
Best Reddit Scrapers 2026 [No-Code + API Edition]
TL;DR
- I tested five Reddit scrapers across data quality, pricing, speed, scalability, and ease of use.
- Apify returned the most complete dataset, with 95.5% comment coverage, reply trees to depth 9, and 8 seconds per 1,000 results.
- lobstr.io offers a managed workflow with scheduling, deduplication, alerts, reusable jobs, and flexible exports.
- ScraperAPI is the cheapest option, but its schema is limited and it does not preserve comment relationships.
- Bright Data includes useful moderation fields, but billing can be unpredictable — one 30-row test was billed for 982 discovered records.
- SociaVault is simple and subscription-free, but limited coverage, no scheduling, and JSON-only exports make it better for occasional API jobs.
If you've tried to get Reddit data, you know how it goes.
Finding one that actually holds up means testing them yourself. Until now.
I tested 5 tools — 2 with no-code interfaces, all accessible via API — against the same dataset. Here's what actually works.
Quick Comparison
| lobstr.io | Apify | ScraperAPI | Bright Data | SociaVault | |
|---|---|---|---|---|---|
| No-code UI | ✅ | ✅ | ❌ | ❌ | ❌ |
| API access | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes comments | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes posts | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes subreddits | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes user profile | ✅ | ✅ | ✅ | ❌ | ❌ |
| Scrapes search | ✅ | ✅ | ✅ | ✅ | ✅ |
| Comment depth | 2 levels | 9 levels | Flat | 2 levels | 2 levels |
| Comment capture rate | 41.9% | 95.5% | 84.2% | 34.2% | 34.1% |
| Fields per post | 39 | 68 | 9 | 29 | 26 |
| Fields per comment | 39 | 39 | 4 | 35 | 15 |
| Thread speed (min / 1K results) | 8 min | 0.13 min | 4.5 min | 3.4 min | 5.1 min |
| Free tier | ✅ | ✅ | ❌ | ❌ | ❌ |
| Pricing model | Subscription | Subscription | Subscription | Pay-as-you-go + subscription | One-time packs |
| Cost per 1K results (entry / scale) | $2.00 / $0.50 | $2.00 / $1.50 | $0.011 / $0.002 | $1.50 / $1.30 | $0.30 / $0.12 |
| Monitoring / scheduling | ✅ | ✅ | ✅ | ❌ | ❌ |
| Webhook support | ✅ | ✅ | ❌ | ✅ | ❌ |
| Export formats | CSV, JSON, XLS, Sheets, S3 | CSV, JSON, XLS, XML, Sheets, S3 | JSON | JSON, CSV, XLS, Parquet + cloud | JSON |
| Programmatic access | API + MCP + SDK + CLI | API + MCP + SDK + CLI | API + MCP + SDK + CLI | API + MCP + SDK + CLI | API + MCP + CLI |
| Overall score | 3.5/5 | 4.3/5 | 3.5/5 | 2.8/5 | 3.7/5 |
But hold up… is it legal?
⚠️ Disclaimer
The information in this section is for general informational purposes only. It reflects publicly available sources and my own interpretation of them.
It does not constitute legal advice and should not be treated as such. Laws vary by jurisdiction and can change.
If you need guidance on compliance, data use, contracts, or platform-specific risks, consult a qualified legal professional who can evaluate your situation in detail.
Is it legal to scrape Reddit?
Yes, it's legal under certain conditions.
Reddit's Terms of Service restrict scraping without permission. Breaking those terms is usually a contract issue, not a criminal one — but it can get your IP blocked and your account banned.

Copyright and privacy also matter. Republishing posts at scale, or using identifiable user data for profiling, can create legal problems.
How to stay on the right side:
- Collect data internally — research, analysis, model training
- Don't republish Reddit content on a public-facing surface
- Don't combine with PII for profiling without a legal basis
- Respect rate limits — don't hammer the platform
How I chose the best Reddit scrapers
I started with Reddit threads, developer forums, and community discussions to identify the problems users repeatedly complained about.
Based on that, I narrowed the criteria to 5 pain points.
- Data
- Cost
- Usability
- Scalability
- Speed
Data
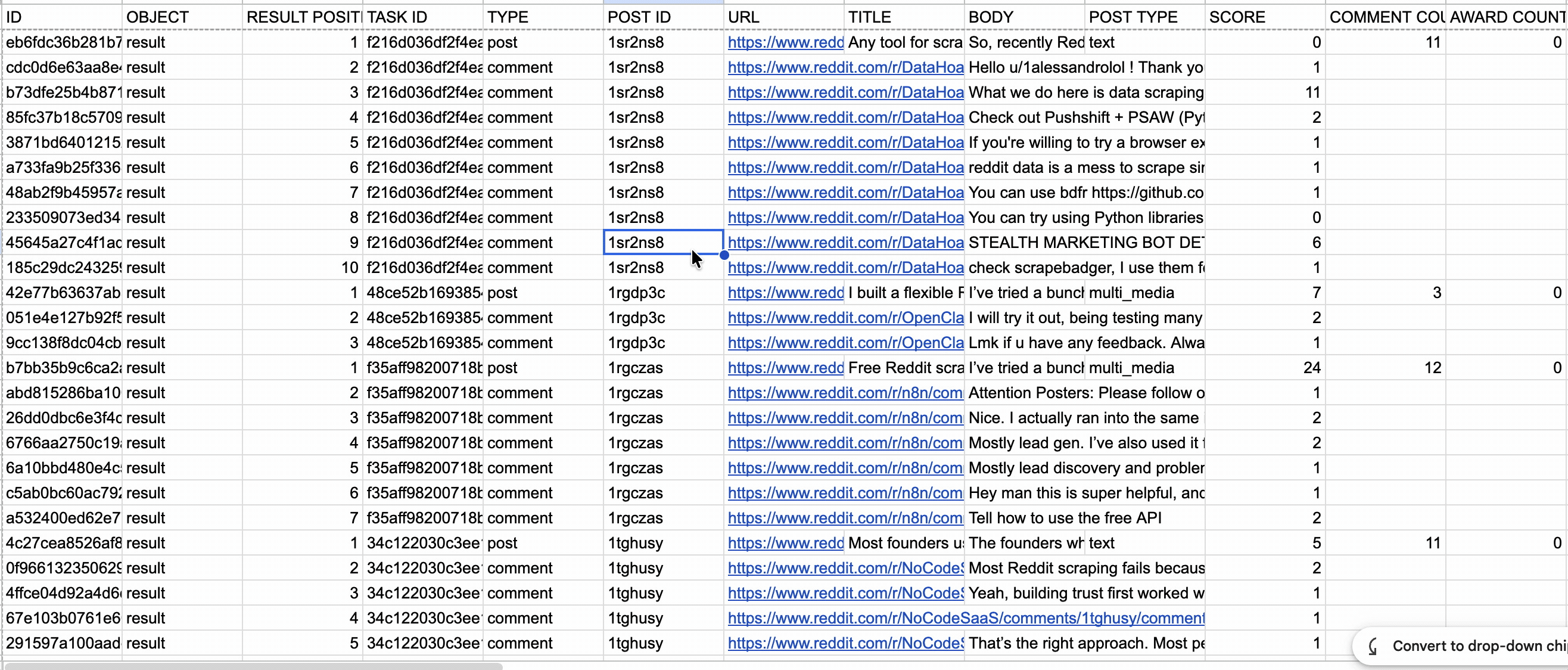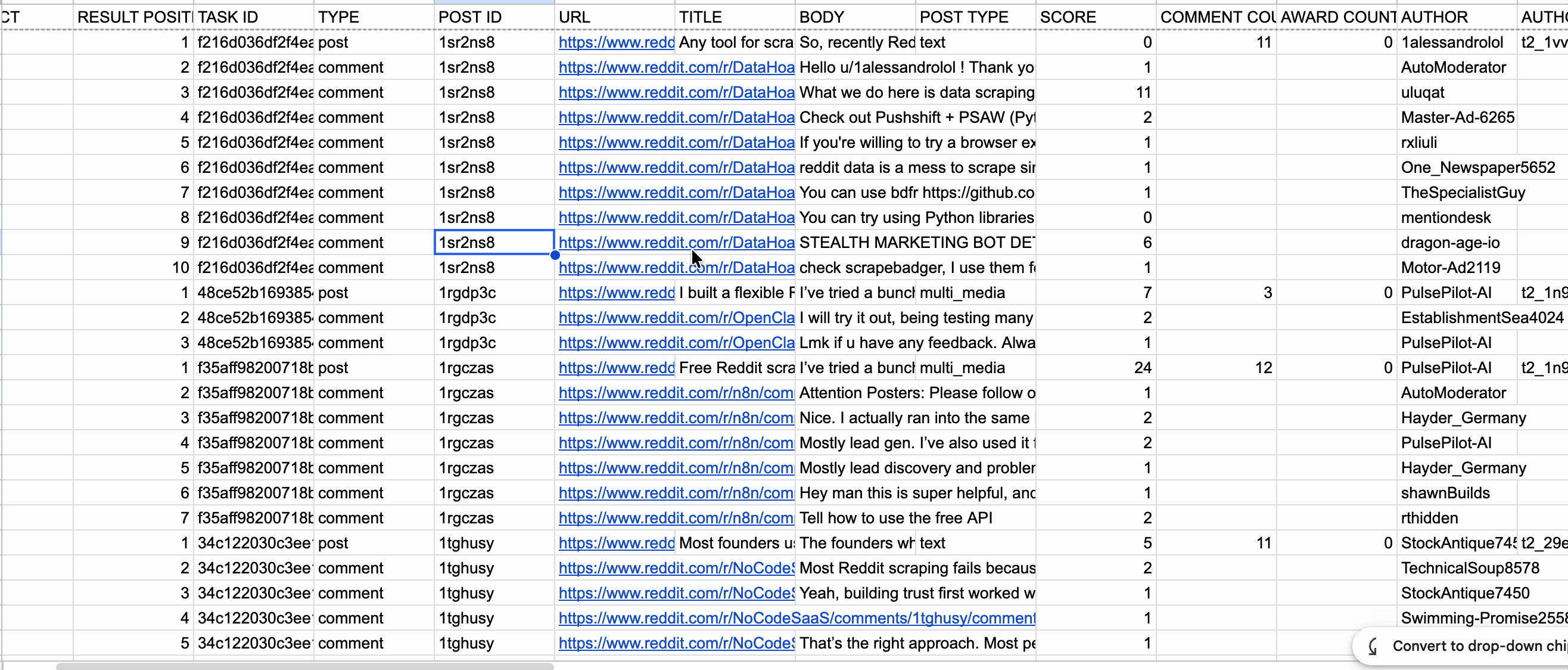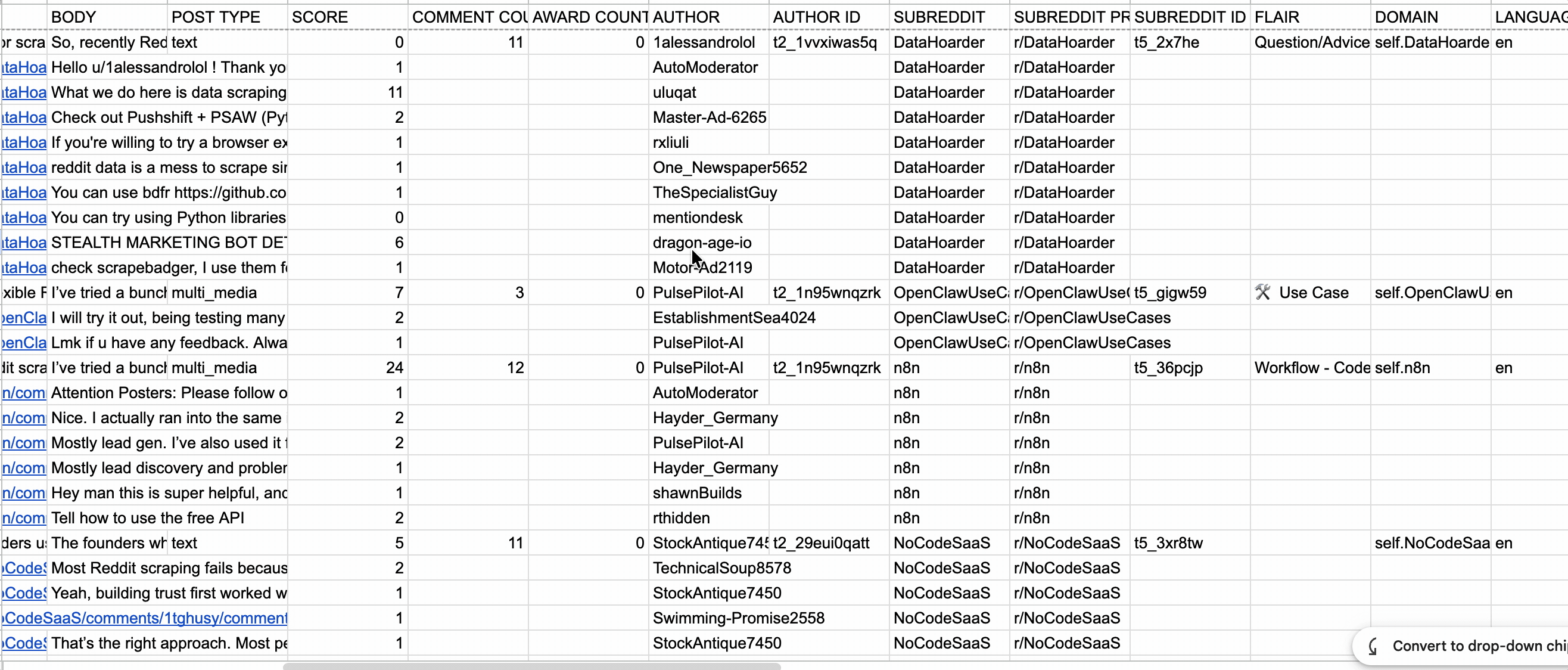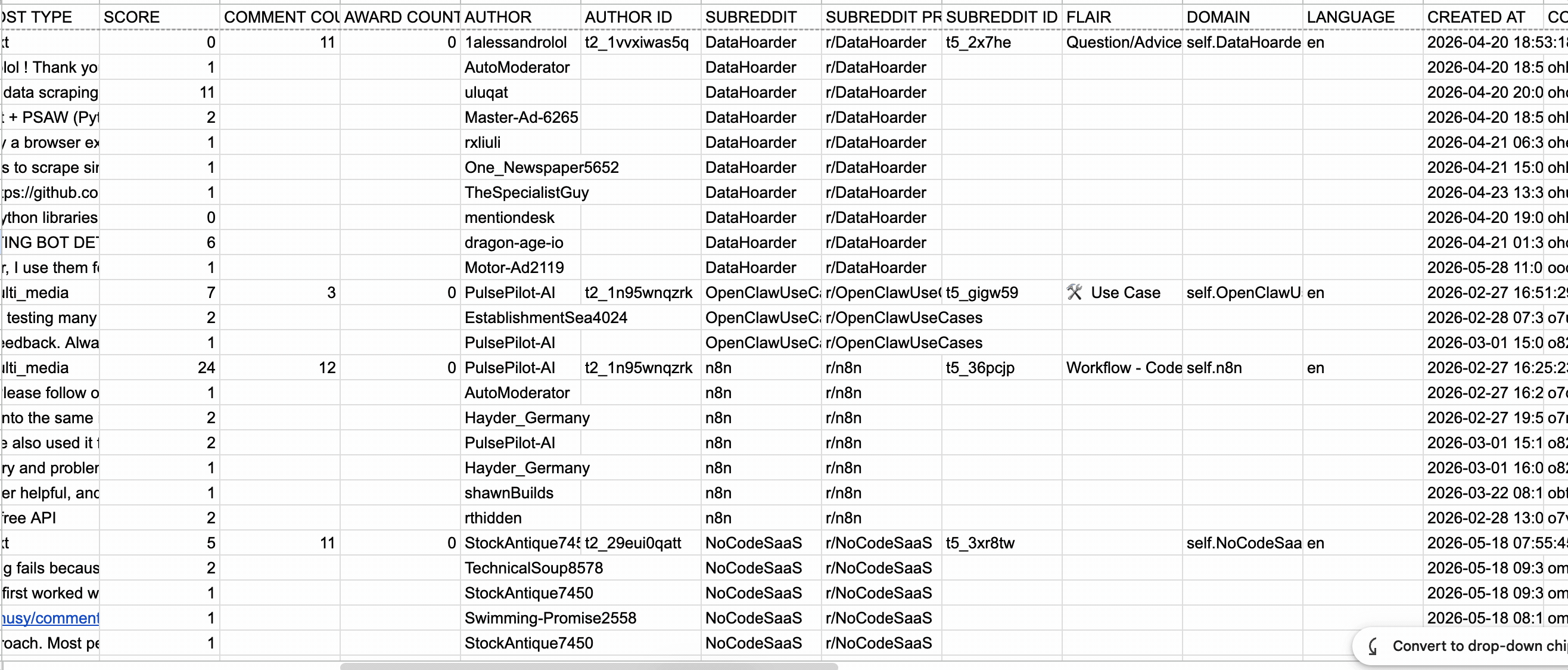
I measured data through richness, depth, and coverage.
- Richness measured the useful metadata returned with each result.
- Depth measured how far each tool followed nested replies and whether it preserved parent-child relationships.
- Coverage measured how many comments each tool returned against Reddit's displayed total across 20 post threads.
Cost
I normalized pricing to cost per 1,000 results at both entry-level and scale pricing.
Usability
I evaluated usability through input support, filtering, and ease of use.
- Input support covered post URLs, subreddit URLs, profile URLs, search URLs, and bulk input options.
- Filters covered date ranges, sorting, language, keywords, and controls for including posts or comments.
- Ease of use covered the full workflow, from setup and job execution to export formats and integrations.
Scalability
I estimated how many rows each scraper could collect in 30 days if it ran continuously.
I multiplied each tool's measured rows per minute by the total minutes in a 30-day month.
Where concurrency was available, I treated it as a separate multiplier.
Speed
I used the same 20-thread benchmark with full comment collection enabled.
I measured the total time needed to return the maximum available results, then normalized it to minutes per 1,000 results.
The best Reddit scrapers
| lobstr.io | Apify | ScraperAPI | Bright Data | SociaVault | |
|---|---|---|---|---|---|
| No-code UI | ✅ | ✅ | ❌ | ❌ | ❌ |
| API access | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes comments | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes posts | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes subreddits | ✅ | ✅ | ✅ | ✅ | ✅ |
| Scrapes user profile | ✅ | ✅ | ✅ | ❌ | ❌ |
| Scrapes search | ✅ | ✅ | ✅ | ✅ | ✅ |
| Comment depth | 2 levels | 9 levels | Flat | 2 levels | 2 levels |
| Comment capture rate | 41.9% | 95.5% | 84.2% | 34.2% | 34.1% |
| Fields per post | 39 | 68 | 9 | 29 | 26 |
| Fields per comment | 39 | 39 | 4 | 35 | 15 |
| Thread speed (min / 1K results) | 8 min | 0.13 min | 4.5 min | 3.4 min | 5.1 min |
| Free tier | ✅ | ✅ | ❌ | ❌ | ❌ |
| Pricing model | Subscription | Subscription | Subscription | Pay-as-you-go + subscription | One-time packs |
| Cost per 1K results (entry / scale) | $2.00 / $0.50 | $2.00 / $1.50 | $0.011 / $0.002 | $1.50 / $1.30 | $0.30 / $0.12 |
| Monitoring / scheduling | ✅ | ✅ | ✅ | ❌ | ❌ |
| Webhook support | ✅ | ✅ | ❌ | ✅ | ❌ |
| Export formats | CSV, JSON, XLS, Sheets, S3 | CSV, JSON, XLS, XML, Sheets, S3 | JSON | JSON, CSV, XLS, Parquet + cloud | JSON |
| Programmatic access | API + MCP + SDK + CLI | API + MCP + SDK + CLI | API + MCP + SDK + CLI | API + MCP + SDK + CLI | API + MCP + CLI |
| Overall score | 3.5/5 | 4.3/5 | 3.5/5 | 2.8/5 | 3.7/5 |
1. lobstr.io
Overall score: 3.5/5
| Category | Score |
|---|---|
| Data | 3.5/5 |
| Usability | 3.5/5 |
| Speed | 3/5 |
| Cost | 3.5/5 |
| Scalability | 4/5 |
| Pros | Cons |
|---|---|
| Built-in scheduling | Keyword search requires a full Reddit search URL on no-code UI |
| Webhook + email alerts on run completion | Comment depth 2 levels |
| Concurrency available | Slowest thread scrape — 8 min per 1,000 results |
Data
Richness
39 unified fields per row — posts, comments, and user cards all share the same schema; unused fields are null.
Fields (39 unified)
| Category | Fields |
|---|---|
| Content | title, body, url, domain, post_type, language |
| Author | author, author_id, comment_karma, post_karma, karma, trophies, contributions, active_subreddits, moderated_subreddits |
| Comment-specific | comment_id, depth, parent_id |
| Post-specific | post_id, comment_count, award_count, flair, score |
| Subreddit context | subreddit, subreddit_id, subreddit_prefixed_name, subreddit_description, subreddit_rules, subreddit_resources, weekly_active_users, weekly_contributions |
| Row type | type, object |
| Meta | id, created_at, run, squid, scraping_time |
User profile
361 rows: 1 user card + 354 comments + 6 posts — full activity history.
Exclusive
Depth
Comments are collected up to two reply levels deep, depth=2.
Coverage
437 of 1,042 reported comments captured — 41.9%.
Cost
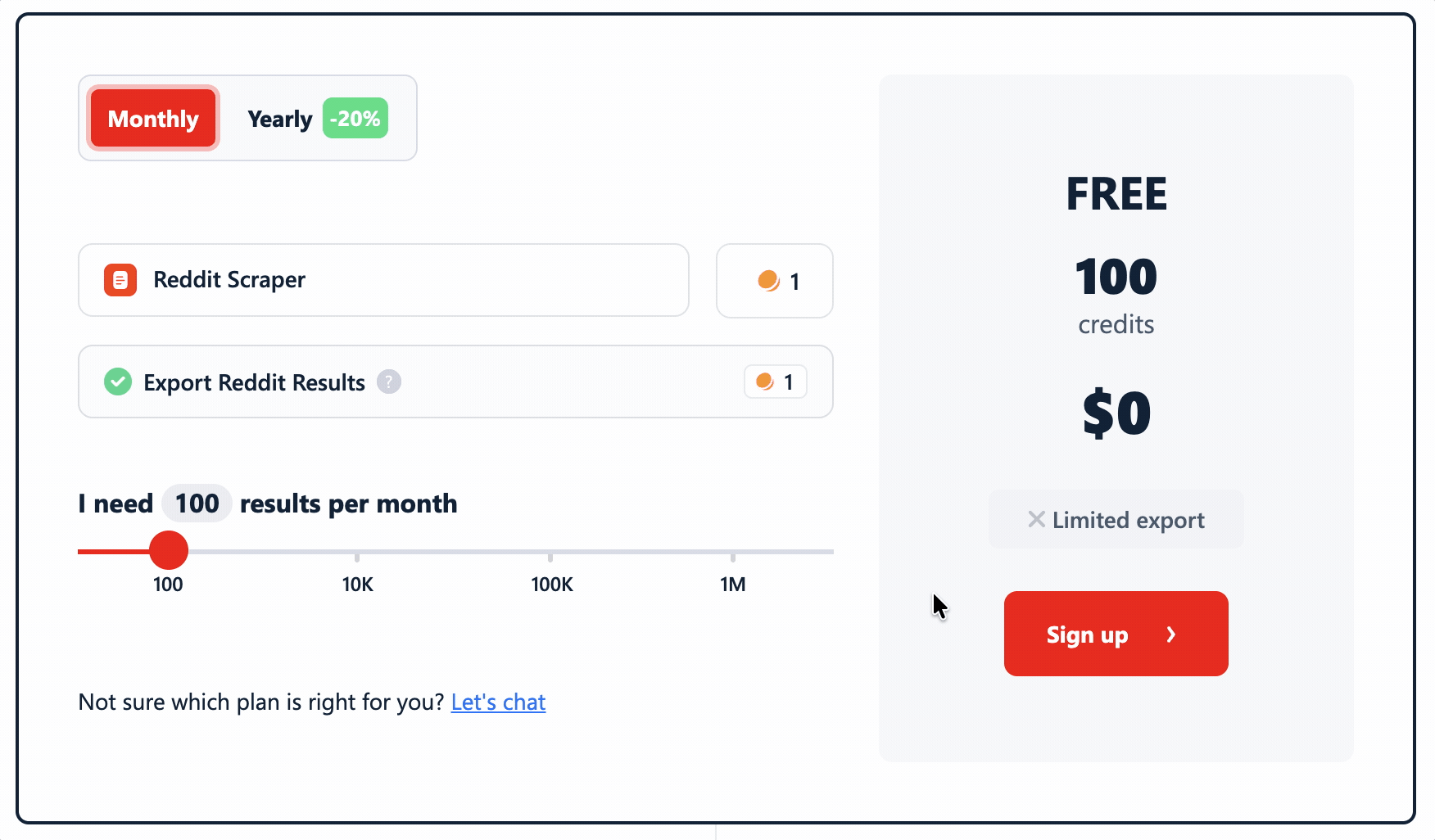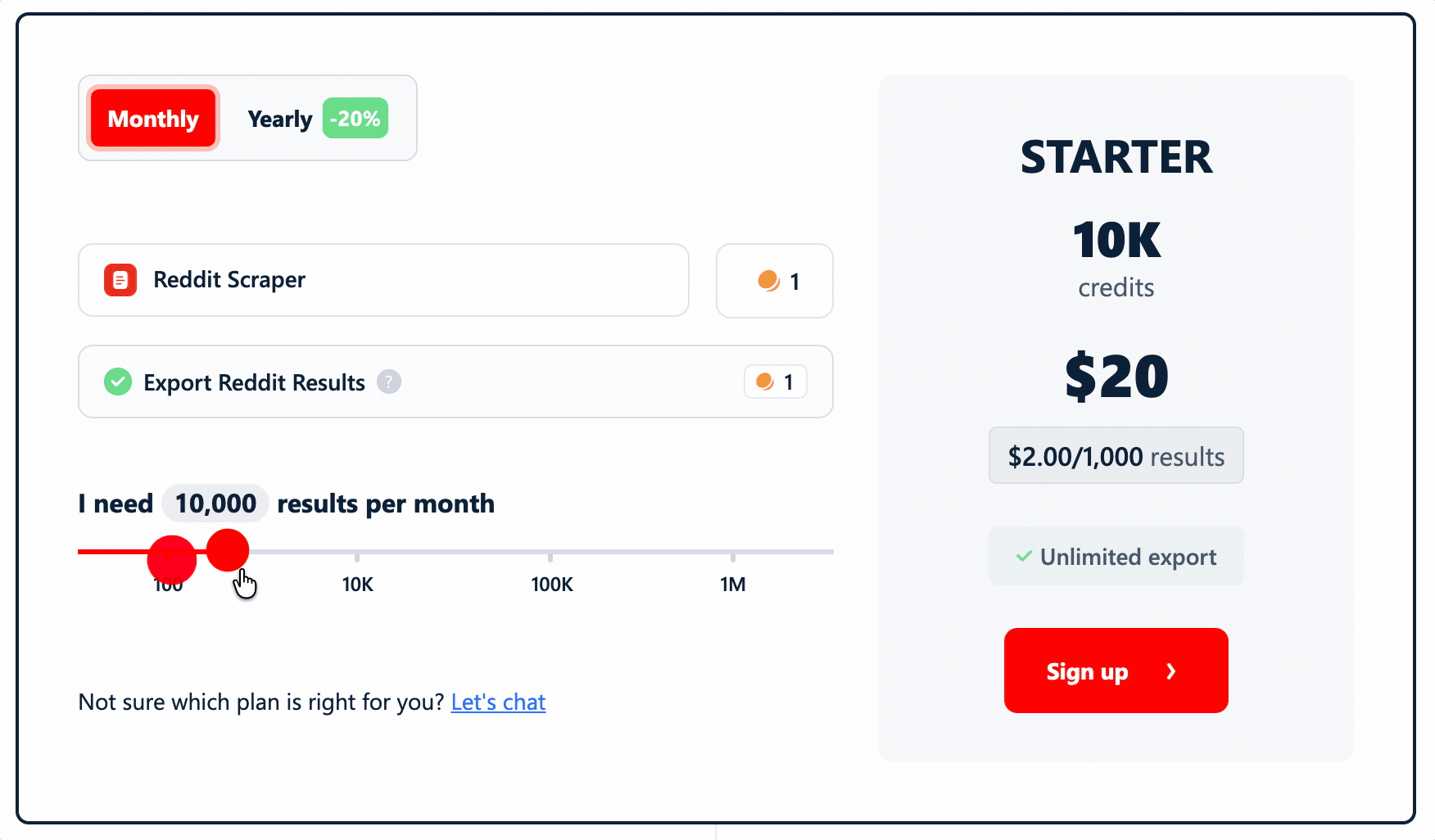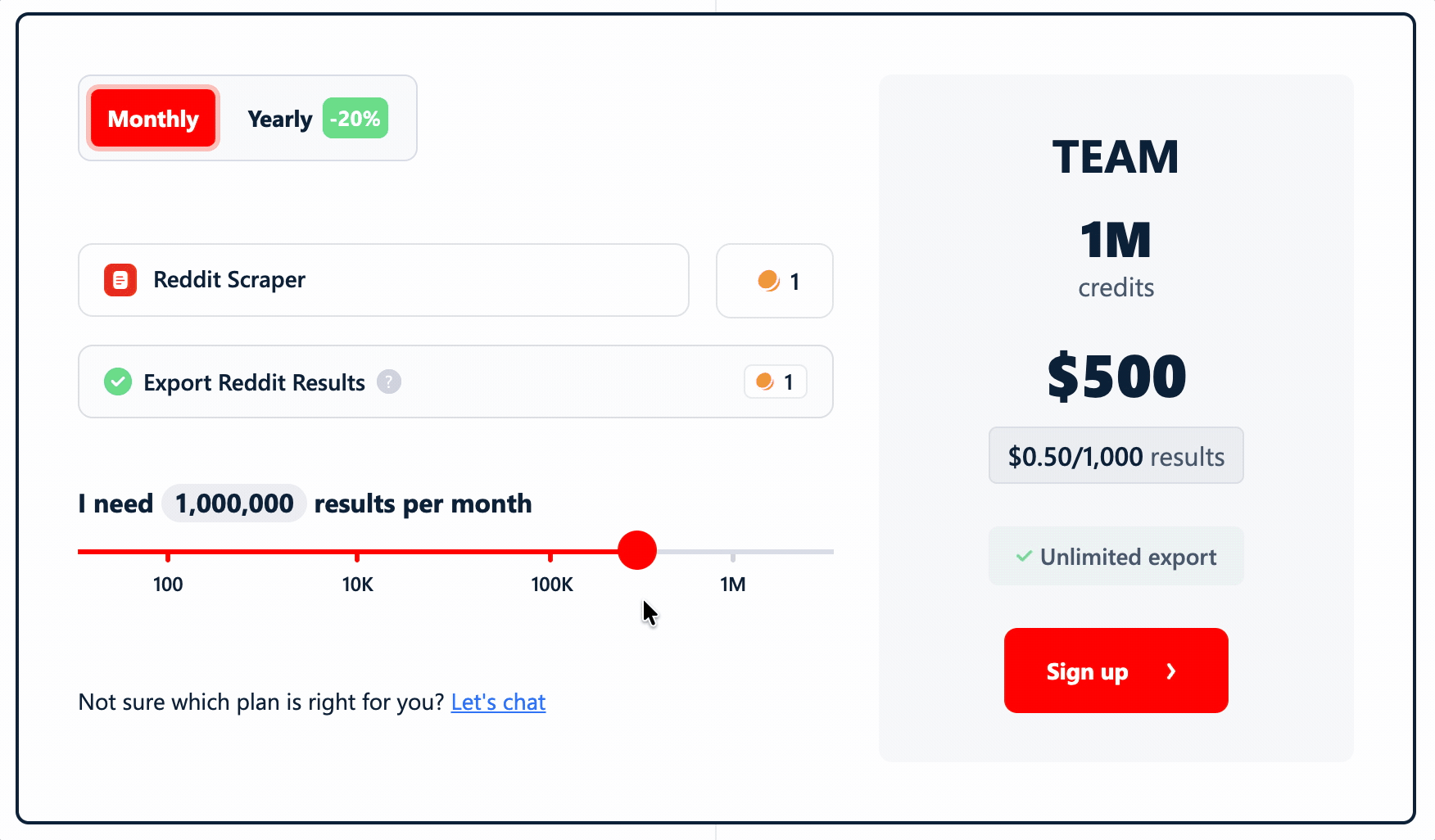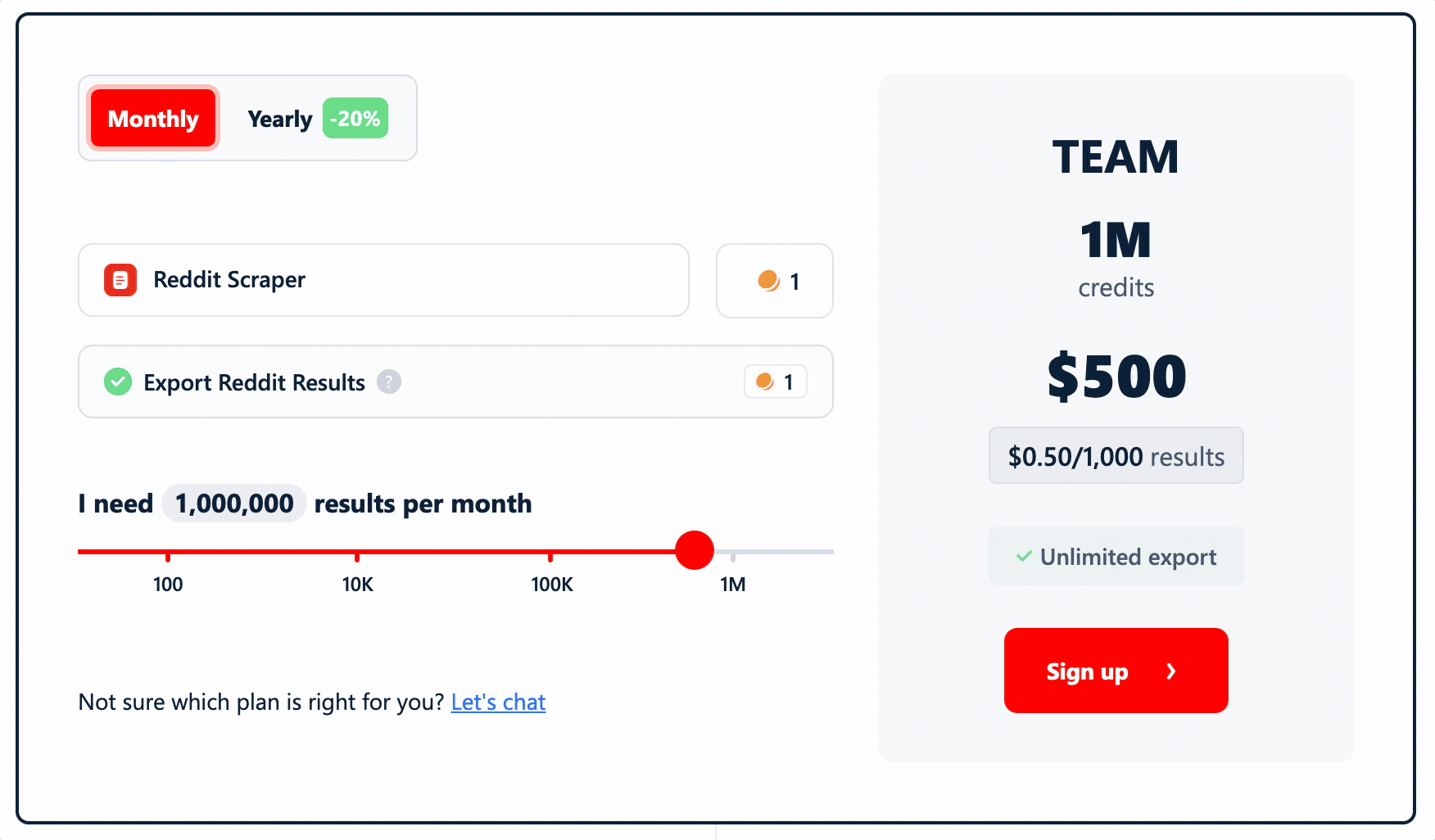
lobstr.io uses a credit-based subscription. Each result — post or comment — costs 1 credit. No multipliers.
- FREE plan: 100 credits/month
- STARTER plan: $2.00 per 1,000 results
- TEAM plan: $0.50 per 1,000 results
Usability
lobstr.io keeps the setup simple. The workflow follows four steps: create a Squid, add tasks, adjust the settings, and launch the run.
Ways to feed it a job
- A direct Reddit post URL
- A subreddit URL
- A Reddit search URL
- A CSV or TXT file for bulk runs
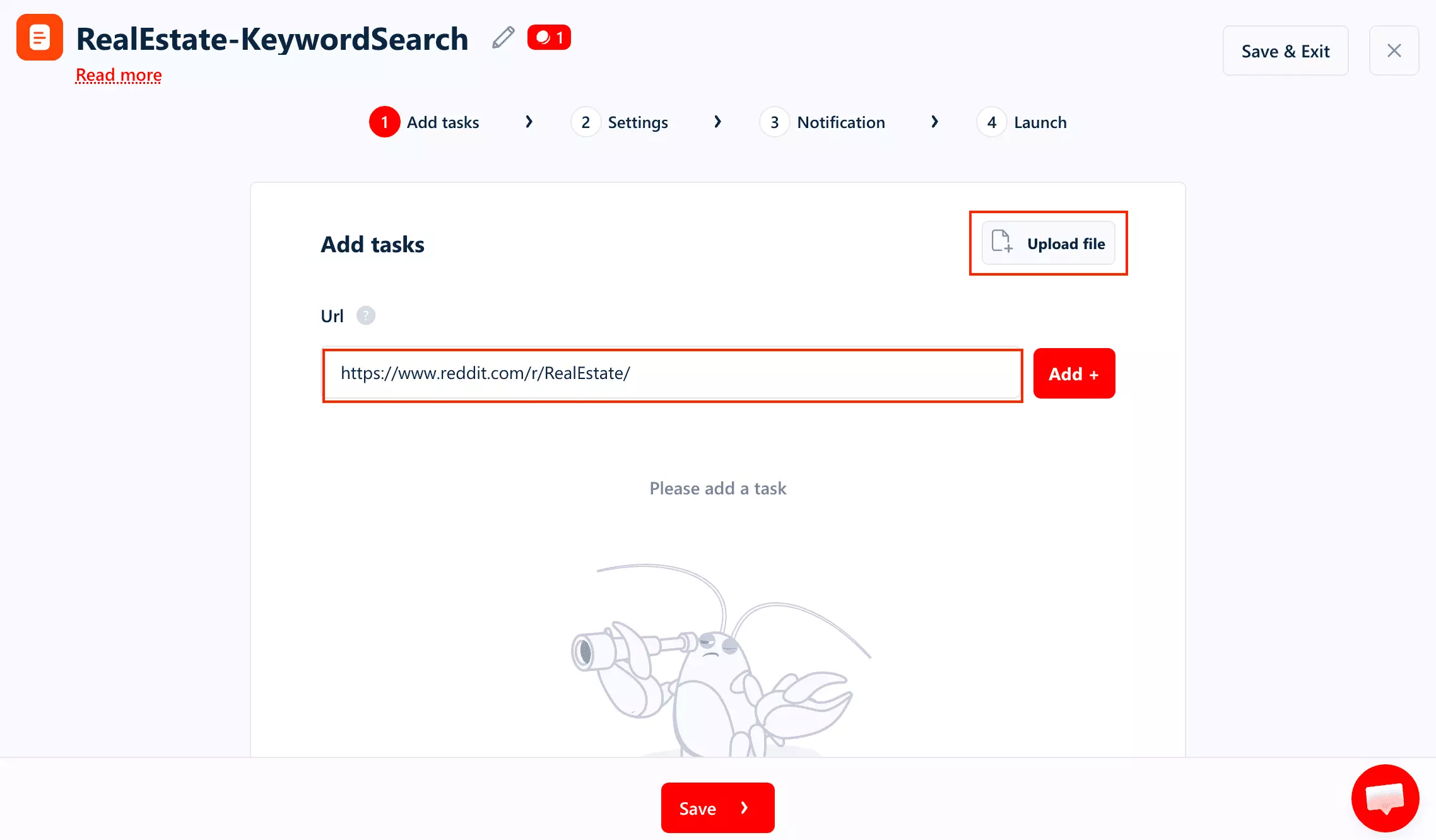
Keyword targeting is supported, but there is one catch: you cannot enter a keyword by itself. You need to provide a Reddit search URL — either across the whole site or within a specific subreddit.
- Global search:
https://www.reddit.com/search/?q=mortgage%20rates - Subreddit search:
https://www.reddit.com/r/RealEstate/search/?q=mortgage%20rates
It works fine once the URL is prepared. It is just one extra step that competing tools may handle for you.
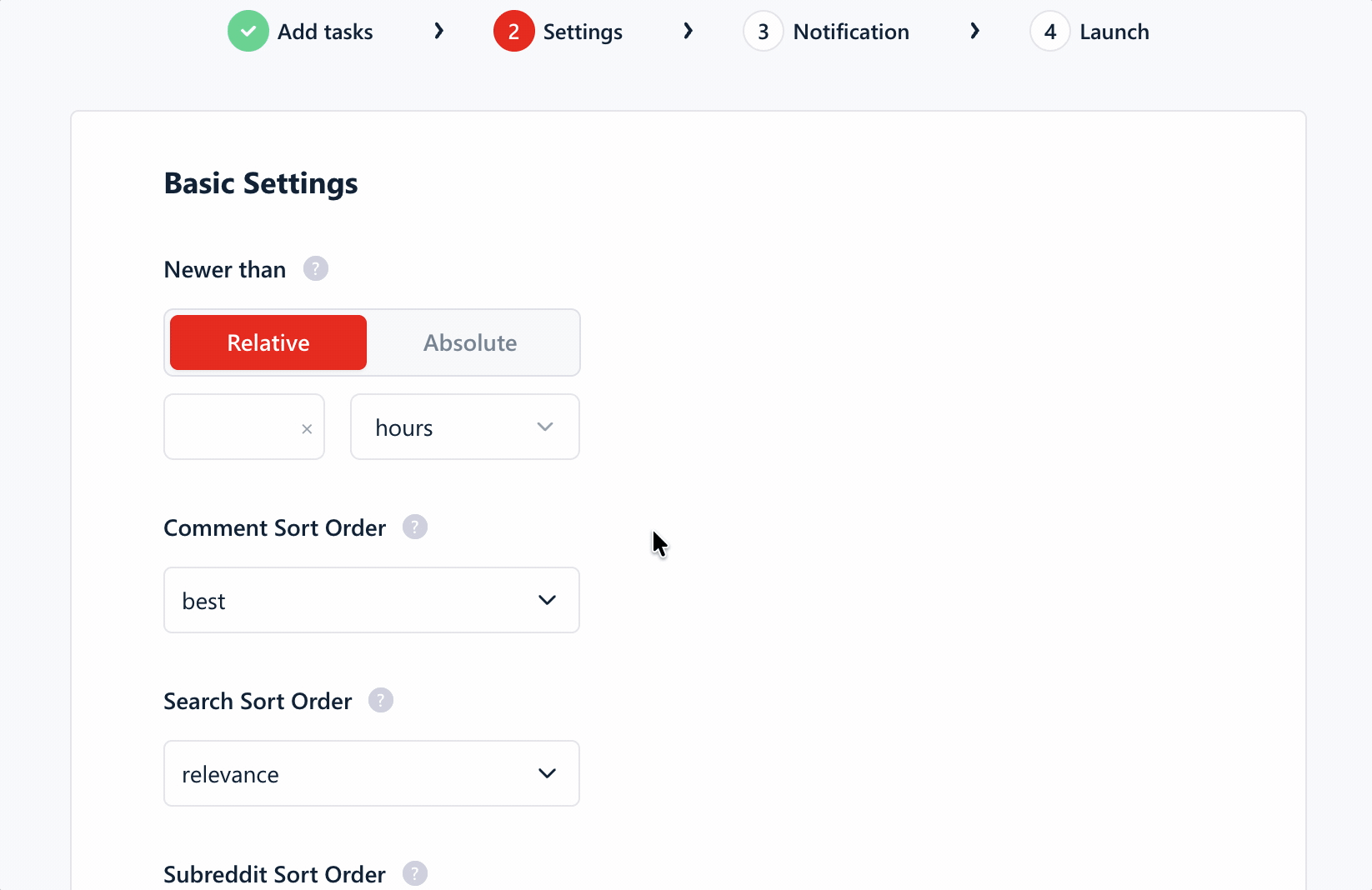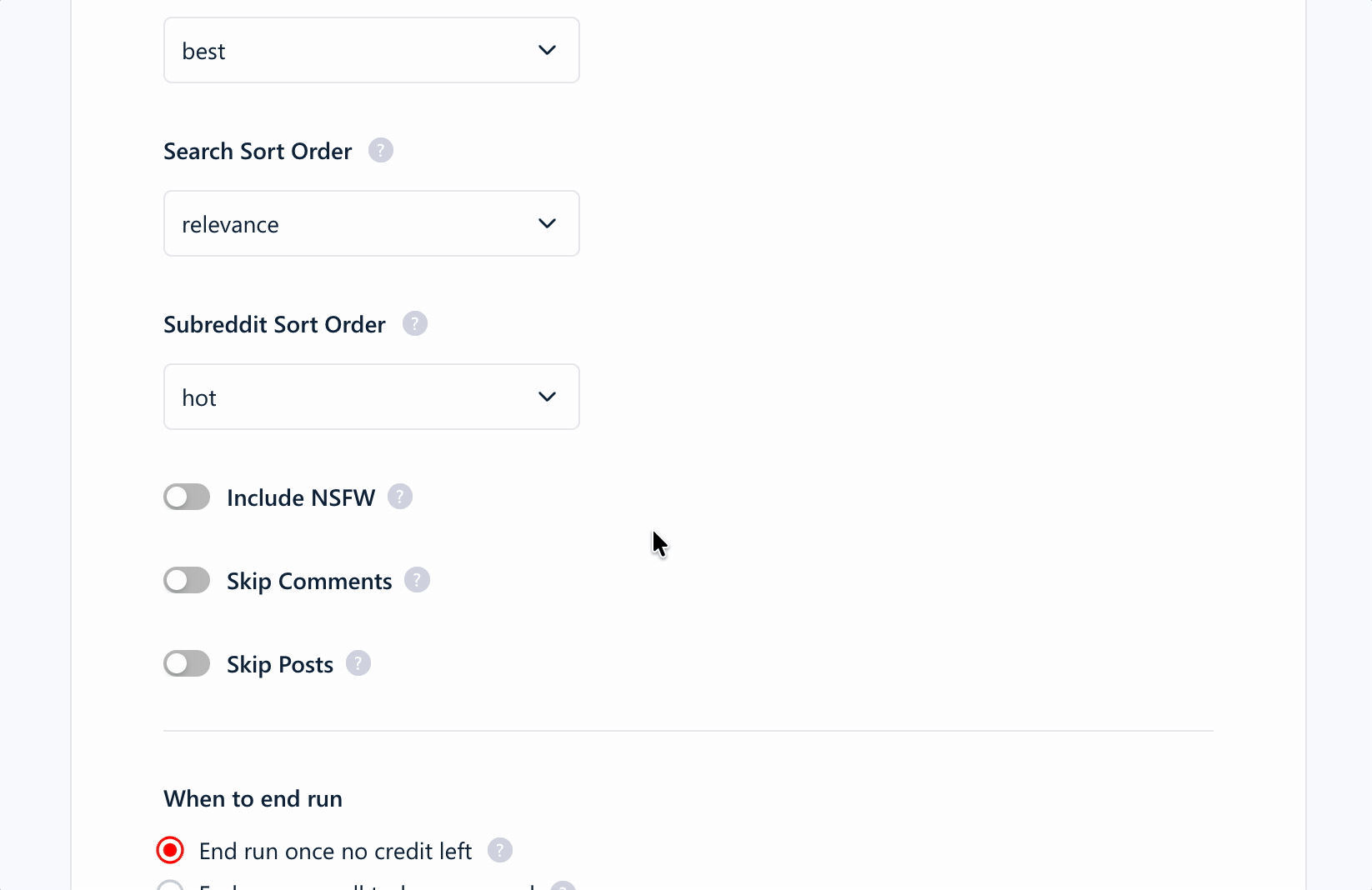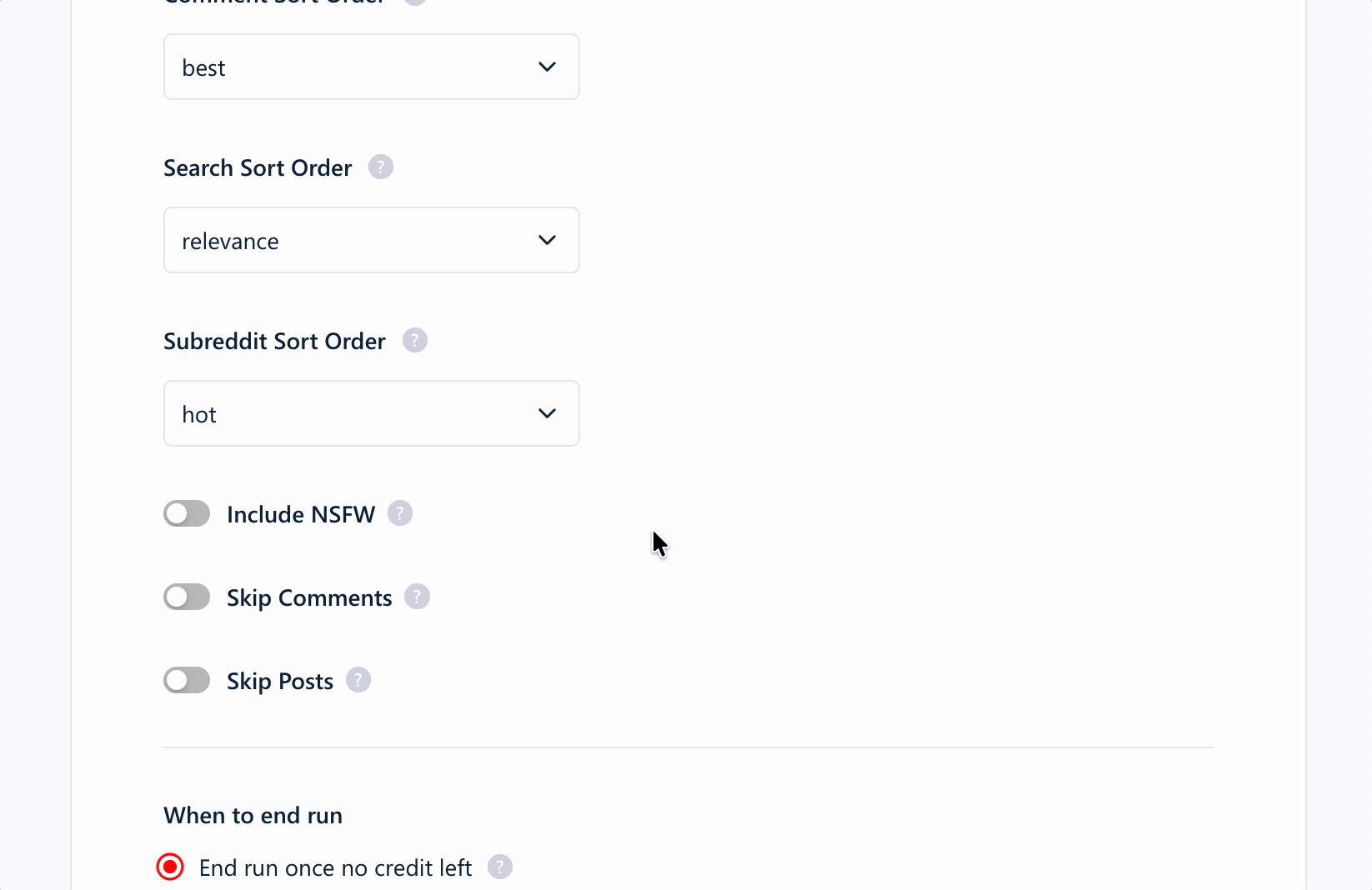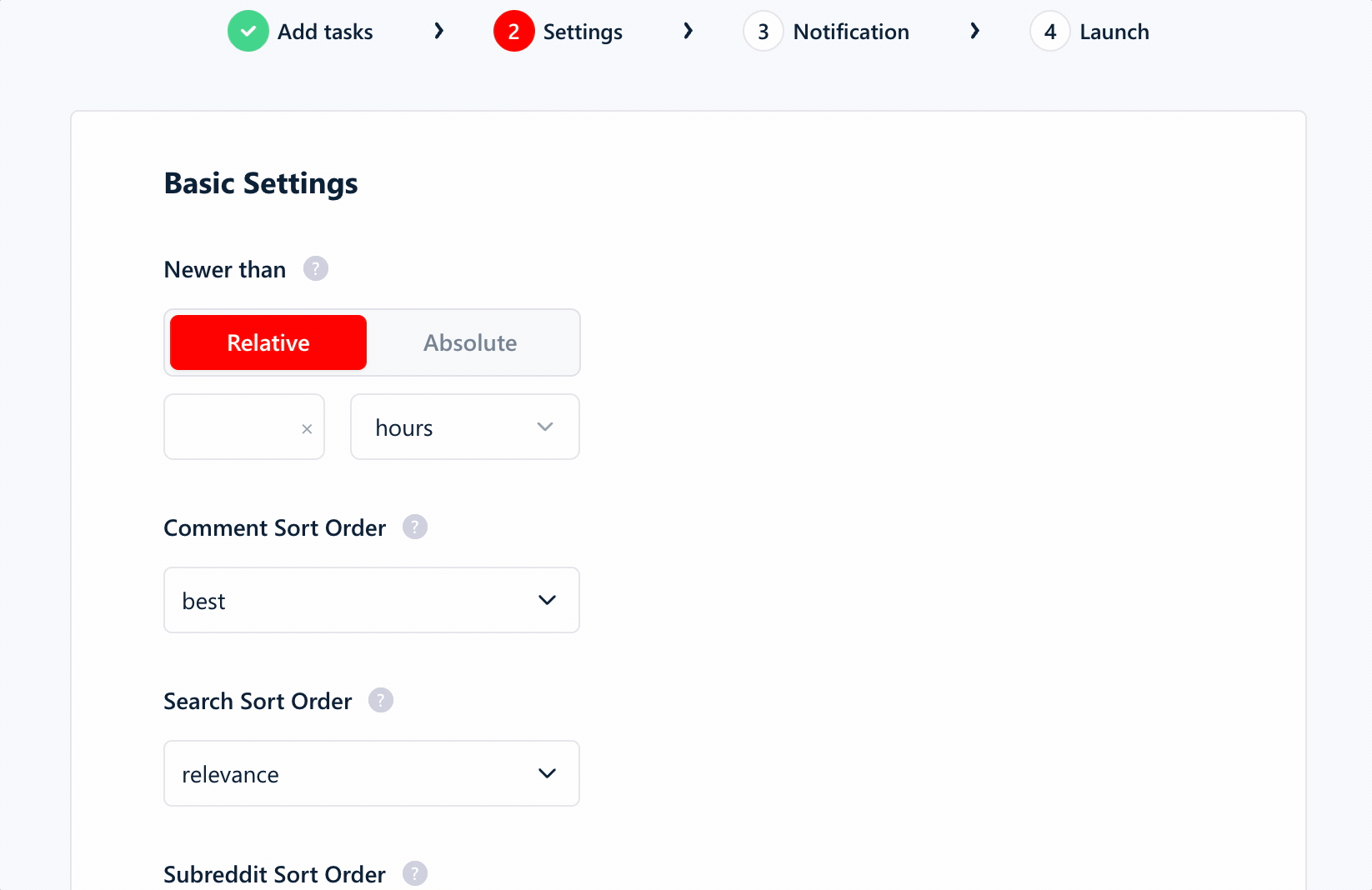
Pre-scrape settings
The settings cover the useful controls without becoming overwhelming:
- Relative or absolute date filters
- Reddit sort order
- Posts, comments, or both
- Maximum result count
- Number of processing slots
- Unique results only
- Removal of line breaks
Deduplication is built into the workflow, which saves you from cleaning repeated records after export. Monitoring is also available for recurring subreddit or keyword tracking.
Standout features
- Named Squid instances — runs are persistent and reusable, not fire-and-forget
- Live streaming progress tracker — results appear incrementally, not after a full wait
- Daily credit cap with auto-pause — no overage, no half-finished exports
- Abort anytime during a run
- Webhook + email alerts on run completion
- Built-in scheduling — daily, weekly, or specific days
- Export to CSV, JSON, Excel, Google Sheets, S3, SFTP, or email delivery
- API + Python SDK + CLI + MCP server
- llms.txt at docs — a machine-readable index so an AI agent can fetch one URL and know exactly what lobstr.io supports
Keep in mind
- Keyword search requires a full Reddit search URL, not a plain keyword
Scalability
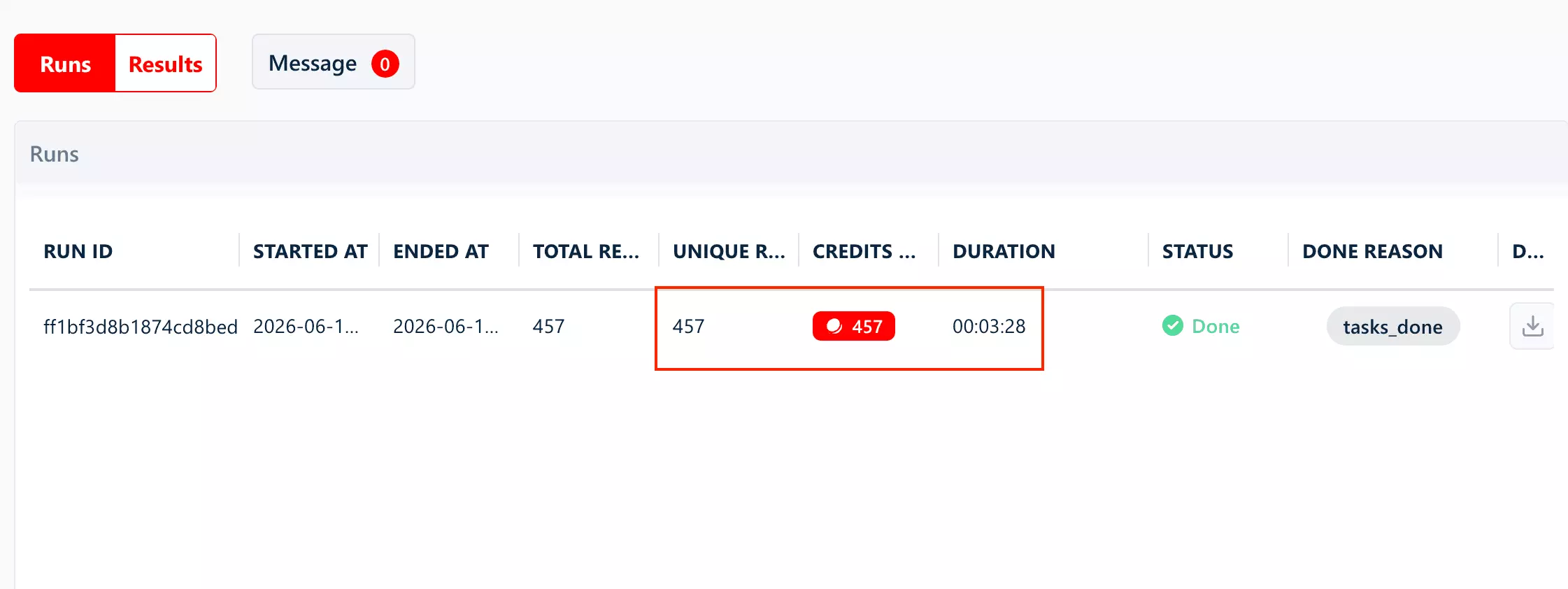
At 125 rows/min, running 24/7 that's ~5.4M rows/month. You can scale further with concurrent Squids.
Speed
457 rows across 20 threads in 218.8 seconds — 8 min per 1,000 results.
Best for: when you want recurring Reddit monitoring without building the workflow yourself. It includes scheduling, deduplication, alerts, reusable jobs, and flexible exports, but trades away comment depth and speed.
2. Apify
That variety is useful, but it also means quality varies. Some actors are polished; others feel like weekend projects with a logo.
For this comparison, I picked the Reddit scraper with pay-per-event pricing and the most active monthly users.
It's not a perfect quality signal, but it's a decent sanity check: people are using it, and pricing is tied to actual output.
Overall score: 4.3/5
| Category | Score |
|---|---|
| Data | 5/5 |
| Usability | 3.5/5 |
| Speed | 5/5 |
| Cost | 4/5 |
| Scalability | 4/5 |
| Pros | Cons |
|---|---|
| Most data fields — 68 per post, 39 per comment | No concurrency |
| Comment depth 9 levels — deepest in this test | No deduplication for mixed input runs |
| Pre-computed engagement metrics: commentToScoreRatio, scorePerHour, isHighEngagement | |
| Fastest thread scrape — 0.13 min per 1,000 results (8 sec) | |
| Dedicated keyword search mode | |
| Highest comment capture rate — 95.5% across 20 threads |
Data
Richness
68 post fields, 39 comment fields, and 23 user profile fields — widest schema in this test.
Post fields (68)
| Category | Fields |
|---|---|
| Content | title, body, bodyHtml, bodyLength, wordCount, postType, isSelf, domain, contentUrl, urlOverriddenByDest, outboundUrlHost |
| Author | authorName, authorId, authorPremium, authorFlairText, parsedAuthorId |
| Community | communityName, communityId, parsedCommunityId, parsedCommunityName, subredditSubscribers |
| Engagement | score, upVotes, upvoteRatio, commentsCount, totalAwardsReceived, gilded, numCrossposts, numDuplicates, engagementTotal |
| Computed | scorePerHour, commentsPerHour, commentToScoreRatio, isHighEngagement, ageHours |
| Media | hasMedia, isVideo, isGallery, galleryCount, galleryImages, galleryData, mediaType, mediaAssets, mediaMetadata, thumbnail, videoUrl, secureMedia, media |
| Flags | archived, hidden, locked, stickied, pinned, spoiler, over18, distinguished, isOriginalContent, edited, editedAt, scoreHidden |
| Meta | id, parsedId, postUrl, flair, createdAt, crawledAt, dataType |
Comment fields (39)
| Category | Fields |
|---|---|
| Content | body, bodyHtml, bodyLength, wordCount |
| Author | authorName, authorId, authorPremium, authorFlairText, authorFullname, parsedAuthorId |
| Position | depth, parentId, parentKind, parsedParentId, postId, parsedPostId, subredditId, parsedSubredditId, subredditName, isSubmitter |
| Engagement | score, commentUpVotes, totalAwardsReceived, gilded, controversiality, scorePerHour |
| Flags | stickied, distinguished, collapsed, collapsedReason, edited, editedAt, scoreHidden |
| Meta | id, url, commentCreatedAt, crawledAt, dataType |
User profile fields (23)
Apify's user profile run returned 21 items total: 1 profile card + 10 posts + 10 comments. The profile card returned all 23 fields.
| Category | Fields |
|---|---|
| Identity | username, id, parsedId, profileUrl |
| Karma | totalKarma, linkKarma, commentKarma, awardeeKarma, awarderKarma |
| Status | isGold, isMod, isEmployee, verified, hasVerifiedEmail |
| Social | acceptFollowers, followersCount, bio |
| Media | bannerImg, iconImg, snoovatarImg |
| Meta | createdAt, crawledAt, dataType |
Exclusive
Additional user profile fields: karma split, follower count, bio, verification, account age.
Depth
Coverage
995 of 1,042 reported comments captured — 95.5%. ScraperAPI was second at 84.2%, but with flat output and no thread structure.
Cost
Apify runs on a monthly subscription. Within each plan, charges are calculated per row returned plus a fixed actor start cost per run.
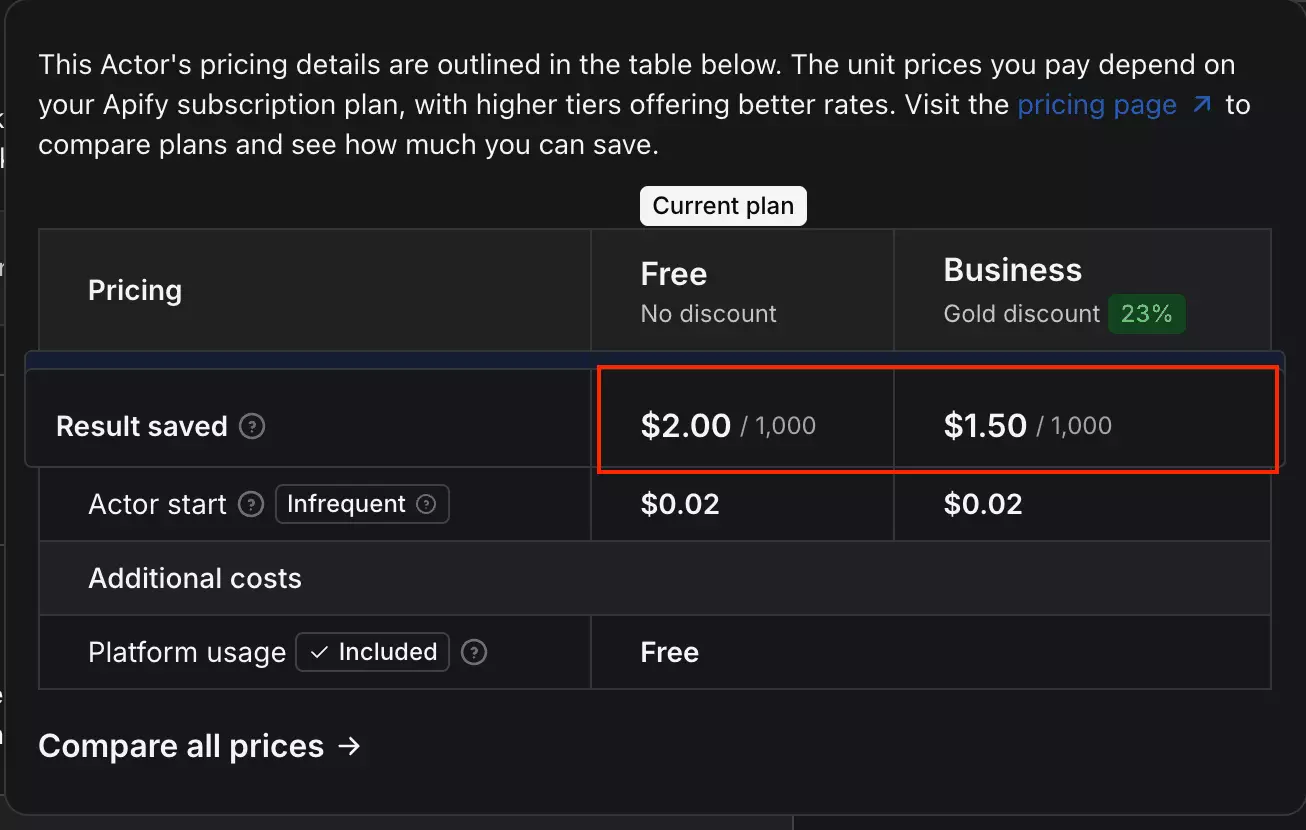
- Actor start: $0.02 per run (all plans)
- FREE tier: available
- Starter: $2.00 per 1,000 results
- Business: $1.50 per 1,000 results
Usability
Apify's Reddit scraper gives you plenty of control, and everything sits on one configuration page.
Ways to feed it a job
- Search keywords
- Direct Reddit URLs
- One or more subreddit names
- Bulk input through the editor or a text file
- A mix of keyword and URL inputs in the same run
Keyword search is the most flexible option — you can search posts, comments, or communities, then narrow the run to a specific subreddit. Direct URLs are handled separately; you can paste individual Reddit pages, bulk-edit the list, or upload a text file.
There is also a dedicated full-subreddit mode for pulling a larger set of posts than you would normally get by passing a subreddit page through the direct URL field.
Search and result controls
- Whether to scrape posts, comments, or communities
- A subreddit filter for keyword searches
- Search-result sorting and time range
- Whether to collect comments from each post
- Whether to include NSFW content
- Maximum posts, search comments, comments per post, and communities
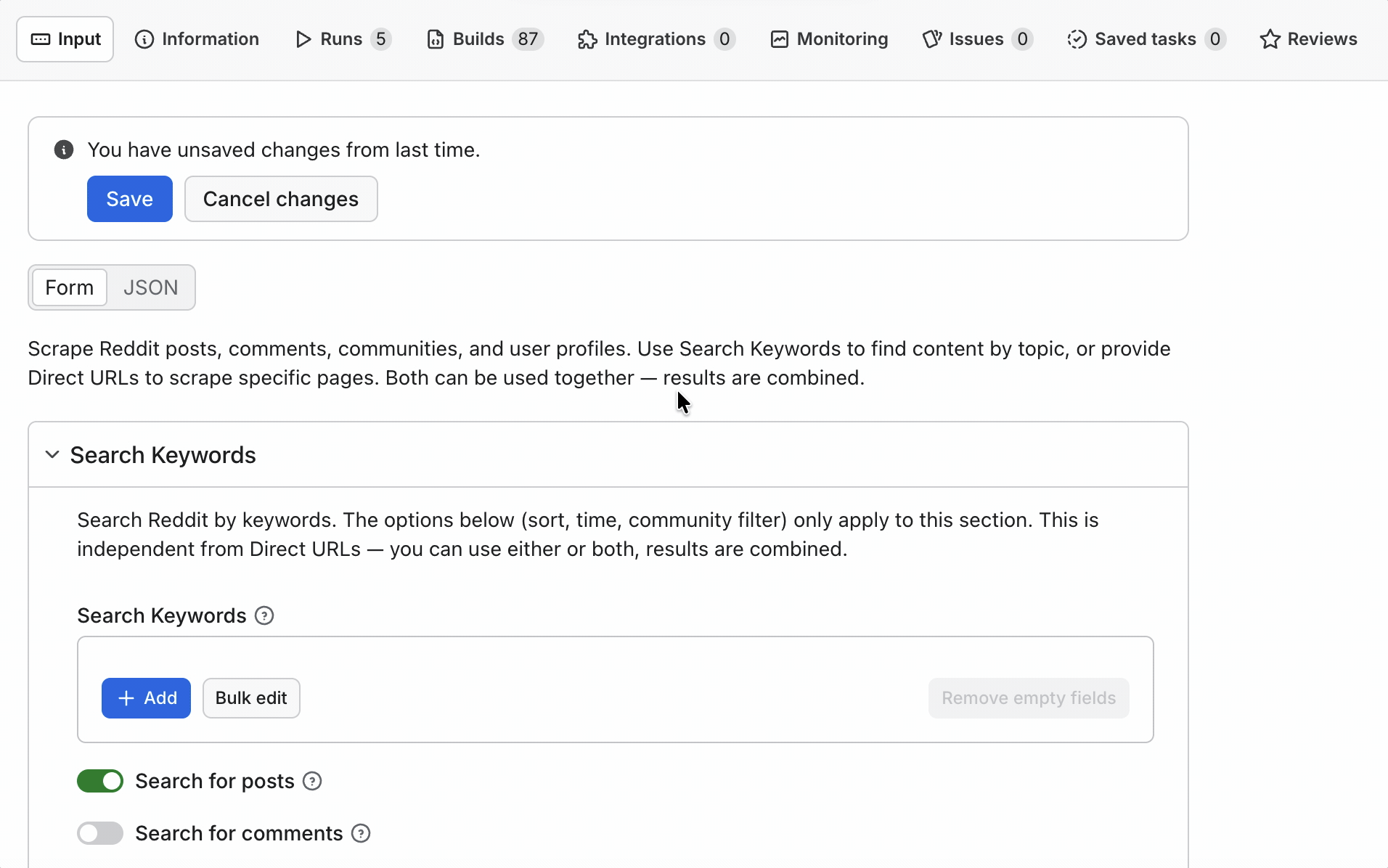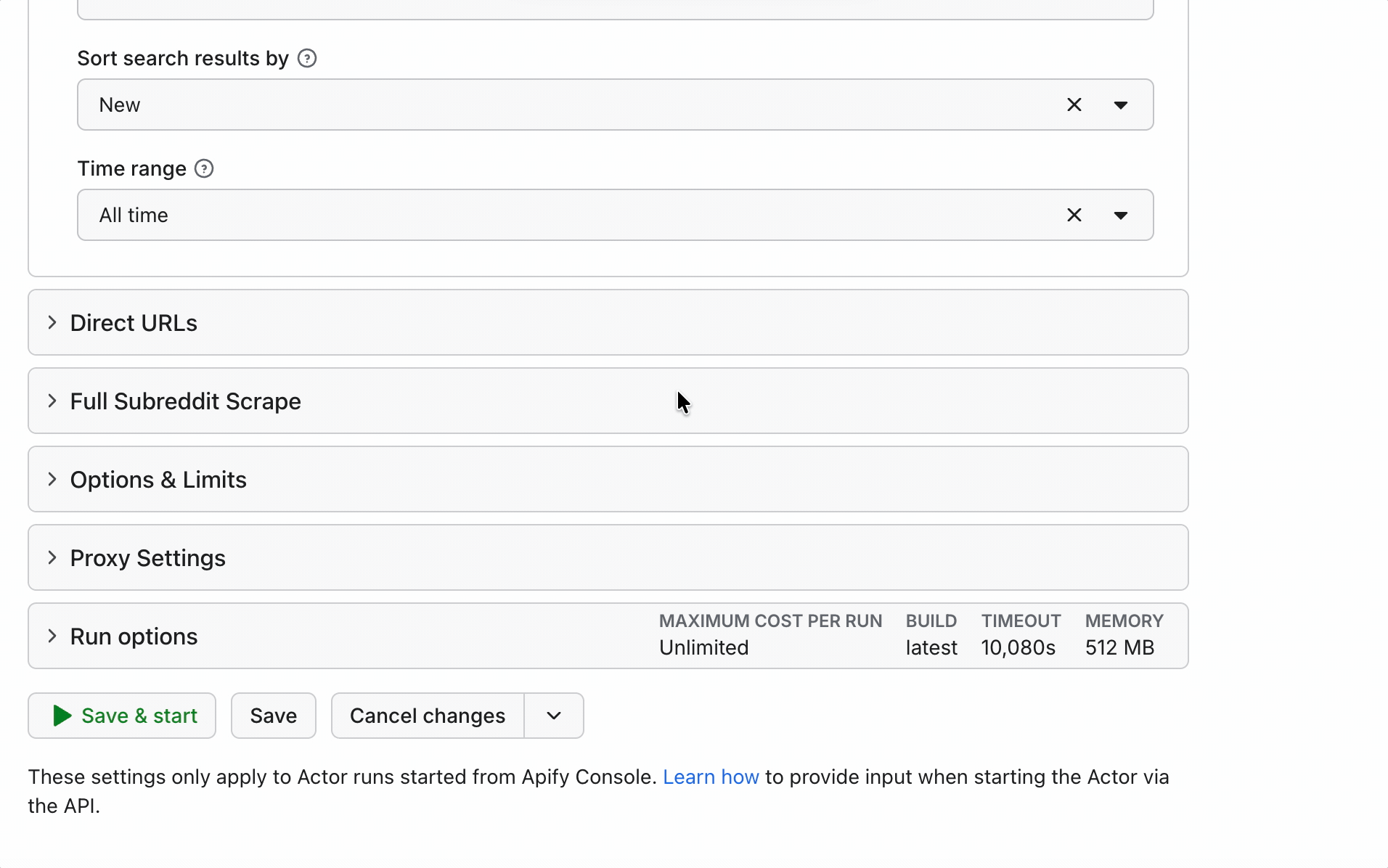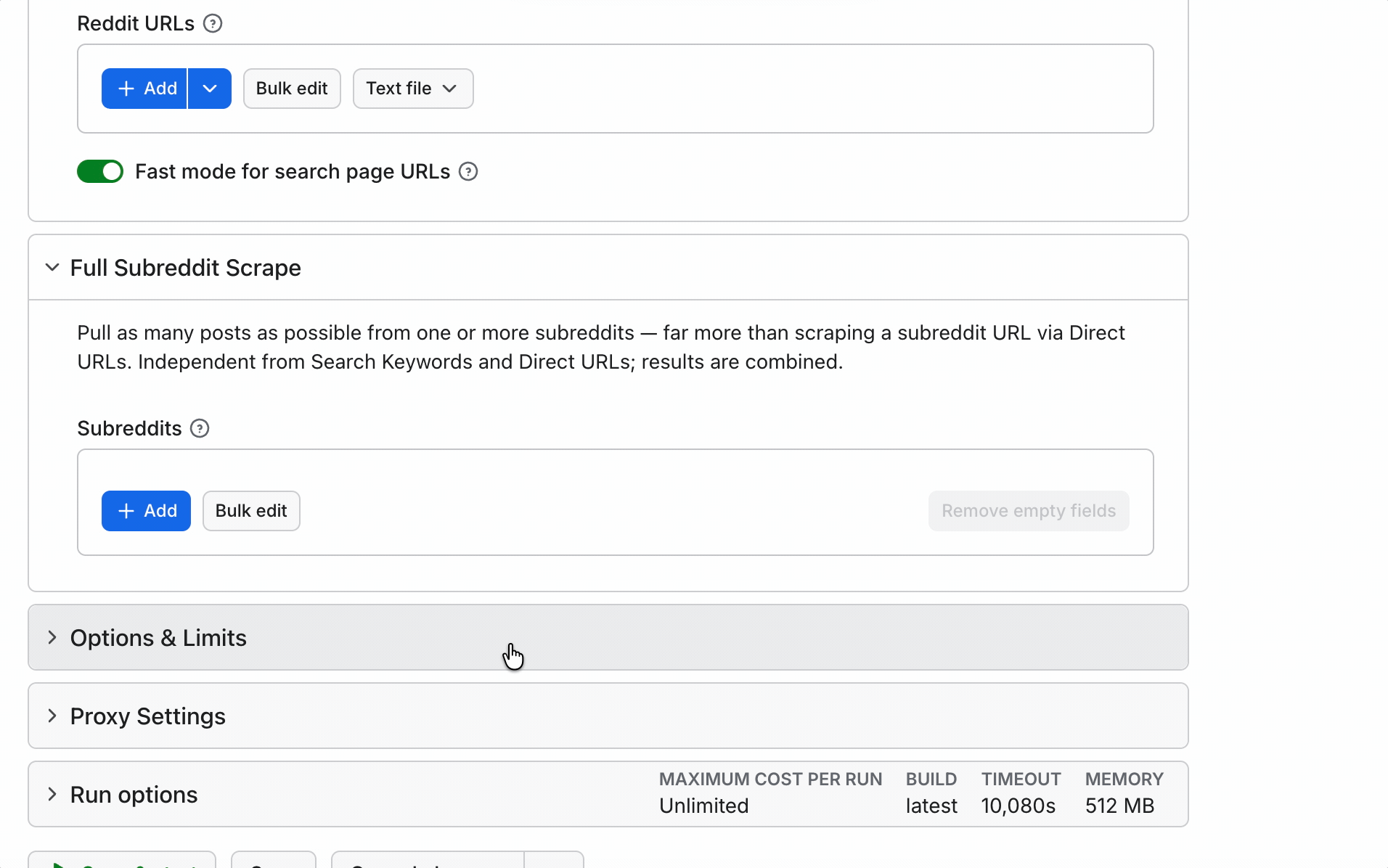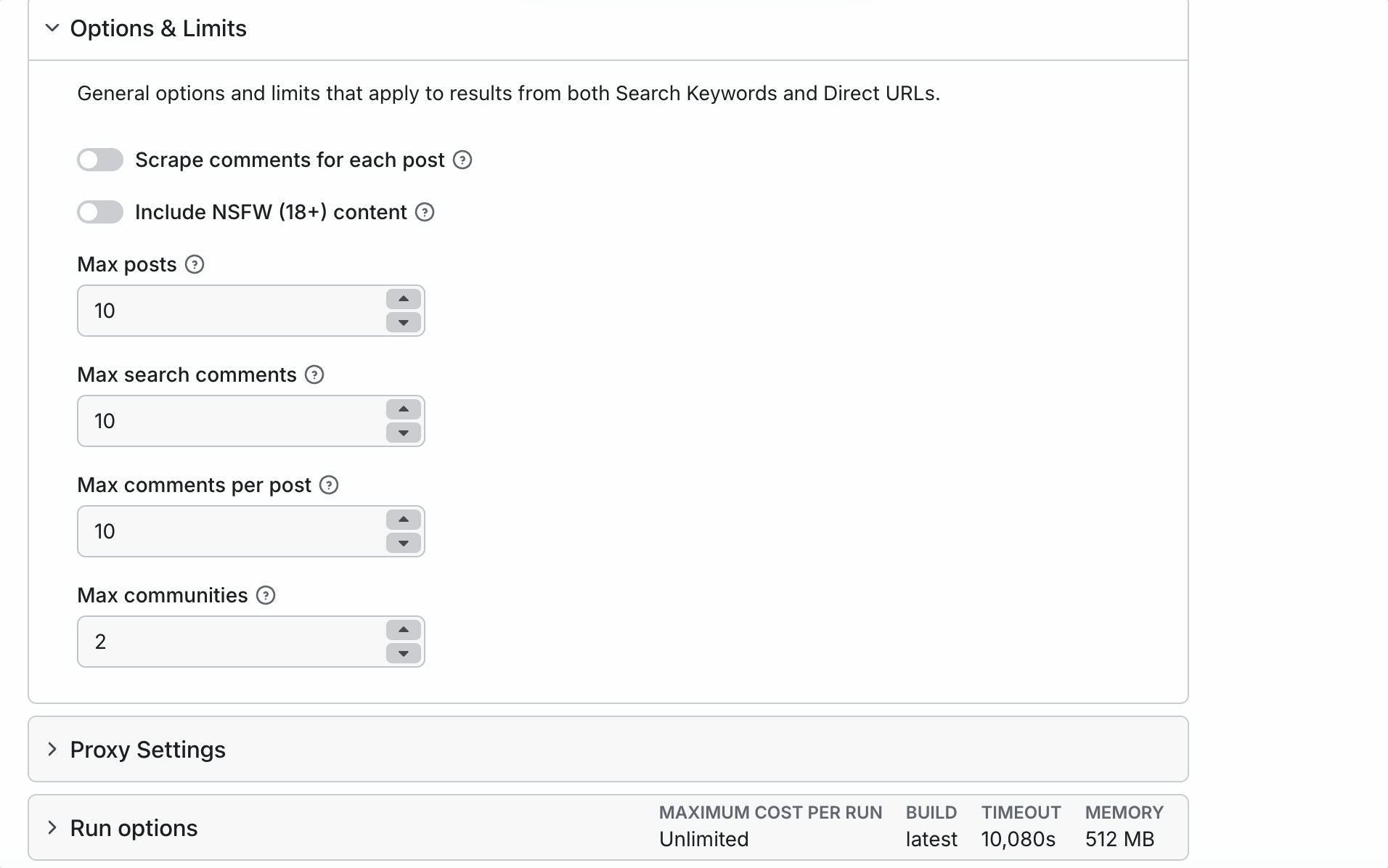
Standout features
- Fast mode for search URLs — speeds up collection when full coverage isn't required
- Dedicated easy keyword search mode
- Export to CSV, JSON, Excel, XML, RSS, Google Sheets, S3
- Webhooks + scheduling built in
- Python + JavaScript SDKs — both include automatic rate-limit backoff handling
- MCP server — callable directly from Claude, Cursor, and compatible agents
- llms.txt + OpenAPI spec — docs are structured for LLM consumption, same as lobstr.io
- Open source actor — code is forkable and inspectable on Apify's platform
Keep in mind
- Mixed input types (keywords + URLs in one run) produce duplicates — no built-in deduplication
- Fast mode may miss some posts
- Community-maintained actor — schema can change between versions without notice
Scalability
At 7,613 rows/min, running 24/7 that's ~329M rows/month.
Speed
1,015 rows — 20 posts and 995 comments — in 8 seconds. That's 0.13 min per 1,000 results (8 sec) — the fastest thread scrape in this test by a wide margin.
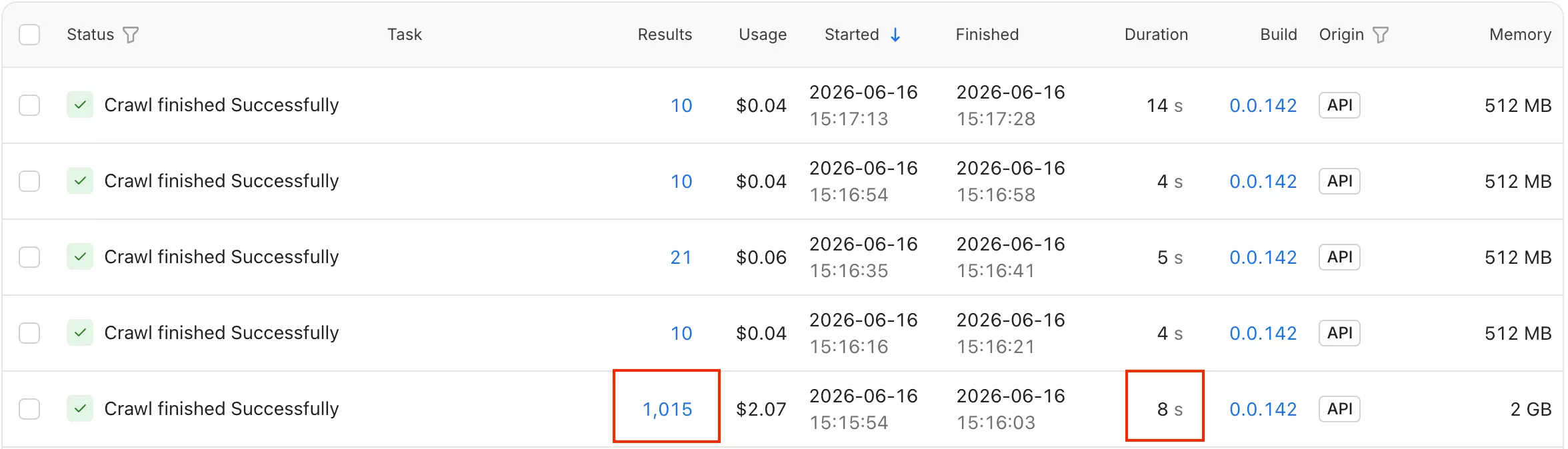
Best for: when data completeness is the priority. It captured the most comments, preserved the deepest reply trees, and returned the richest post schema.
3. ScraperAPI
Overall score: 3.5/5
| Category | Score |
|---|---|
| Data | 2/5 |
| Usability | 4.5/5 |
| Speed | 3/5 |
| Cost | 5/5 |
| Scalability | 3/5 |
| Pros | Cons |
|---|---|
| Competitive comment capture rate — 84.2% across 20 threads | Smallest schema — 9 fields per post, 4 per comment |
| Multiple integration options (MCP, LangChain, n8n, DataPipeline) | Flat output — no depth, no parent IDs on comments |
| Standard reddit.com URLs cost 20x more than old.reddit.com | |
| No concurrency |
Data
Richness
9 post fields and 4 comment fields — smallest schema in this test.
Post fields (9)
Comment fields (4)
User profile
Exclusive
No exclusive fields. The parser extracts only what's visible in old.reddit.com's page source.
Depth
Coverage
877 of 1,042 reported comments captured — 84.2%. Second only to Apify.
Cost
ScraperAPI uses a credit-based model.
- Entry: $0.011 / 1K comments — Hobby ($0.00049 / credit)
- At scale: $0.002 / 1K comments — Business ($0.0000997 / credit)
Usability
ScraperAPI works through a single GET request. Add the Reddit URL, set the parameters you need, and receive the result as JSON.
Ways to feed it a job
- A Reddit post or comment thread
- A subreddit feed
- A Reddit search page
- A user profile
Request controls
- render — enable or disable browser rendering
- autoparse — structured JSON output
- country_code — proxy location
- premium — premium proxy pool
Standout features
- Async endpoint for non-blocking bulk jobs
- DataPipeline for scheduled runs
- MCP server for prompt-based scraping
- LangChain integration for AI agents
- n8n community node for no-code workflows
- Clear, compact documentation
Keep in mind
- Comment IDs are returned as null — no comment-level identification possible
- There is no batch endpoint for Reddit threads
- Each thread URL requires a separate request
- old.reddit.com is needed to stay at one credit per request; reddit.com can cost 5–25 times more
Scalability
At 225 rows/min, running 24/7 that's ~9.7M rows/month. You can scale further with concurrent requests.
Speed
897 rows across 20 threads in 239.5 seconds — 4.5 min per 1,000 results. Time scales linearly with URL count since every thread is a separate serial request.
Best for: when cost matters more than structure. It is the cheapest option tested, but returns a sparse schema and does not preserve comment relationships.
4. Bright Data
Overall score: 2.8/5
| Category | Score |
|---|---|
| Data | 4/5 |
| Usability | 2.5/5 |
| Speed | 2/5 |
| Cost | 2.5/5 |
| Scalability | 3/5 |
| Pros | Cons |
|---|---|
| Richest comment schema — 35 fields per comment | Comment depth 2 levels |
| Exports to JSON, NDJSON, CSV, XLSX, and Parquet | Bills for every row it discovers, not just the rows it delivers |
| Delivery to S3, Google Cloud, Azure, Snowflake, SFTP, email, webhook, and Pub/Sub | |
| Concurrency available |
Data
Richness
35 comment fields — richest comment schema in this test. Post dataset returns 29 fields.
Comment fields (35)
| Category | Fields |
|---|---|
| Content | comment, images, videos |
| Author | user_posted, user_id |
| Position | parent_comment_id, root_comment_id, post_id, post_url |
| Engagement | num_upvotes, replies |
| Moderation (10) | is_admin_post, is_archived_post, is_eligible_for_content_blocking_post, is_locked, is_moderator, is_moderator_post, is_not_safe_for_work_post, is_pinned, is_promoted_post, is_quarantined_post |
| Quality signals | has_bot_in_username, post_language, post_state, post_type |
| Community | community_name, community_description, community_members_num, community_rank, community_url |
| Meta | comment_id, input, date_posted, timestamp, days_back |
Post fields (29 — subreddit/search datasets)
| Category | Fields |
|---|---|
| Content | title, description, description_markdown, embedded_links, photos, videos |
| Author | user_posted, user_id, post_karma, author_icon |
| Community | community_name, community_description, community_members_num, community_rank, community_url, subreddit_icon_image |
| Engagement | num_upvotes, num_comments, comments, related_posts |
| Flags | archived, tag |
| Meta | post_id, url, input, discovery_input, date_posted, timestamp, bio_description |
User profile
Not supported. Returns 1 stub row with null content.
Exclusive
Depth
Coverage
356 of 1,042 reported comments captured — 34.2%.
Cost
Bright Data offers pay-as-you-go and a monthly subscription model.
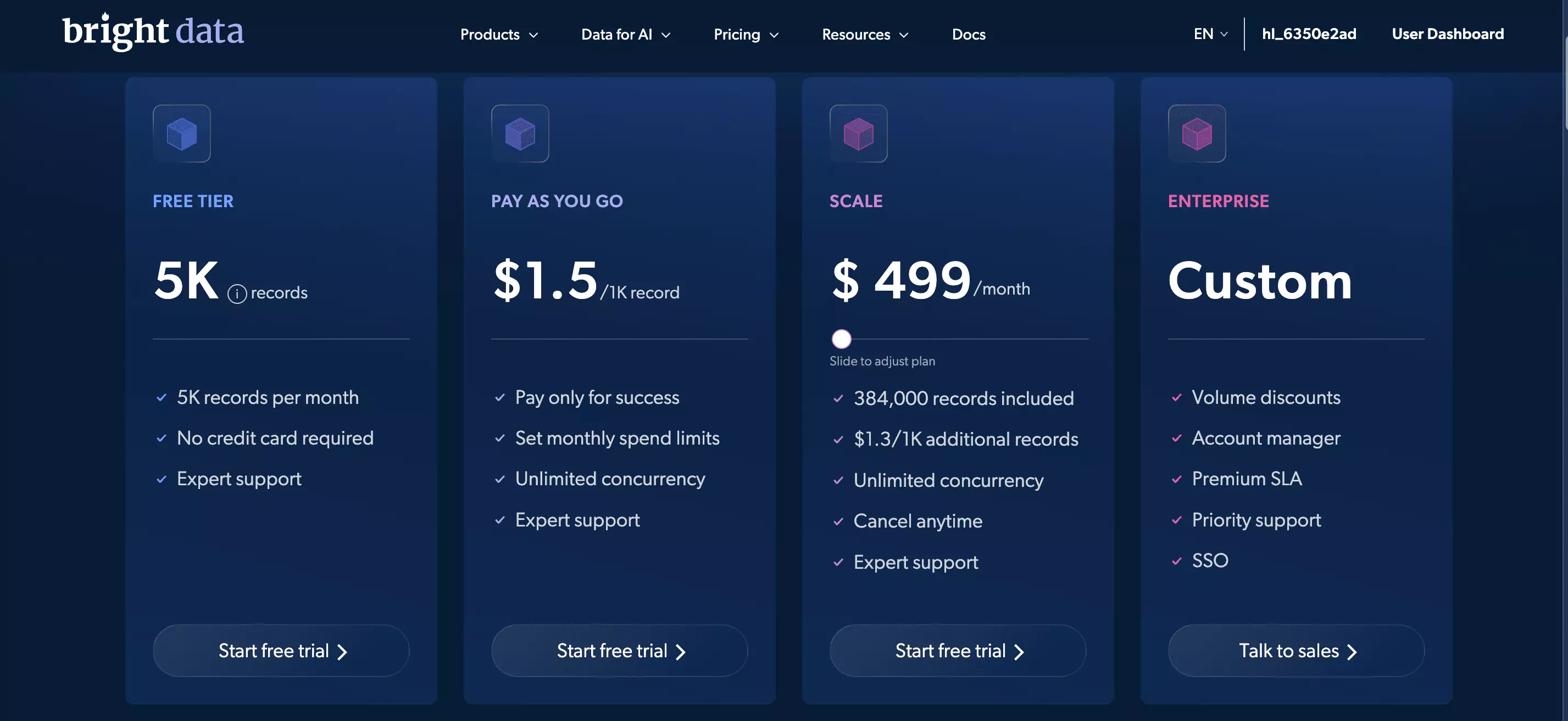
- Free tier: not available
- Pay as you go: $1.50 / 1K records
- Scale plan: $1.30 / 1K records
The catch is that Bright Data bills for every row it discovers, not just the rows it delivers.
In my subreddit test, I capped the output at 30 rows. Bright Data found 982 rows before trimming the dataset, and billed all 982.
That made the 30-row job cost about $1.47 instead of $0.045 — roughly 32 times more than the delivered result suggests.
Usability
Bright Data uses an asynchronous workflow: trigger the job, poll its status, then download the finished dataset.
Ways to feed it a job
- A Reddit post URL for comments
- A subreddit URL for posts
- A keyword for post search
- A user profile URL
User profile scraping is not fully supported — it only returns a stub row.
Request controls
- limit_multiple_results — cap delivered rows
- days_back — set a lookback window
- include_errors — return failed rows
- format — JSON or JSONL responses
Standout features
- Exports to JSON, NDJSON, CSV, XLSX, and Parquet
- Delivery to S3, Google Cloud, Azure, Snowflake, SFTP, email, webhook, and Pub/Sub
- Results are stored as snapshots and can be downloaded again later
- Enterprise-grade infrastructure for large-scale pipelines
- MCP server with 60+ tools — widest AI agent integration of any tool tested, supporting Claude, Cursor, LangChain, LlamaIndex, CrewAI, and n8n
Keep in mind
- Post and comment jobs use different dataset IDs
- It crawls beyond the row limit before trimming the output — in my test, a 30-row job billed 982 rows, roughly 32x the expected cost
Scalability
At 297 rows/min, running 24/7 that's ~12.8M rows/month. You can scale further with concurrent jobs.
Speed
356 comments across 20 thread URLs in 1 minute 12 seconds — 3.4 min per 1,000 results.
Best for: when moderation fields and enterprise delivery options are specific requirements. Its infrastructure is strong, but the billing model and lower comment coverage make it harder to justify for standard Reddit scraping.
5. SociaVault
Overall score: 3.7/5
| Category | Score |
|---|---|
| Data | 3.5/5 |
| Usability | 4/5 |
| Speed | 4.5/5 |
| Cost | 3.5/5 |
| Scalability | 3/5 |
| Pros | Cons |
|---|---|
| Concurrency available | Lowest comment capture rate — 34.1% across 20 threads |
| Simple X-API-Key authentication | Comment depth 2 levels |
| Credits never expire | Failed requests consume a credit |
| Standard REST endpoints | timeframe only works when sort=top |
| User profile scraping not supported | |
| No webhooks | |
| No built-in scheduling | |
| JSON output only |
Data
Richness
26 post fields and 15 comment fields.
Post fields (26)
| Category | Fields |
|---|---|
| Content | title, selftext, selftext_html, url, domain, post_hint, is_video |
| Author | author, author_fullname |
| Community | subreddit, subreddit_id, subreddit_subscribers |
| Engagement | score, ups, downs, upvote_ratio, num_comments, total_awards_received |
| Flags | over_18, spoiler |
| Meta | id, name, permalink, created_utc, created_at_iso, created |
Comment fields (15)
| Category | Fields |
|---|---|
| Content | body |
| Author | author, author_fullname |
| Position | parent_id, replies (nested array, max 2 levels) |
| Engagement | score, ups, downs |
| Flags | collapsed |
| Meta | id, name, permalink, url, created_utc, created_at_iso |
Exclusive
No exclusive fields.
Depth
Coverage
355 of 1,042 reported comments captured — 34.1%.
Cost
SociaVault uses one-time credit packs rather than subscriptions, and unused credits do not expire.
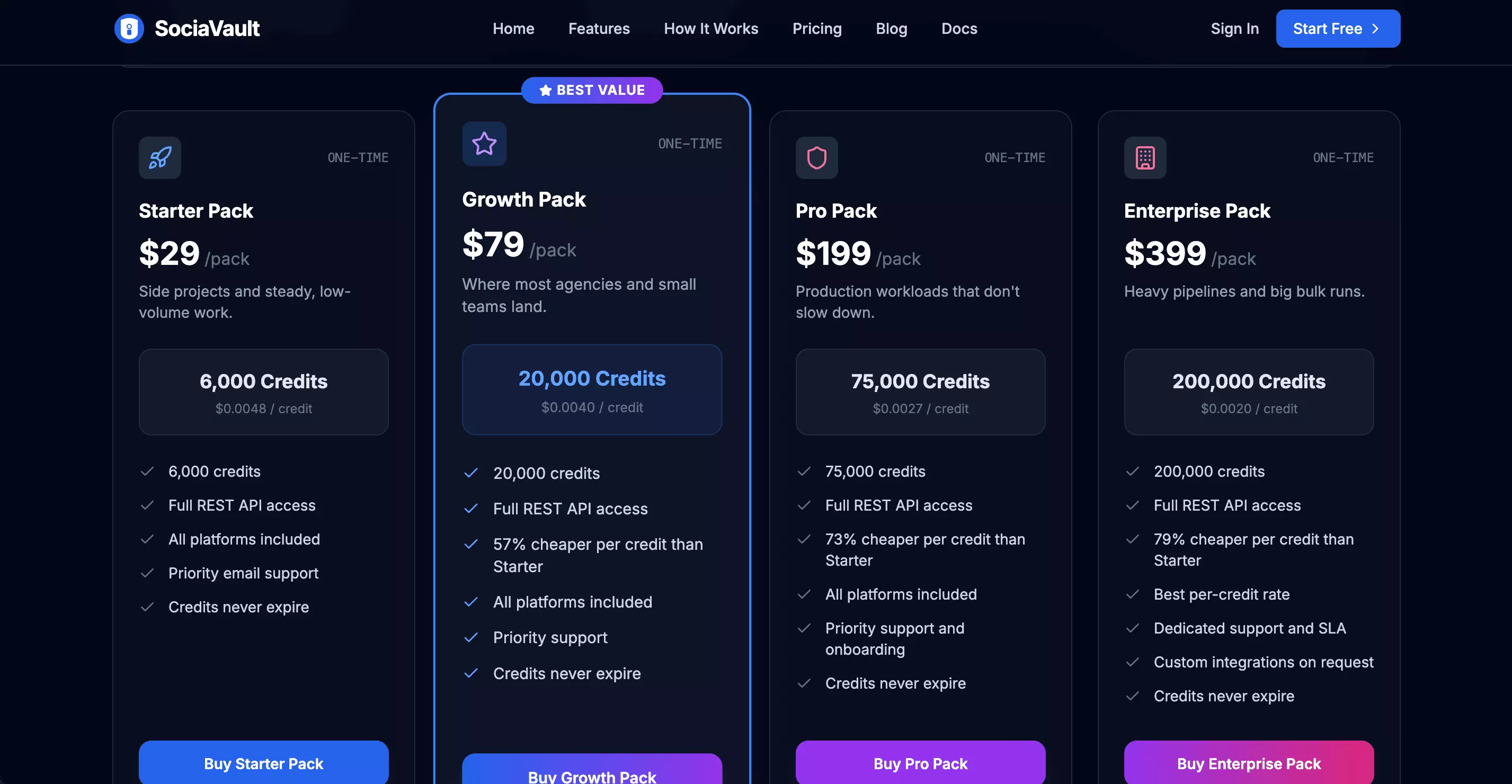
Comment scraping is reasonably efficient. Each request costs one credit and returns up to 16 comments, so collecting 1,000 comments takes about 63 requests.
- Entry: $0.30 / 1K comments ($29 / 6,000 credits)
- At scale: $0.12 / 1K comments ($399 / 200,000 credits)
Search is the pricier route. Each query returns no more than 7 results, with no pagination.
- Entry: $0.69 / 1K results ($29 / 6,000 credits)
- At scale: $0.28 / 1K results ($399 / 200,000 credits)
Failed requests still consume one credit, so errors are billed too.
Usability
Ways to feed it a job
- A subreddit name for feed scraping
- A Reddit post URL for comments
- A keyword for global search
- A subreddit plus keyword for scoped search
Search and result controls
- Sort by new, top, or hot
- Timeframe of week, month, year, or all
- Result limit for subreddit feeds
- Cursor pagination for post comments
Standout features
- One-header authentication with X-API-Key
- Standard REST endpoints that work with any programming language
- Fast subreddit-feed and search responses in our tests
- Predictable JSON output
- The API is simple enough that an LLM can implement it from the reference in one pass
Keep in mind
- User profiles are not supported
- No webhooks or built-in scheduling
- JSON is the only output format
- No CSV, Excel, or direct spreadsheet exports
Scalability
At 195 rows/min, running 24/7 that's ~8.4M rows/month. You can scale further with concurrent requests.
Speed
375 rows across 20 threads in 115.2 seconds — 5.1 min per 1,000 results. Comments are paginated per post, so each thread requires multiple requests.
Best for: when you need a simple API for occasional Reddit jobs without a subscription. Its non-expiring credits are useful for irregular use, though comment coverage, automation, and export options are limited.
The scraper that didn't make the list
SerpApi
The limitation is scope.
It can find Reddit posts by keyword, but it does not scrape full comment threads, subreddit feeds, user profiles, or post body text.
That makes it useful for discovery, but too limited for this comparison.
Outscraper

It offers two separate Reddit tools: a Reddit Comments Scraper and a Reddit Search Scraper.
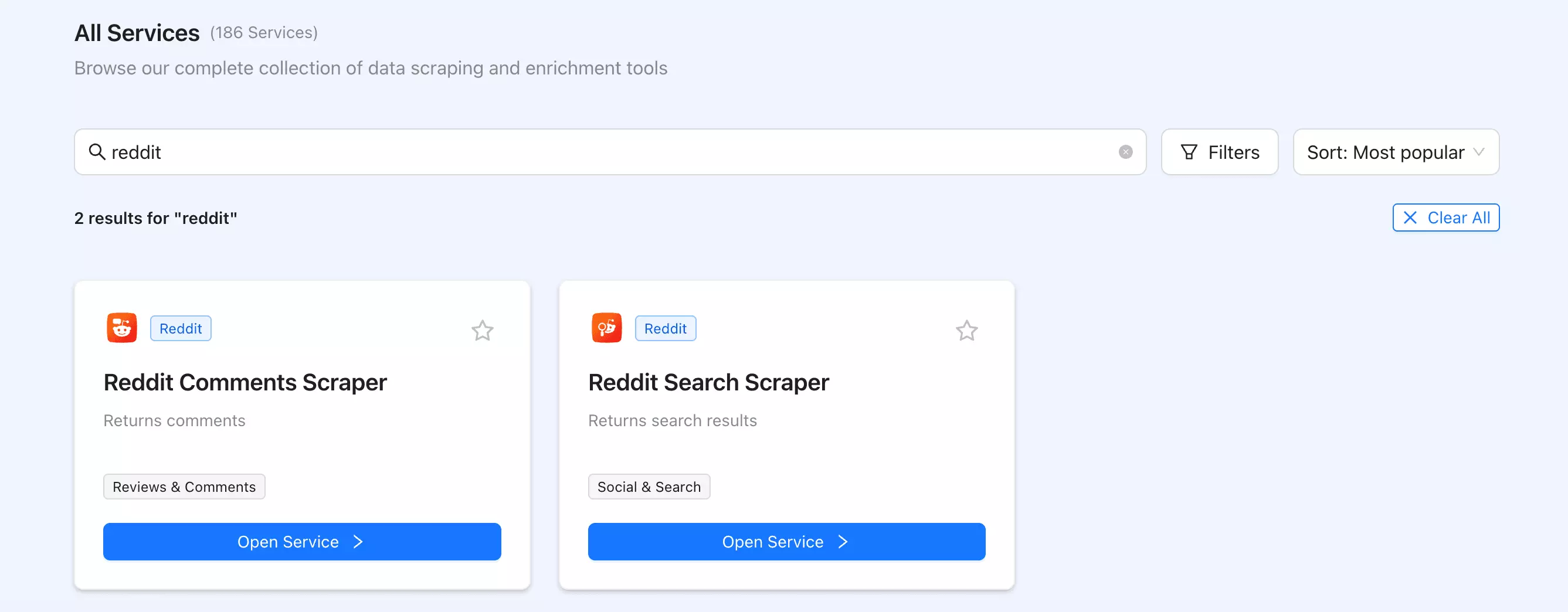
The split is the main problem.
There is no unified Reddit scraper for moving between search results, posts, and comments in one workflow.
You have to choose the correct service first, then switch tools when the job changes. Not fatal, just more tab management than Reddit scraping deserves.
Pricing also makes it difficult to justify against the tools in this comparison.
The first 50 posts are free. After that, pricing starts at $5 per 1,000 posts and drops to $3 per 1,000 posts after 5,000.
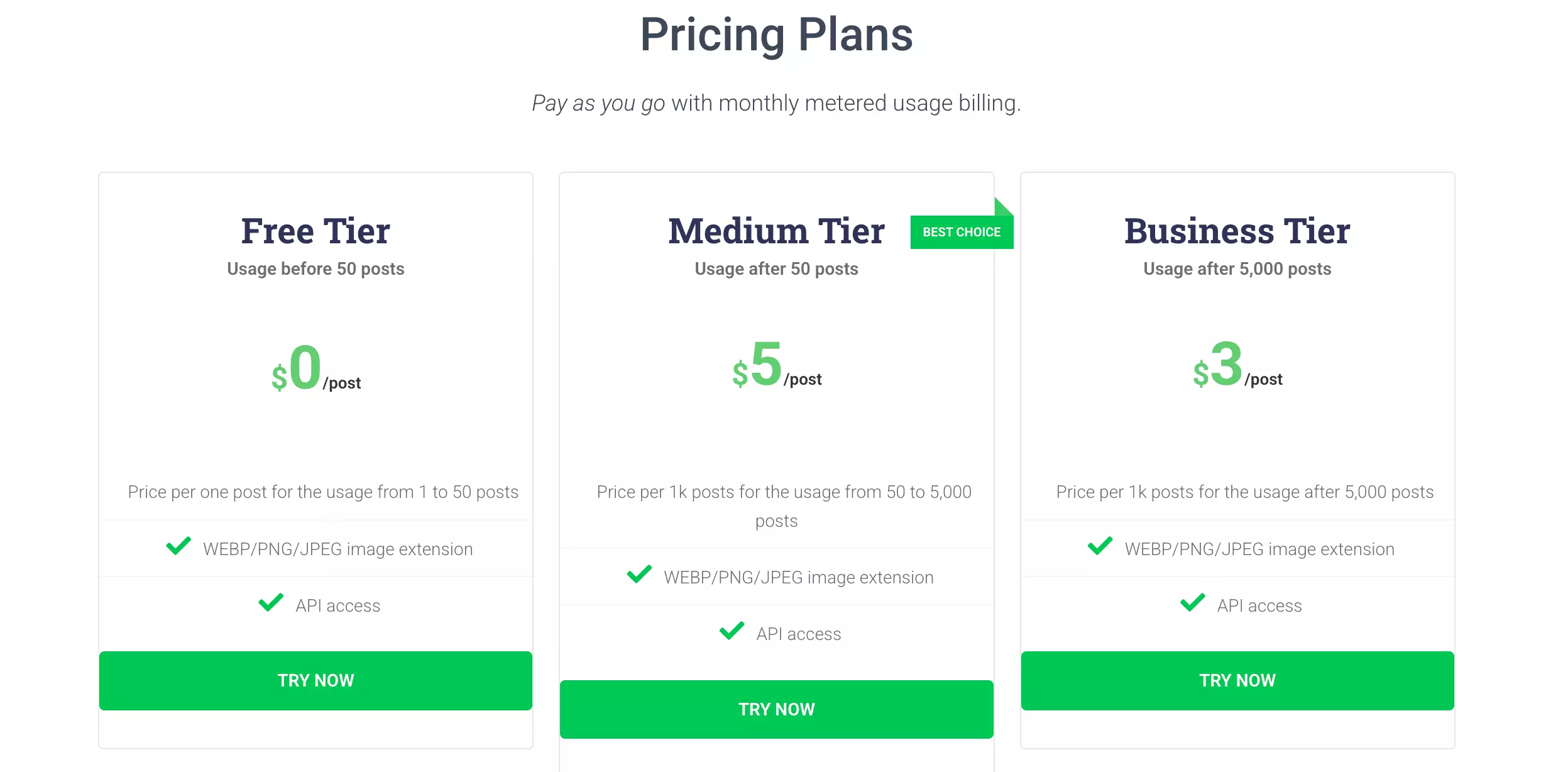
That is expensive at both entry and scale. Apify and lobstr.io start at $2 per 1,000 results, while several API-only options cost considerably less.
Outscraper may work for occasional, narrowly defined jobs. For a broader Reddit collection, the separate tools and higher pricing make it harder to recommend.
FAQ
Which tool returns the most comments per post?
Apify captured 95.5% of Reddit's reported comments across 20 threads and reached a maximum depth of 9.
ScraperAPI ranked second at 84.2%, but its output was flat and did not preserve thread structure.
How do I get nested replies?
ScraperAPI returned flat comments with no depth, no parent ID, and null comment IDs.
Which tool is cheapest per 1,000 results?
ScraperAPI was the cheapest in this test.
SociaVault came next at $0.30 per 1,000 comments on the Starter pack and $0.12 on the Enterprise pack.
Do these tools require a Reddit account?
No.
All five tools scrape public Reddit data without requiring a Reddit login.