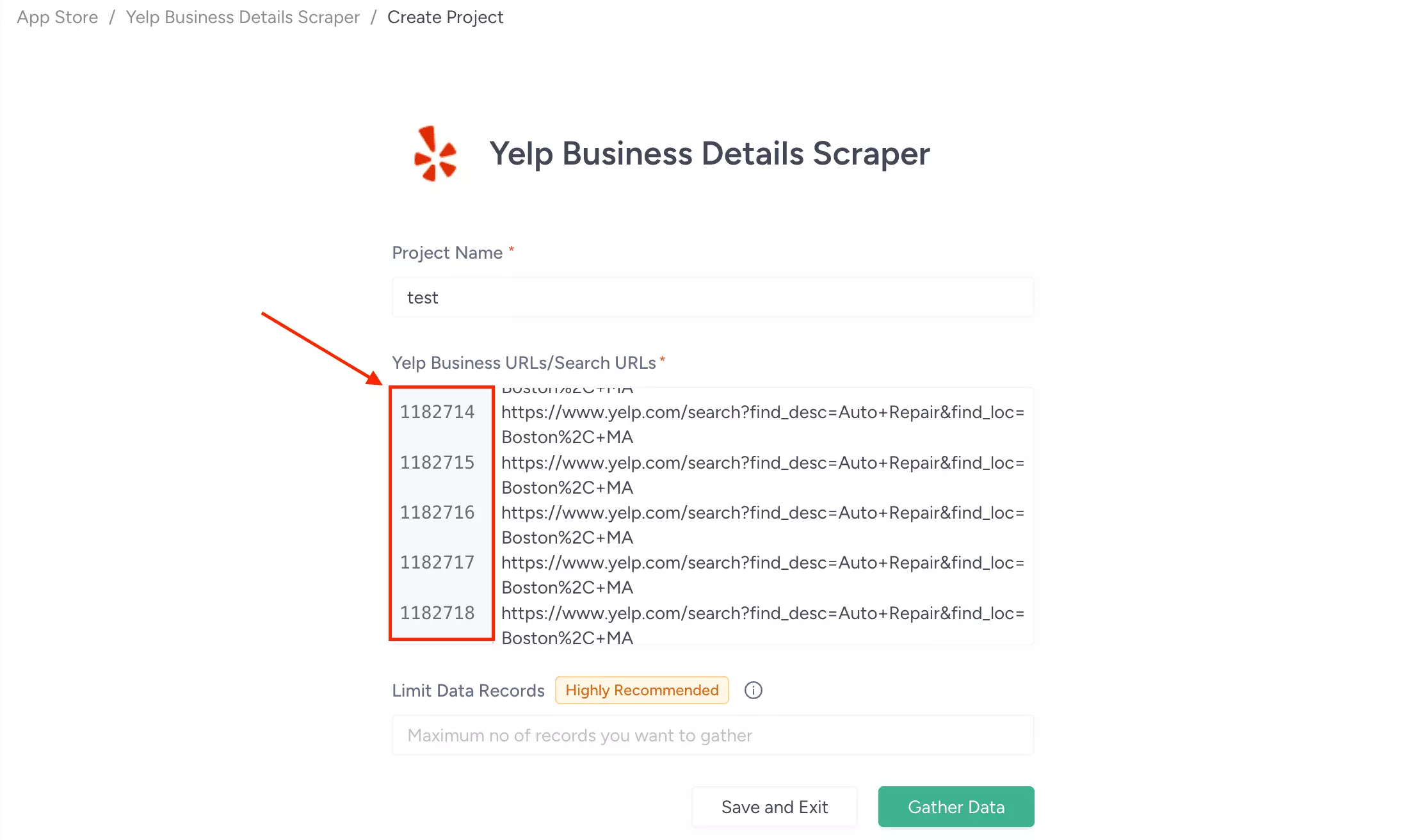
That's a UI capability, not an execution one. At 308 minutes per 1,000 results with no concurrency, processing 1M URLs would take over 20 months.
There's no concurrency or parallel run setting, so you can't control how aggressively the scraper works through the list.
The monthly ceiling is roughly 47K results/month — scaling up means waiting longer, not running faster.
ScrapeHero is moderately stable.
Output is consistent and costs are credit-based, but there is no concurrency control — throughput is fixed, so large jobs scale only by waiting longer.
Ease of use
The setup is project-based — name your project, paste your URLs, and hit "Gather Data."
It accepts both business URLs and search URLs in the same input field.
You can set a results cap before the run starts, so you're not pulling more than you need.
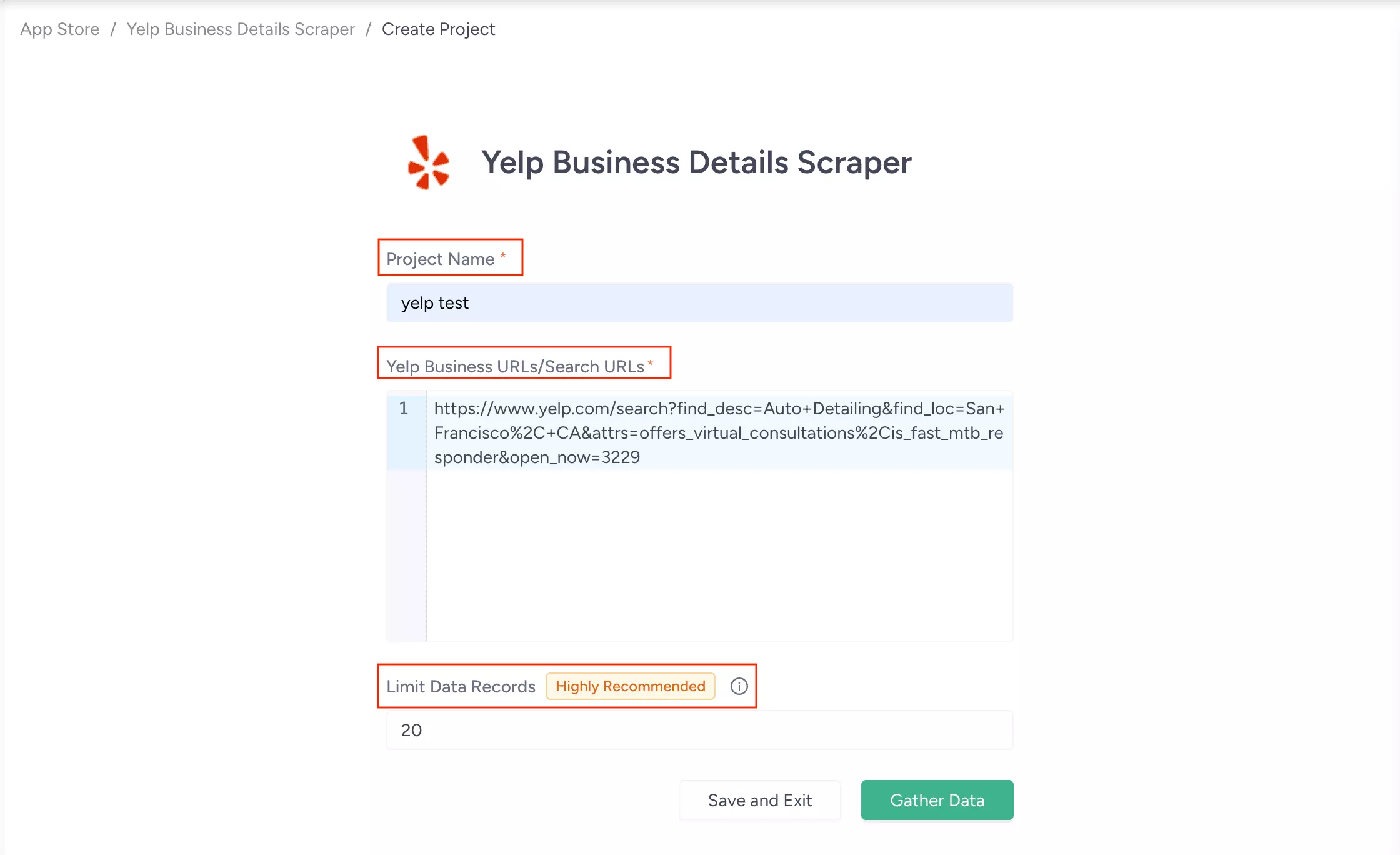
There's no deduplication or "unique results" toggle.
If your URL list overlaps, you'll see repeats and have to clean them after export.
The right side panel has a Help section worth mentioning.
It has a Data Credit Calculator that shows exactly how many credits a run will cost before you start — no surprises after the fact.
There's also a setup guide that walks you through each field. Both are handy if it's your first time.
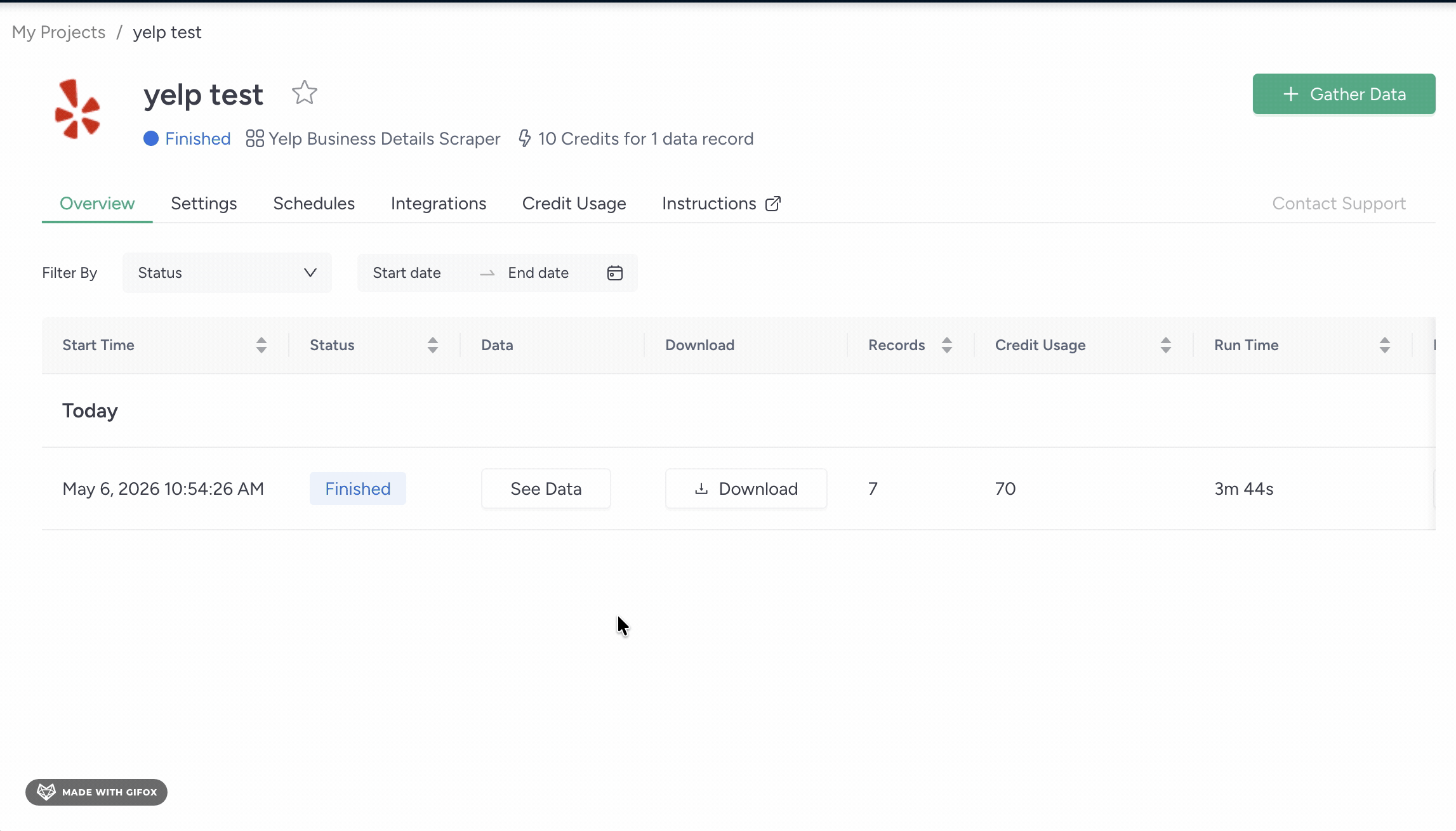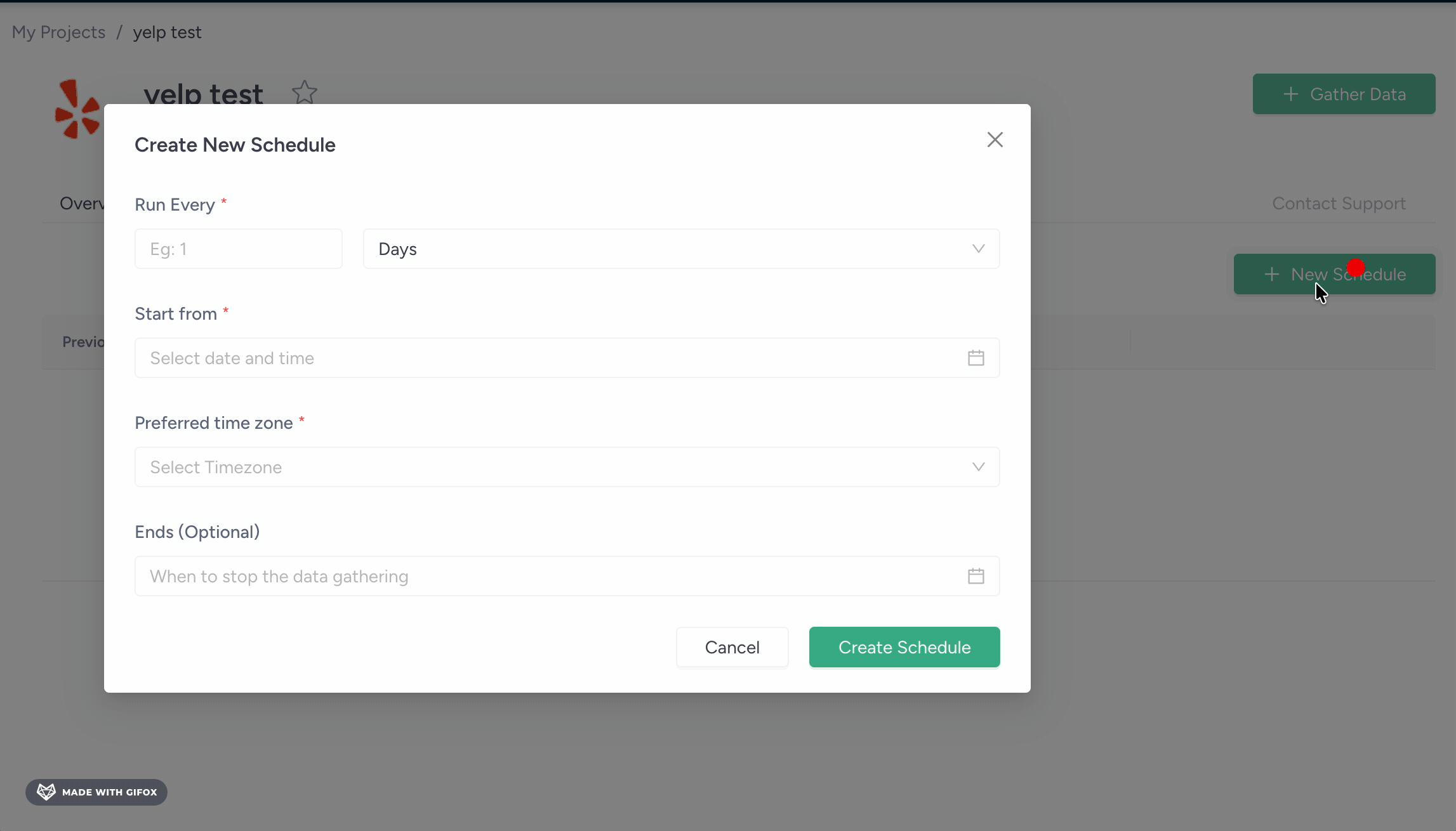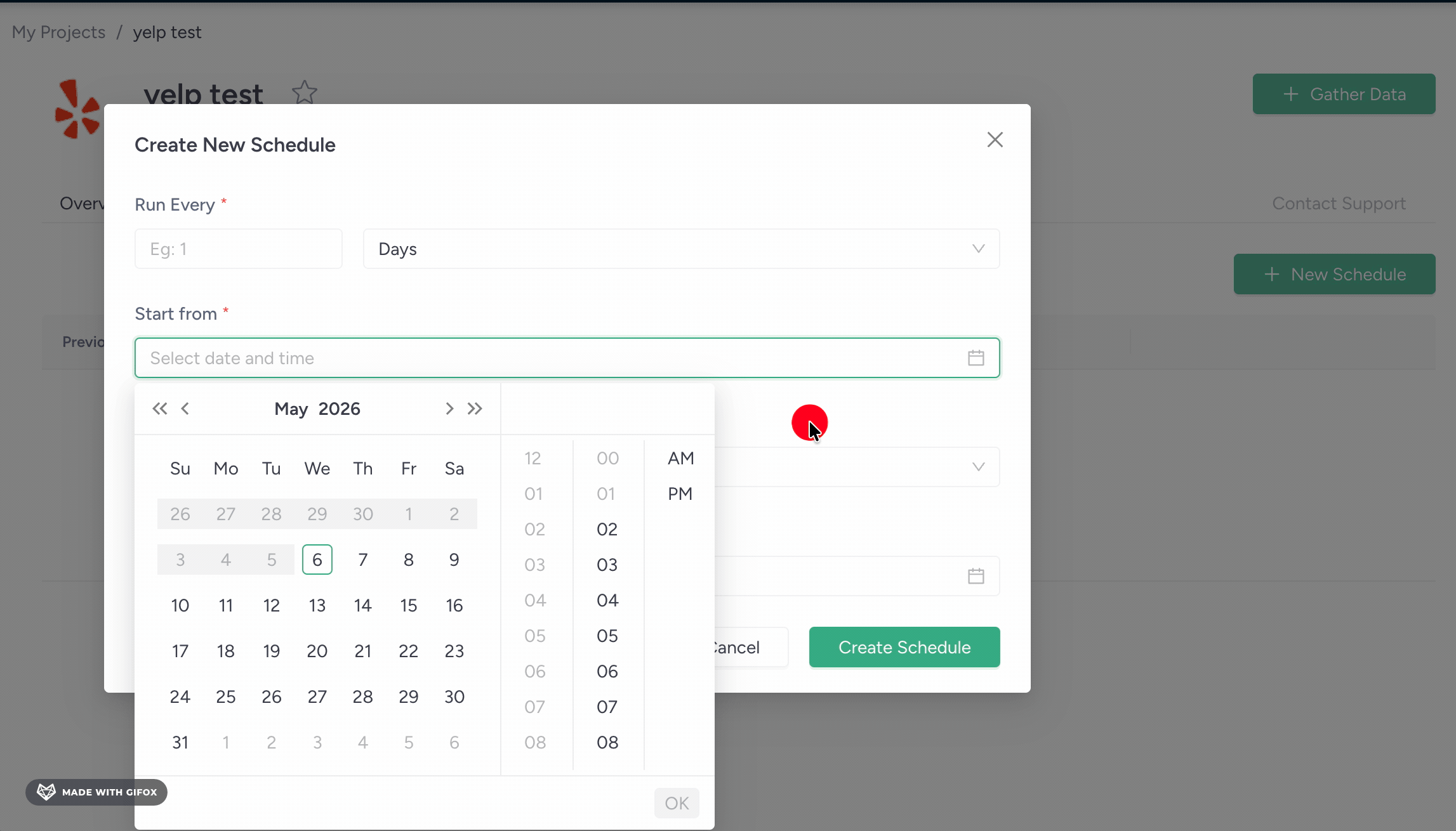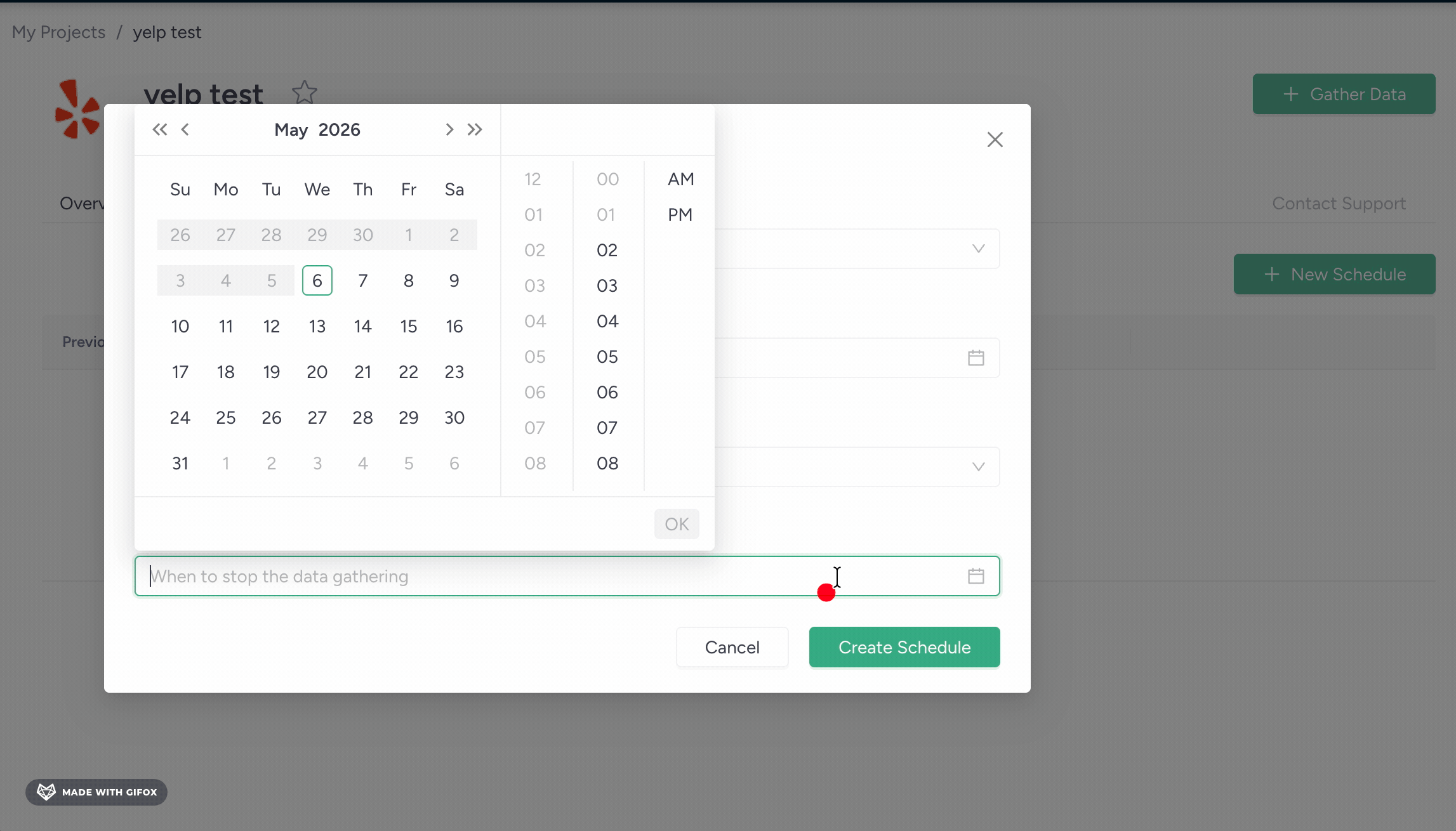
Scheduling is available, but it lives outside the main setup flow — you configure it after the run, not before.
You can adjust frequency, start date, timezone, and an optional end date.
Export is straightforward: CSV, JSON, and Excel directly from the results page.
Integration options are also multiple — Google Drive, Dropbox, and Amazon S3 for storage, plus a REST API for automation.
Speed
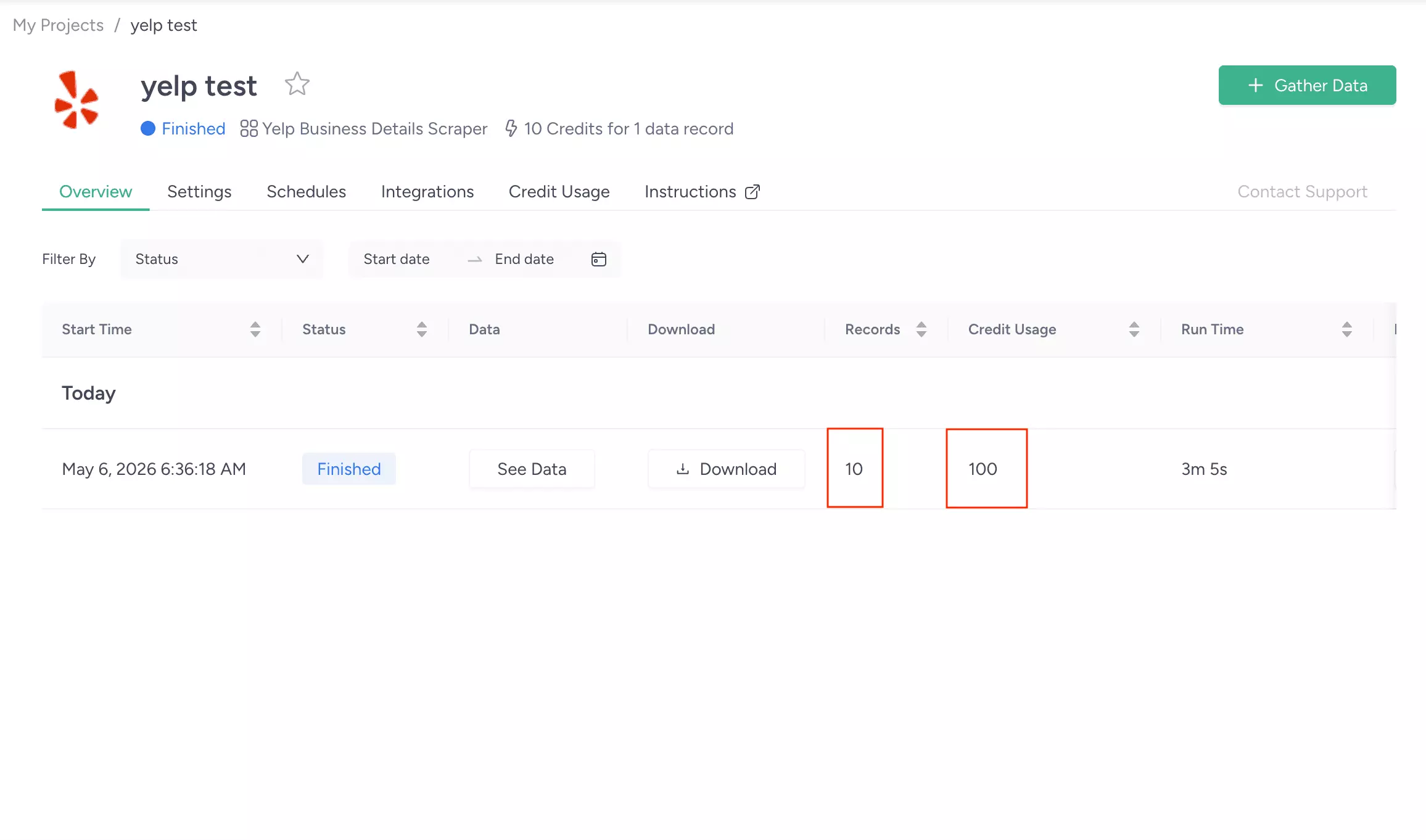
ScrapeHero collected 10 records in 3 minutes 5 seconds.
That's roughly 308 minutes for 1,000 results.
Clean run, no failures.
Customer support
There's no live chat support here.
Instead, you get a help center that funnels you into FAQs and "common issues" articles.
In practice, you're expected to dig through documentation first.
If you still can't find what you need, you can submit a support ticket.
It works, but it's a bit tedious.
Best for
If those fields drive the work, ScrapeHero gives you something the others can't.
If those fields aren't in your brief, the cost and speed don't justify it.
WebScraper.io
| Pros | Cons |
|---|---|
| Concurrency via Parallel tasks | Most expensive |
| Multiple export formats | No deduplication |
| Rich cloud delivery |
Key features
- 10 data fields per listing
- Bulk Start URL Import via Text or CSV (up to 20,000 URLs)
- Concurrency via Parallel tasks
- Schedule recurring scrapes
- Export to CSV, JSON, and XLSX
- Cloud delivery to Dropbox, Google Sheets, Google Drive, Google Cloud Storage, Amazon S3, and Azure
- Cloud-based, no installation needed
Data
WebScraper.io returns 10 fields per listing.
Here are all 10 fields:
| 🔗 business_url | 📄 business_name | 🏷️ categories | ⭐ rating |
| ⭐ review_count | 📍 address | 📞 phone_number | 🔗 website_url |
| 🖼️ images | 📅 opening_hours |
Nothing here is exclusive—every field shows up in at least one of the other tools.
The set is practical. It's enough to build a basic contact list or run a quick market scan.
What you don't get: price tier, claimed/verified status, open/closed status, coordinates, amenities, or email.
So it works for "who's here," not "who's worth prioritizing."
Affordability
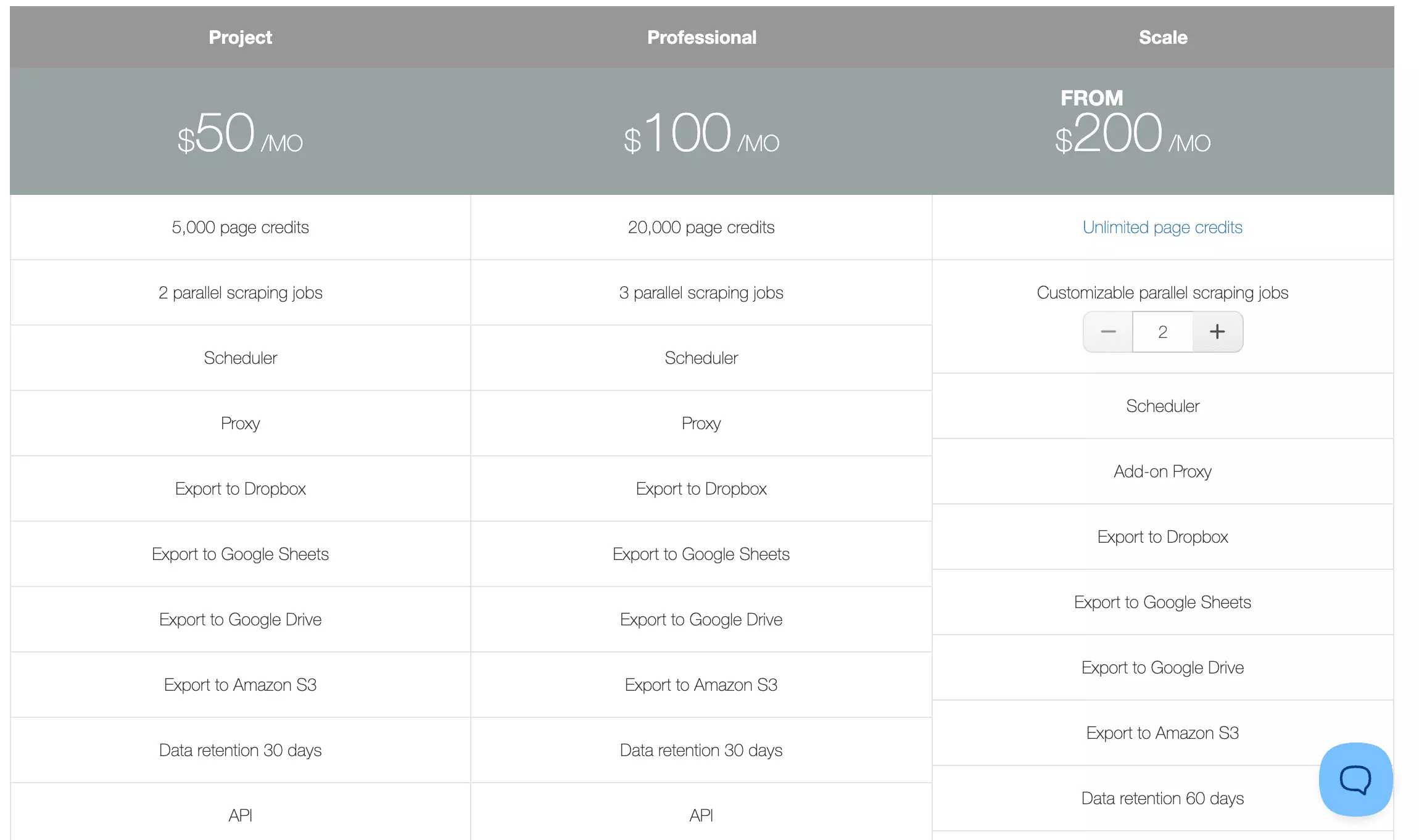
WebScraper.io runs on a monthly subscription model with a free 7-day trial, so you can test it before committing.
The pricing model is worth understanding before you run anything.
It's based on URL credits, where 1 credit = 1 page loaded by the cloud scraper — not 1 result.
That makes costs harder to predict upfront than a flat per-result rate.
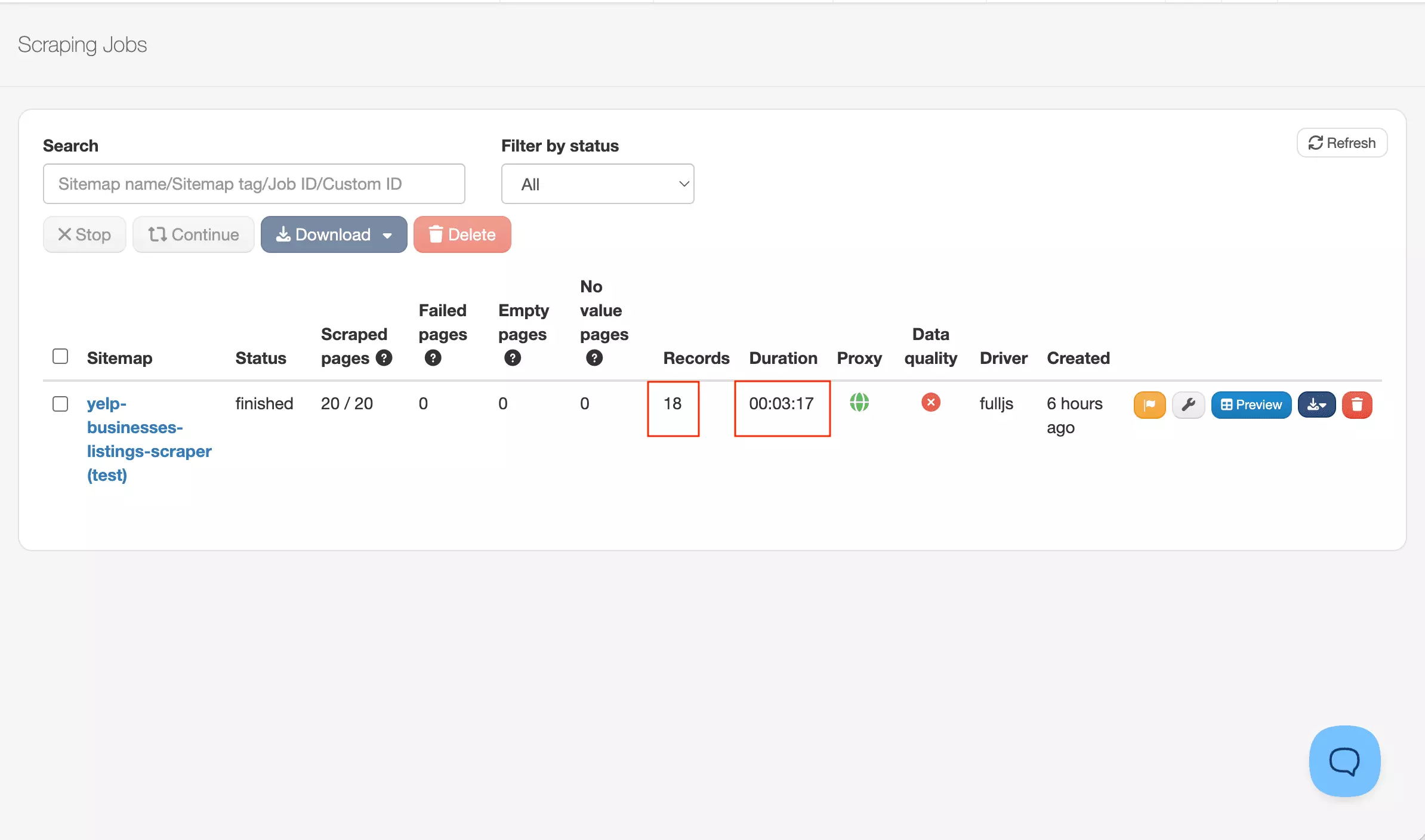
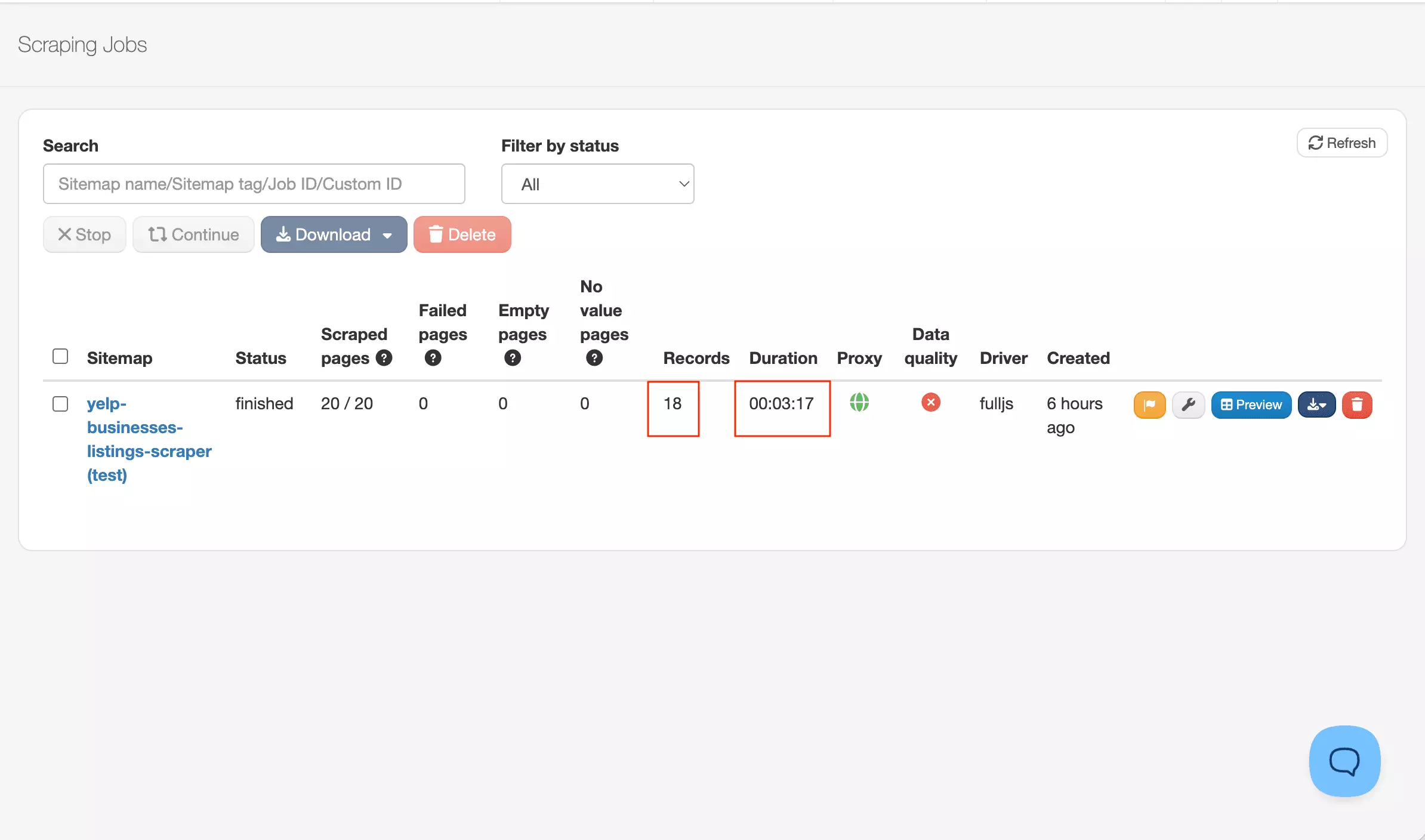
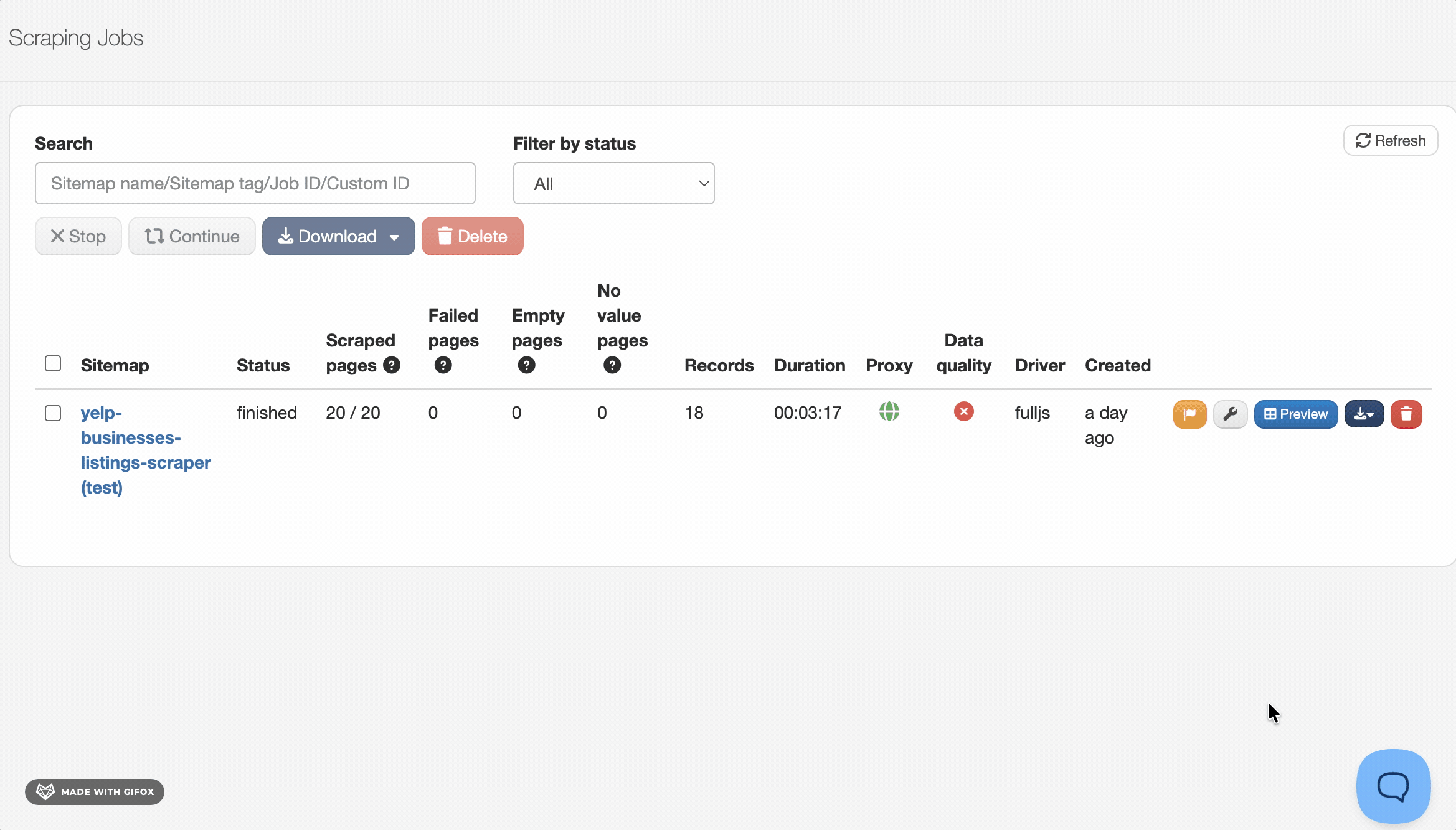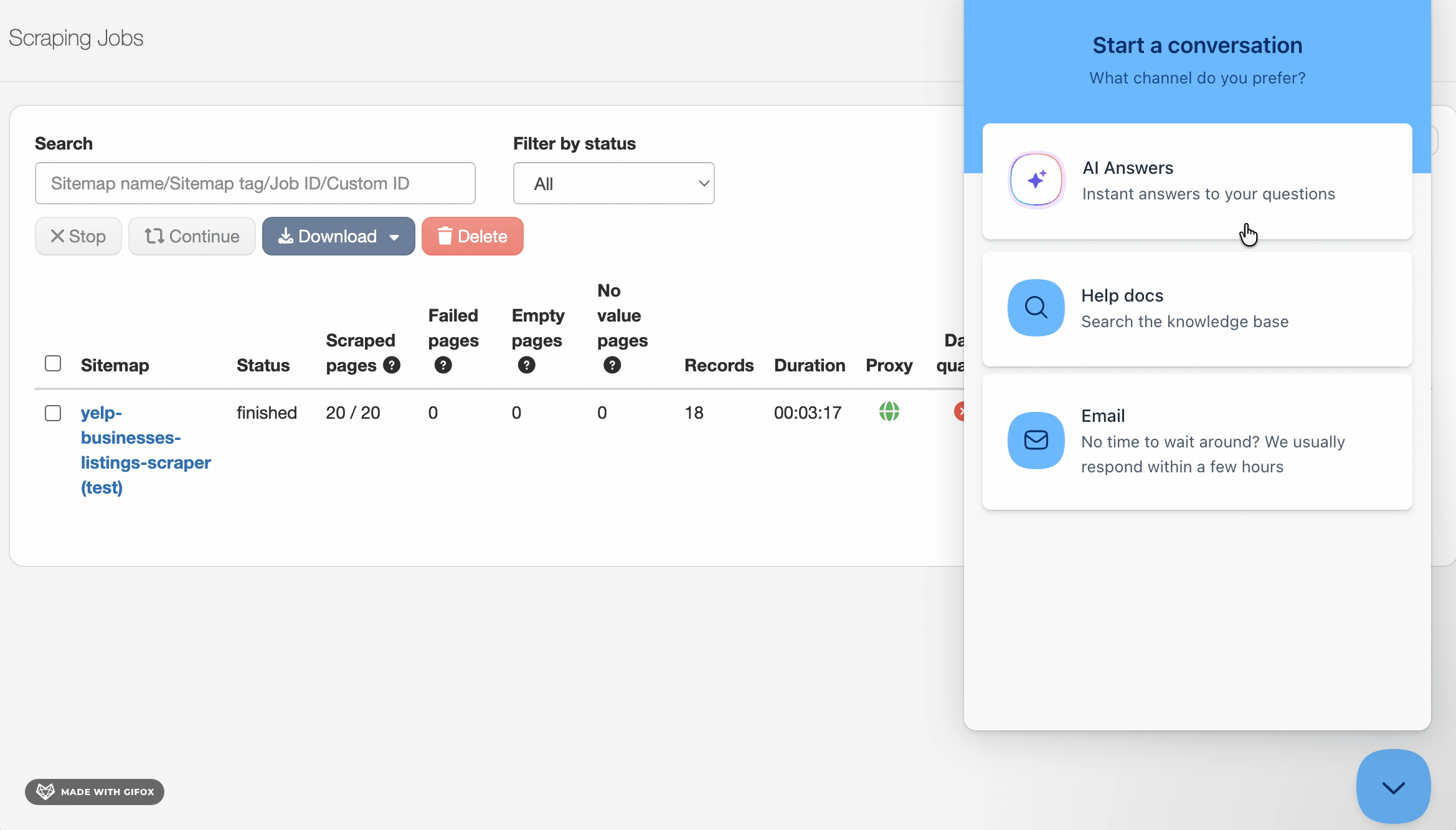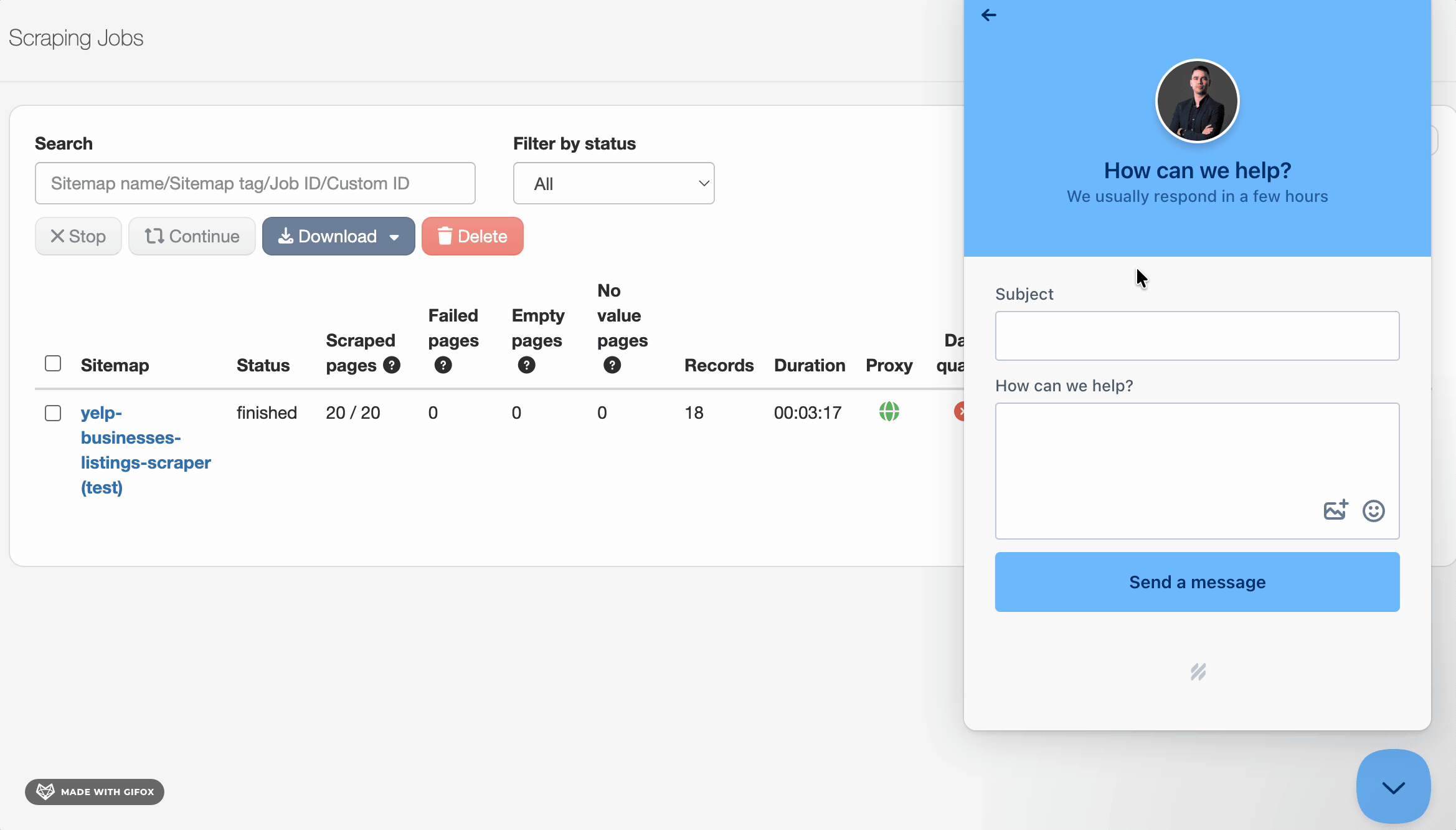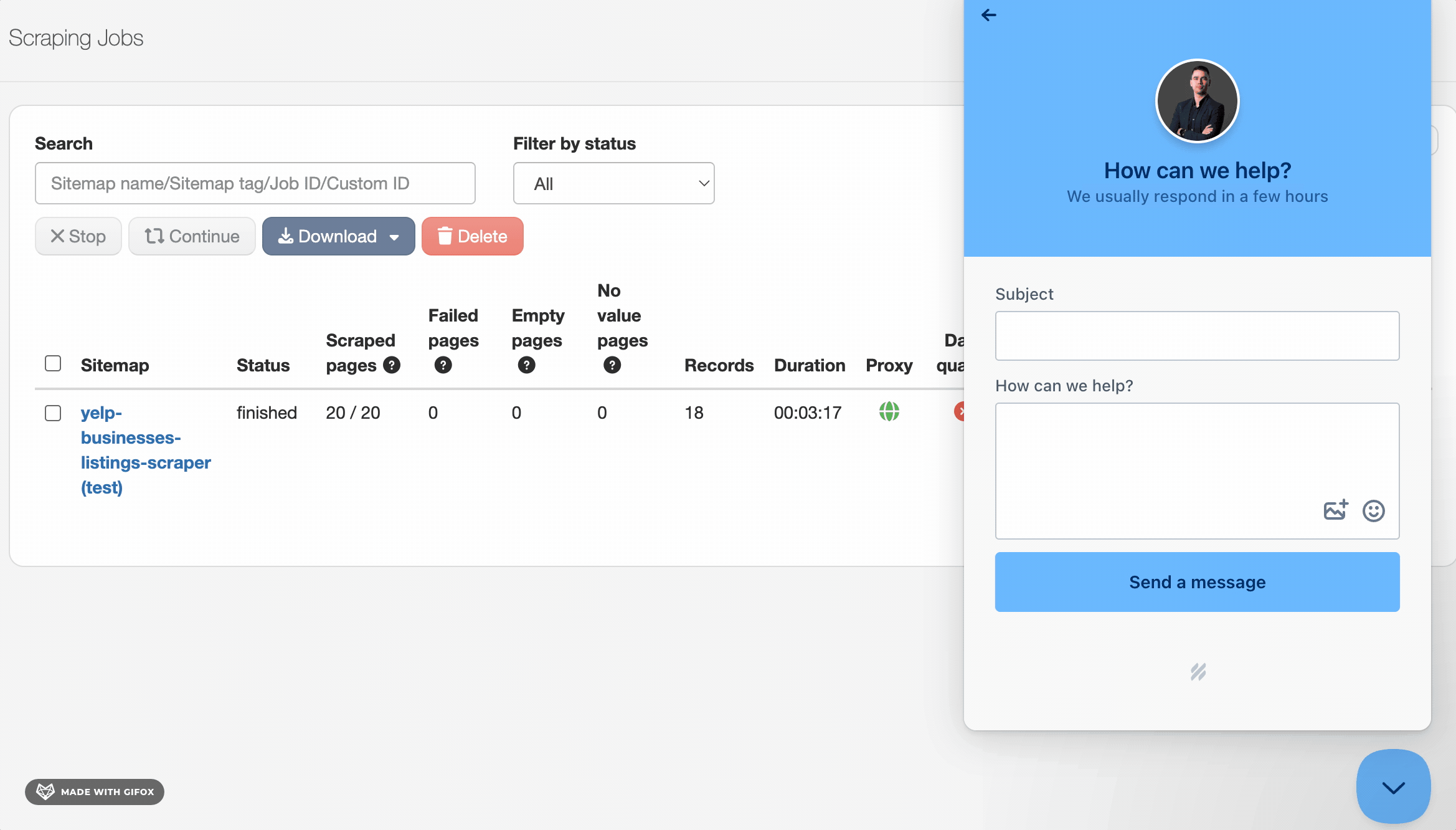
In my Yelp run, it loaded 20 pages and returned 18 records — roughly 1.1 pages per result.
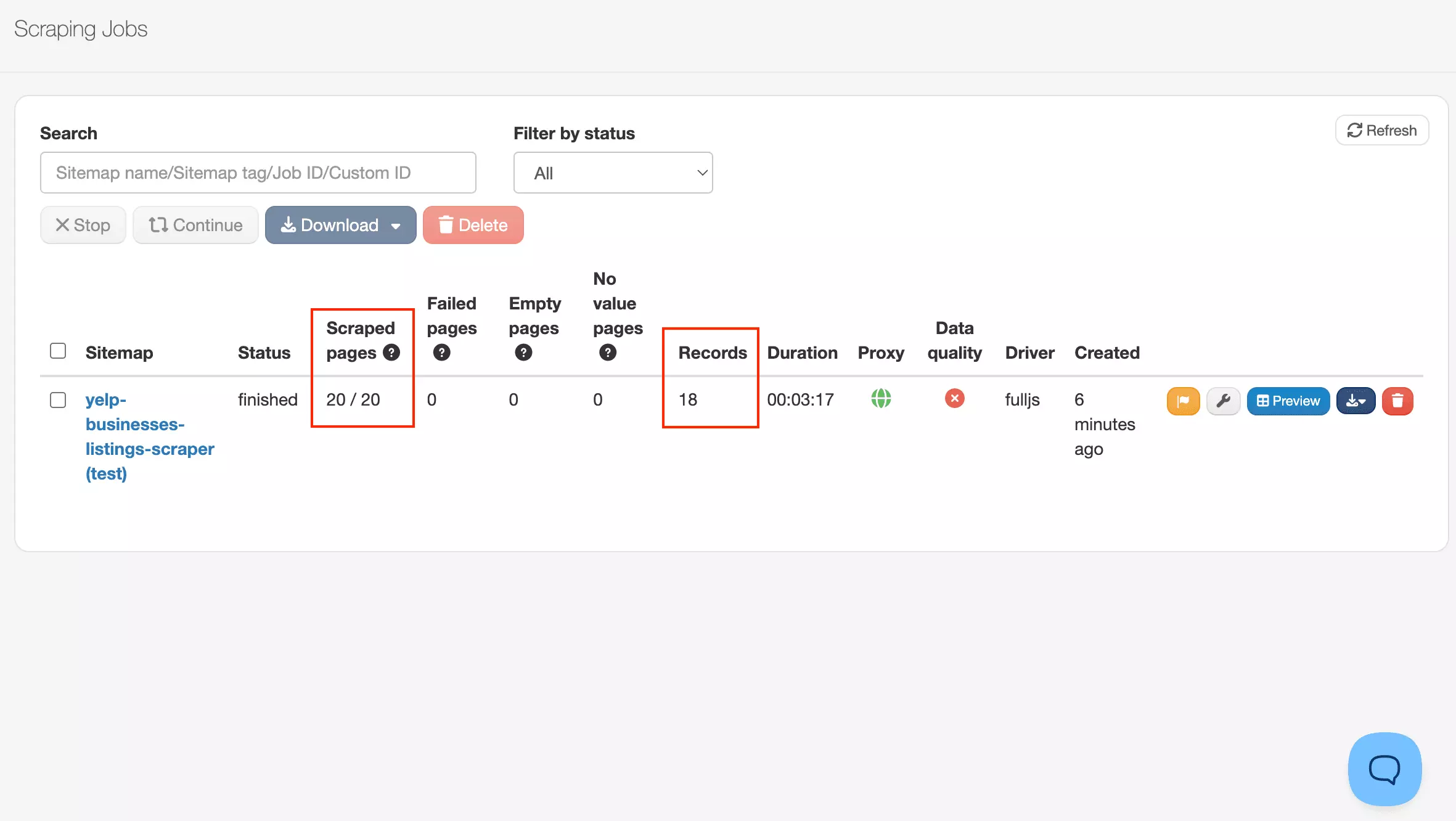
So 1,000 results took roughly 1,100 URL credits in this setup. Based on the plan limits, that works out to approximately:
- Project: $11 per 1,000 results
- Professional: $5.50 per 1,000 results
In practice, you'll pay more than you expect if you assume pages = results.
Scalability
WebScraper.io handles bulk input cleanly.
You can upload start URLs via Text or CSV file — up to 20,000 URLs.
Choose to either Replace or Append to an existing list.
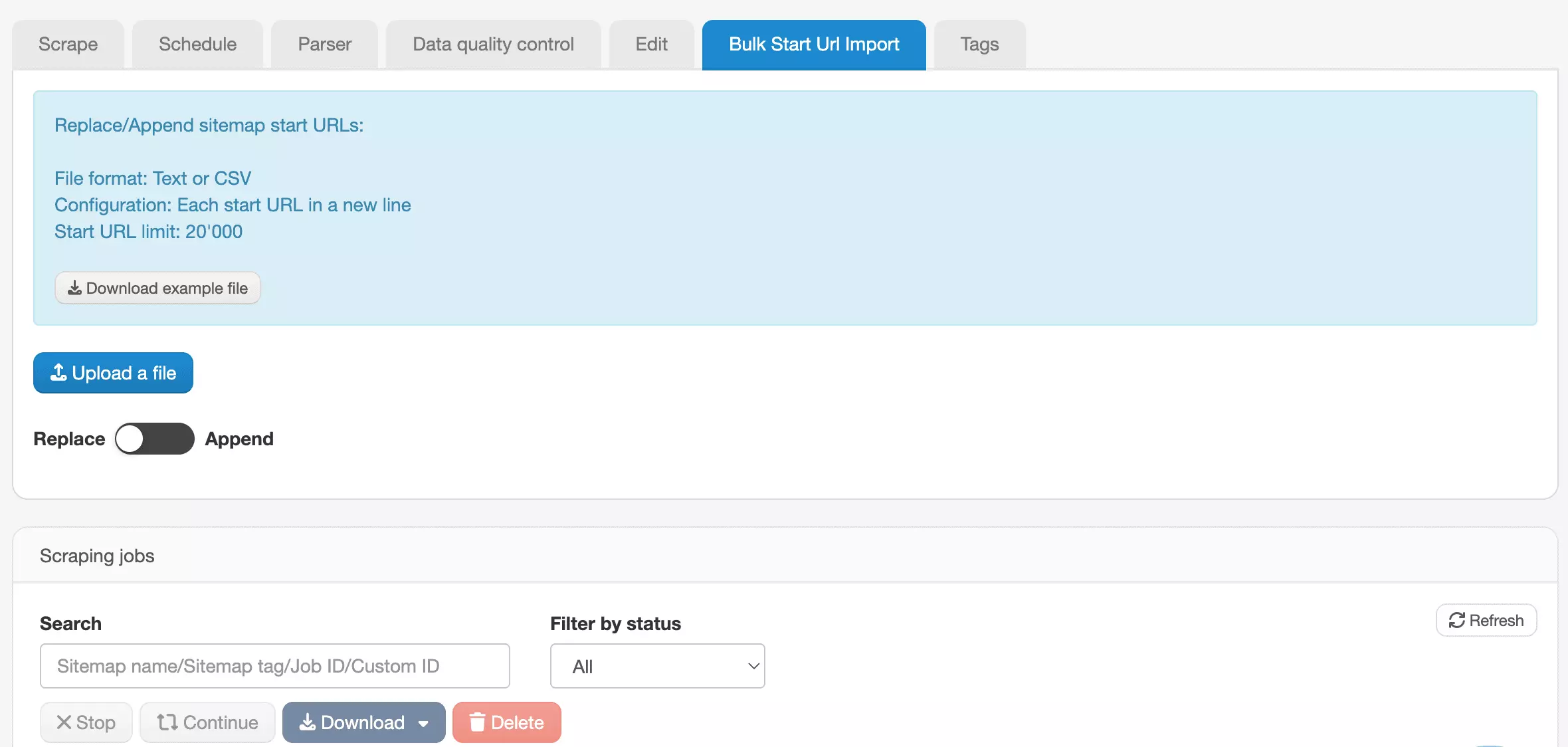
The Append option is useful for recurring scrapes that build on a previous input rather than starting from scratch.
On the output side, WebScraper.io supports concurrency via Parallel tasks, so you can control how many scraping jobs run at the same time.
At 182 minutes per 1,000 results, the baseline monthly ceiling is roughly 79K results/month — and that scales up as you add more parallel tasks.
WebScraper.io is stable at scale. Parallel tasks give throughput control, output is consistent, and the Replace/Append option keeps recurring input manageable.
Ease of use
WebScraper.io is URL-first workflow.
Paste a URL and WebScraper.io immediately matches it to a scraper.
Two template options appear — business listings and business pages.
The right one is pre-selected based on your URL.
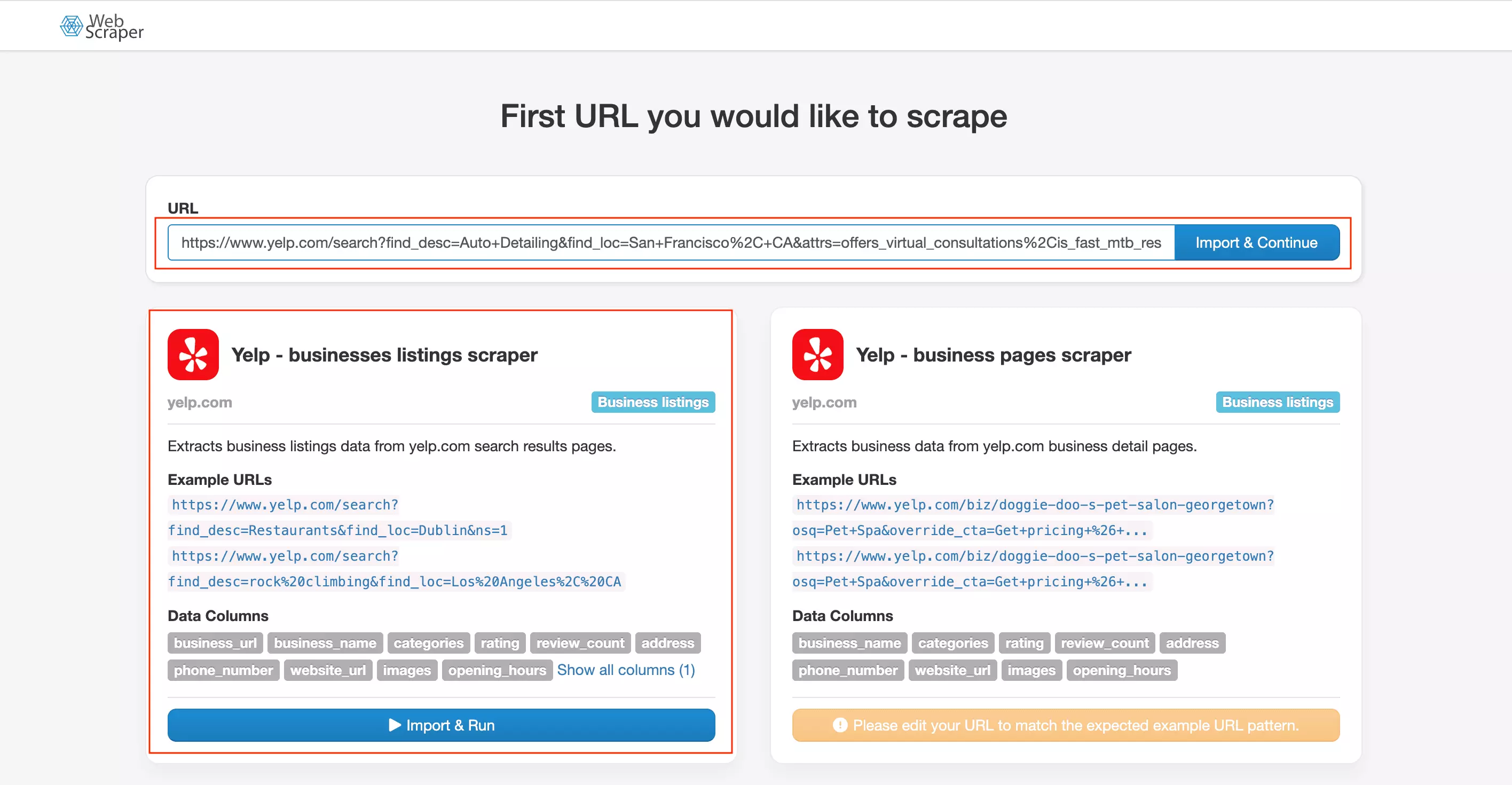
That part is genuinely useful.
But there's no confirmation step — clicking "Import & Run" fires the scrape immediately with no settings, no limit, nothing to configure.
For first-time users, that's disorienting. You lose control before you even find it.
There's no deduplication or 'unique results' setting either, so duplicate cleanup happens after export.
Scheduling exists but lives in a separate tab — not immediately obvious how to find it.
Export is simple and direct — CSV, JSON, and XLSX available straight from the jobs table with one click.
Data delivery options are broad — Dropbox, Google Sheets, Google Drive, Google Cloud Storage, Amazon S3, and Azure Blob Storage are all supported.
Speed
WebScraper.io returned 18 records in 3 minutes 17 seconds.
That's roughly 182 minutes for 1,000 results — reliable for small runs.
Customer support
Customer support is available through a live chat, and email.
There is an AI assistant on the platform.
Email support claims a response within a few hours.
I didn't manage to break anything badly enough to test that, so I'll take their word for it.
Best for
Pick this when the job is small and the priority is getting started quickly.
Paste a URL, the template is pre-selected, you're running in minutes — no decisions to make upfront.
The cost per 1,000 is the highest on this list. That's fine for occasional spot checks. It's a problem if the list is long.
FAQ
Can I scrape email addresses from Yelp business listings?
Yelp doesn't surface business emails on its pages.
The only tool here that returns emails is lobstr.io — it visits each business's own website to find a contact address.
Can I resume a Yelp scrape without re-pulling records I've already collected?
Not natively, across any of the five tools.
lobstr.io's deduplication toggle removes duplicates within a single run — it doesn't track what was collected in previous runs.
Which is the cheapest tool for scraping Yelp at scale?
Apify is the cheapest at a flat $1.00 per 1,000 results with a free tier — but the reliability problems make it risky at scale.
lobstr.io's Team plan comes out to $0.50 per 1,000 results without contact collection — the lowest cost for reliable output.
Which Yelp scraper is the most reliable?
lobstr.io is the most reliable tool on this list. It returned consistent results across every test run, with no zero-result failures.
It has built-in deduplication and returns 30 fields — the most complete data of any tool here, including emails.
At scale, it also comes out the cheapest — $0.50 per 1,000 results on the Team plan without contact collection.